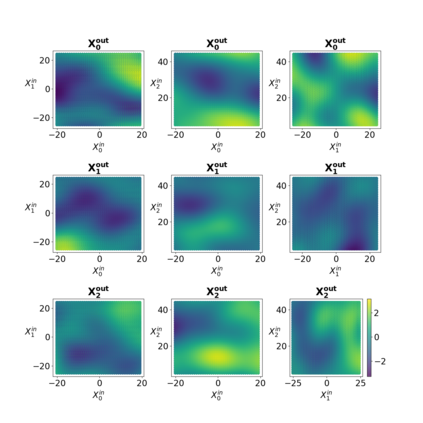
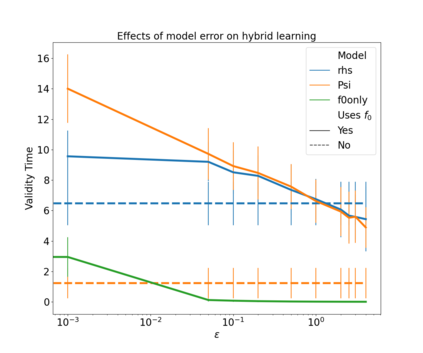
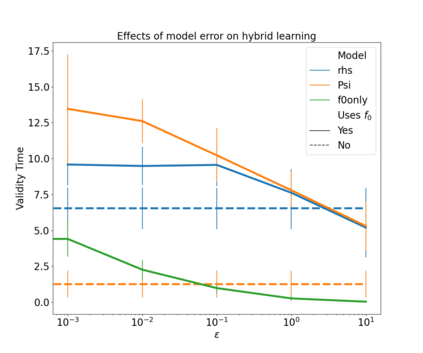
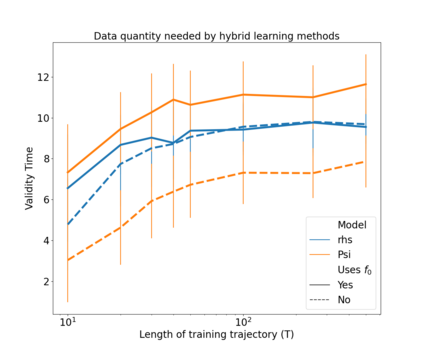
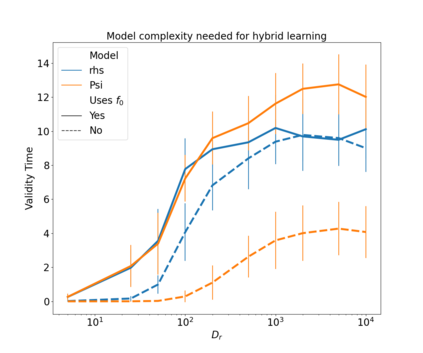
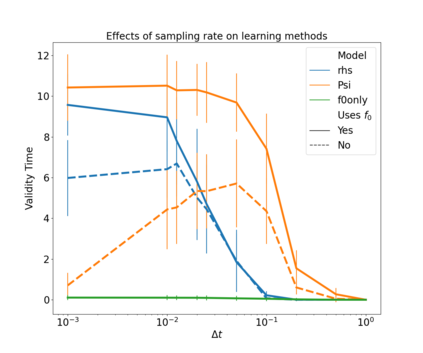
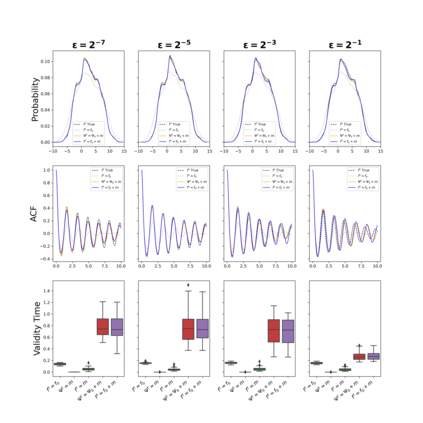
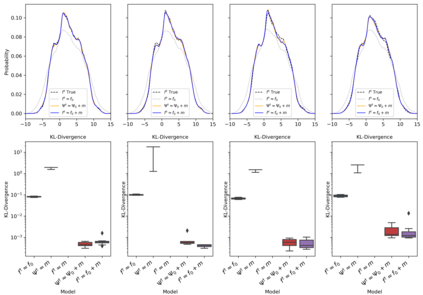
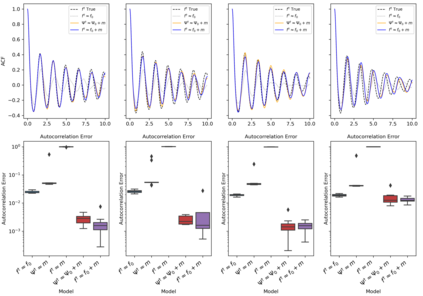
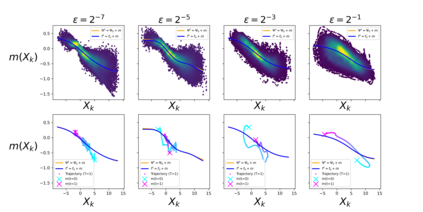
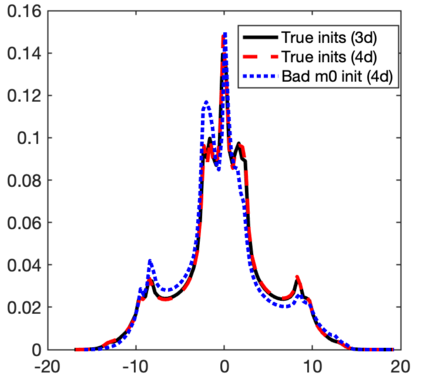
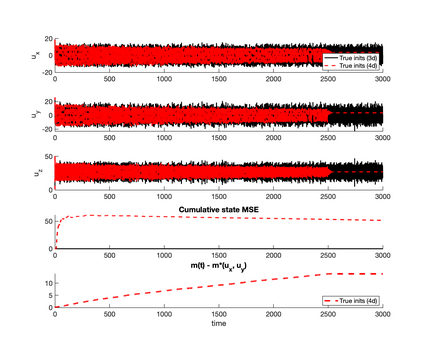
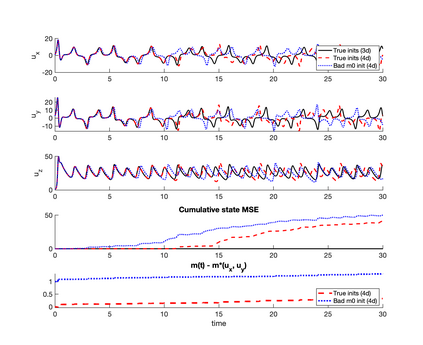
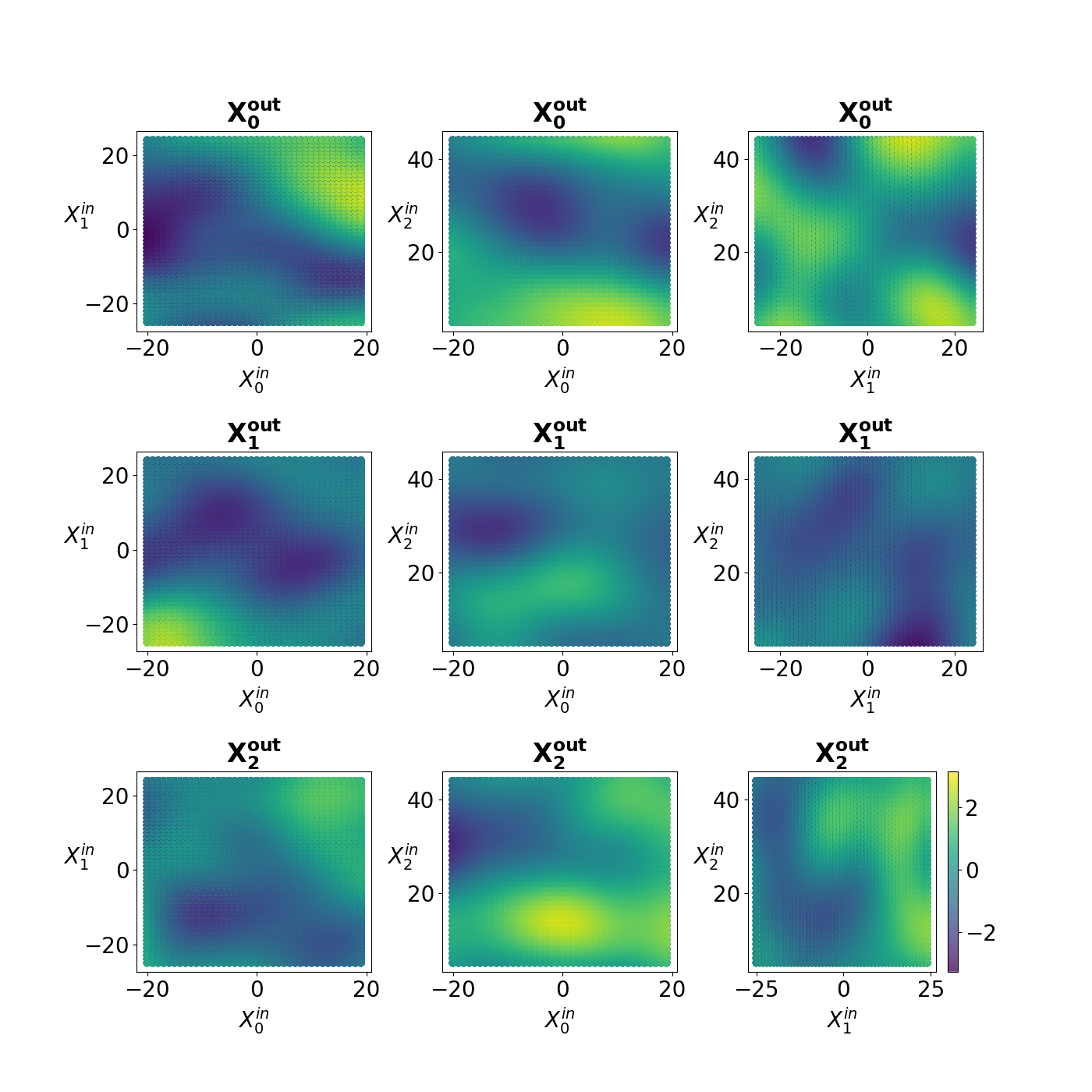
The development of data-informed predictive models for dynamical systems is of widespread interest in many disciplines. We present a unifying framework for blending mechanistic and machine-learning approaches to identify dynamical systems from data. We compare pure data-driven learning with hybrid models which incorporate imperfect domain knowledge. We cast the problem in both continuous- and