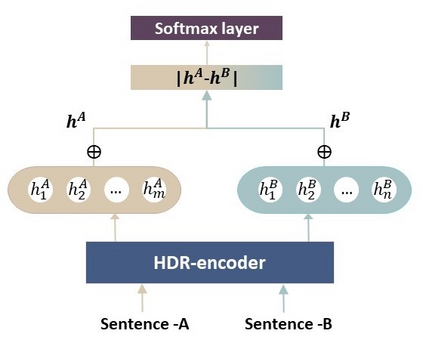
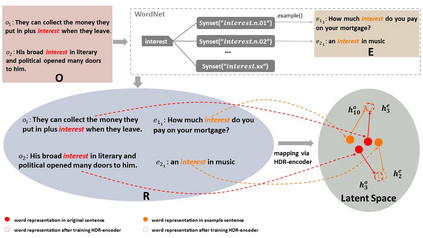
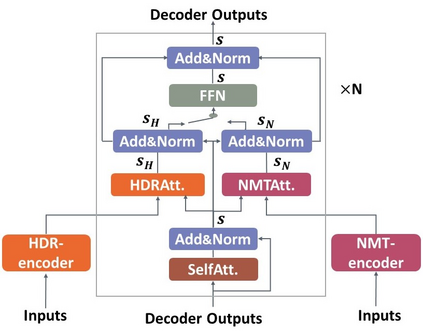
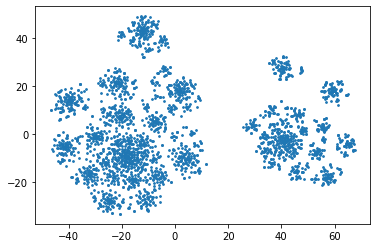
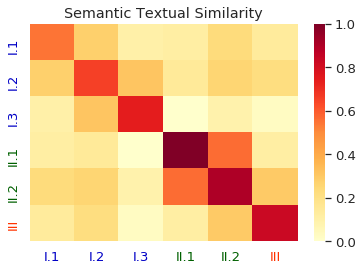
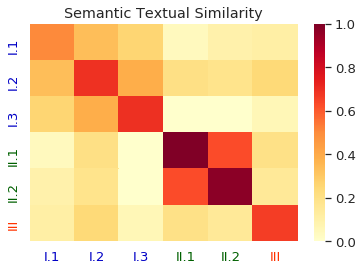
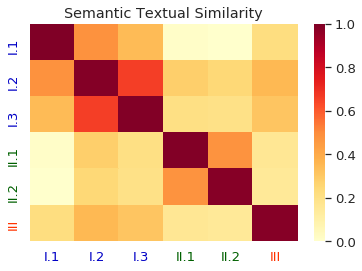
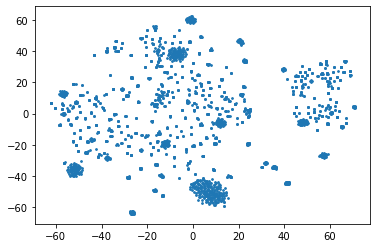
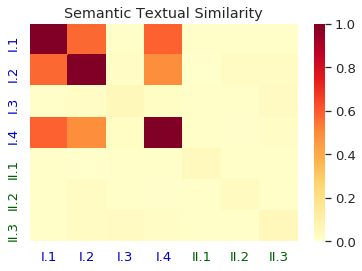
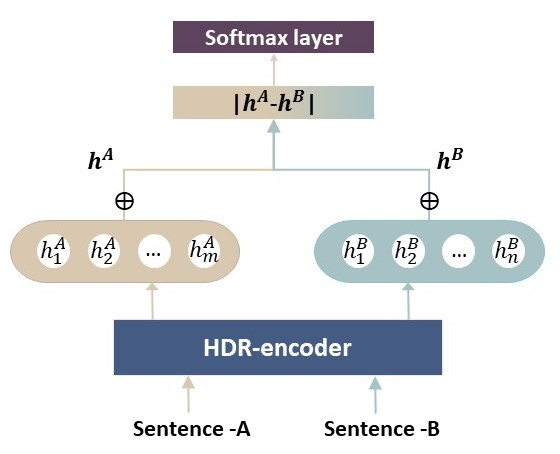
Homographs, words with the same spelling but different meanings, remain challenging in Neural Machine Translation (NMT). While recent works leverage various word embedding approaches to differentiate word sense in NMT, they do not focus on the pivotal components in resolving ambiguities of homographs in NMT: the hidden states of an encoder. In this paper, we propose a novel approach to tackle homographic issues of NMT in the latent space. We first train an encoder (aka "HDR-encoder") to learn universal sentence representations in a natural language inference (NLI) task. We further fine-tune the encoder using homograph-based synset sentences from WordNet, enabling it to learn word-level homographic disambiguation representations (HDR). The pre-trained HDR-encoder is subsequently integrated with a transformer-based NMT in various schemes to improve translation accuracy. Experiments on four translation directions demonstrate the effectiveness of the proposed method in enhancing the performance of NMT systems in the BLEU scores (up to +2.3 compared to a solid baseline). The effects can be verified by other metrics (F1, precision, and recall) of translation accuracy in an additional disambiguation task. Visualization methods like heatmaps, T-SNE and translation examples are also utilized to demonstrate the effects of the proposed method.
翻译:同源词,即拼写相同但含义不同的词,在神经机器翻译(NMT)中仍然具有挑战性。虽然最近一些研究利用各种词嵌入方法来区分NMT中的单词意义,但它们没有关注解决NMT中同源词多义性的关键组成部分:编码器的隐藏状态。在本文中,我们提出了一种新的方法来处理NMT中的同源性问题,即在潜在空间中。我们首先训练一个编码器(即“HDR-编码器”),以在自然语言推理(NLI)任务中学习通用的句子表示形式。我们进一步使用WordNet中以同源词为基础的同义句子来微调编码器,使其学习单词级的同源词消歧表示(HDR)。预先训练的HDR-编码器随后与基于transformer的NMT集成在各种方案中,以提高翻译的准确性。在四个翻译方向上的实验证明了所提出的方法在提高NMT系统BLEU分数的有效性(与坚实的基线相比,最高达+2.3)。此外,在附加的消歧任务中,也可以通过其他翻译准确性的指标(F1、精确度和召回率)验证这些效果。还利用热图、T-SNE和翻译示例等可视化方法来展示所提出的方法的效果。