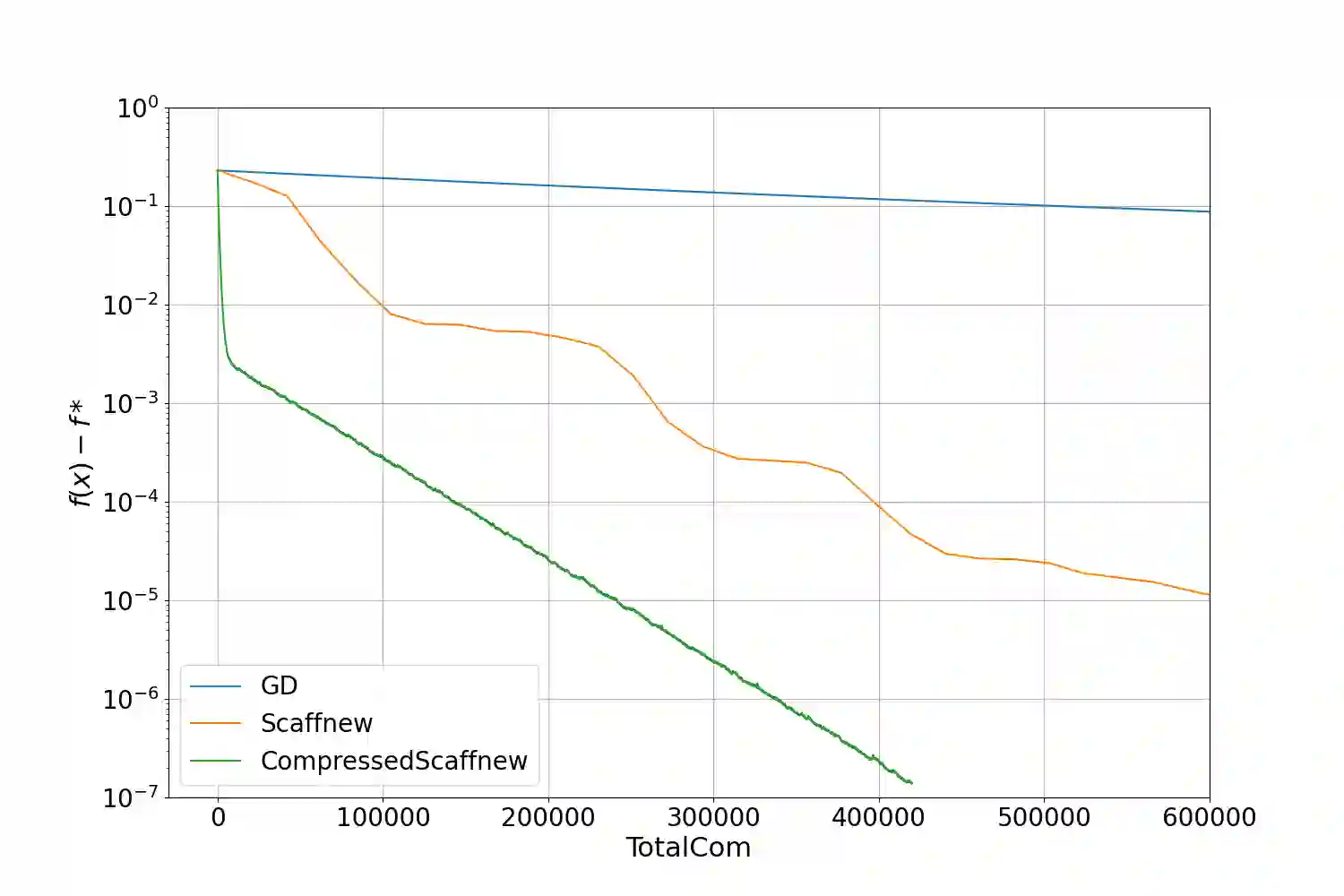
In the modern paradigm of federated learning, a large number of users are involved in a global learning task, in a collaborative way. They alternate local computations and two-way communication with a distant orchestrating server. Communication, which can be slow and costly, is the main bottleneck in this setting. To reduce the communication load and therefore accelerate distributed gradient descent, two strategies are popular: 1) communicate less frequently; that is, perform several iterations of local computations between the communication rounds; and 2) communicate compressed information instead of full-dimensional vectors. In this paper, we propose the first algorithm for distributed optimization and federated learning, which harnesses these two strategies jointly and converges linearly to an exact solution, with a doubly accelerated rate: our algorithm benefits from the two acceleration mechanisms provided by local training and compression, namely a better dependency on the condition number of the functions and on the dimension of the model, respectively.
翻译:在联邦式学习的现代模式中,大量用户以协作方式参与全球学习任务,与遥远的管弦服务器互换本地计算和双向通信。通信可能缓慢而昂贵,是这一环境下的主要瓶颈。为了减少通信负荷,从而加快分布梯度下降速度,有两个战略很受欢迎:(1) 通信频率较低;在通信周期之间进行若干次本地计算;(2) 通信压缩信息,而不是全维矢量。在本文中,我们提出了分配优化和联动学习的第一个算法,它联合利用这两个战略,并直线地将这两个战略汇合到一个精确的解决方案,同时加倍加速速度:我们算法从当地培训和压缩提供的两种加速机制中获益,即分别更多地依赖功能和模型层面的条件。