discrete-time, for problems in which the model error is memoryless and in which it has significant memory, and we compare data-driven and hybrid approaches experimentally. Our formulation is agnostic to the chosen machine learning model. Using Lorenz '63 and Lorenz '96 Multiscale systems, we find that hybrid methods substantially outperform solely data-driven approaches in terms of data hunger, demands for model complexity, and overall predictive performance. We also find that, while a continuous-time framing allows for robustness to irregular sampling and desirable domain-interpretability, a discrete-time framing can provide similar or better predictive performance, especially when data are undersampled and the vector field cannot be resolved. We study model error from the learning theory perspective, defining excess risk and generalization error; for a linear model of the error used to learn about ergodic dynamical systems, both errors are bounded by terms that diminish with the square-root of T. We also illustrate scenarios that benefit from modeling with memory, proving that continuous-time recurrent neural networks (RNNs) can, in principle, learn memory-dependent model error and reconstruct the original system arbitrarily well; numerical results depict challenges in representing memory by this approach. We also connect RNNs to reservoir computing and thereby relate the learning of memory-dependent error to recent work on supervised learning between Banach spaces using random features.
翻译:为动态系统开发以数据为基础的预测模型在许多学科中引起了广泛的兴趣。 我们提出了一个将机械和机器学习方法混合起来的统一框架,以便从数据中找出动态系统。 我们比较纯数据驱动的学习与包含不完善域知识的混合模型。 我们把问题放在连续和离散的时间上,因为模型错误没有记忆性,而且具有重要的内存,我们比较数据驱动和混合方法,实验性地比较。 我们的配方对选择的机器自定义学习模型具有不可知性。 我们使用Lorenz '63和Lorenz '96的多尺度系统,发现混合方法大大超越了从数据饥饿、模型复杂度要求和总体预测性能等方面纯粹由数据驱动的方法。 我们还发现,虽然连续的时间框架可以使模型的取样变得稳健,并且有适当的域内存性解释性,但离散的时间框架可以提供类似或更好的预测性模型性性性能,特别是当数据被低估,并且矢量字段无法解决时。 我们从学习理论的角度研究模型错误, 定义过量风险和一般化的内存错误; 也用直线性工作错误来学习。