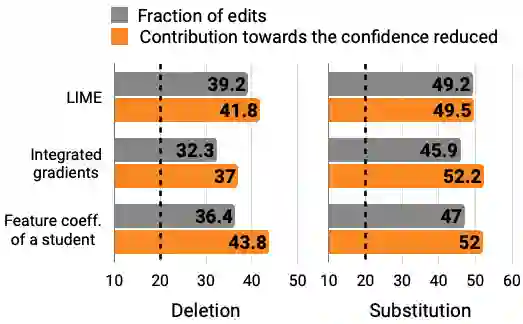
In attempts to "explain" predictions of machine learning models, researchers have proposed hundreds of techniques for attributing predictions to features that are deemed important. While these attributions are often claimed to hold the potential to improve human "understanding" of the models, surprisingly little work explicitly evaluates progress towards this aspiration. In this paper, we conduct a crowdsourcing study, where participants interact with deception detection models that have been trained to distinguish between genuine and fake hotel reviews. They are challenged both to simulate the model on fresh reviews, and to edit reviews with the goal of lowering the probability of the originally predicted class. Successful manipulations would lead to an adversarial example. During the training (but not the test) phase, input spans are highlighted to communicate salience. Through our evaluation, we observe that for a linear bag-of-words model, participants with access to the feature coefficients during training are able to cause a larger reduction in model confidence in the testing phase when compared to the no-explanation control. For the BERT-based classifier, popular local explanations do not improve their ability to reduce the model confidence over the no-explanation case. Remarkably, when the explanation for the BERT model is given by the (global) attributions of a linear model trained to imitate the BERT model, people can effectively manipulate the model.
翻译:在对机器学习模型的“解释”预测中,研究人员提出了数百种技术,将预测归结为被认为重要的特征;虽然这些属性往往声称具有提高模型人类“理解”的潜力,但令人惊讶的是,很少有工作明确评价实现这一愿望的进展;在本文件中,我们开展了一项众包研究,参与者与为区分真实和假酒店审查而受过训练的欺骗检测模型相互作用;他们面临的挑战是模拟新审查模型,并编辑审查,目的是降低最初预测的等级的概率;成功的操纵将引出一个对抗性的例子;在培训(但不是测试)阶段,强调投入的跨度以传达显著的特征;通过我们的评估,我们观察到,对于线性词包模型,在培训期间能够使用特征系数的参与者,与不规划控制相比,在测试阶段能够更大程度降低模型信任度;对于基于BERT的分类员,流行的地方解释不会提高他们降低模型对模型信任度的能力;在模型(而不是测试)阶段,我们观察到,在经过培训的BERBRAD模型中,能够有效地解释。