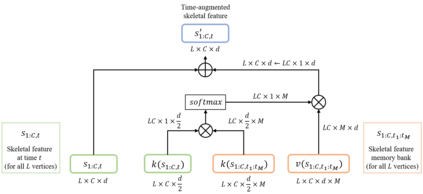
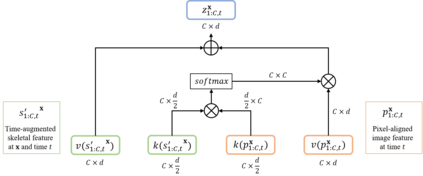
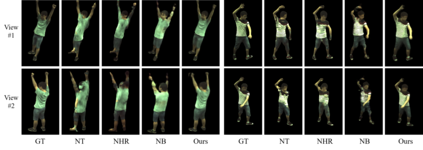In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.
翻译:在本文中,我们的目标是利用稀有的多视图相机,将人类任意表演的自由视野视频综合在一起。最近,一些作品通过学习人特有的神经光亮场(NERF)来解决这一问题,以捕捉特定人类的外貌。同时,还提议使用像素结盟特征,将光光光场推广到任意的新的场景和物体。然而,由于人体各部分的屏蔽和动态表达方式十分繁杂,因此对人体采取这种概括性做法具有很大挑战性。为了解决这一问题,我们提议采用神经人类表演者,这是一种新颖的方法,在强力捕捉的参数人体模型基础上学习一般可实现的神经光亮场。具体地说,我们首先引入一个时间变异器,根据骨骼体运动随时移动来跟踪视觉特征。此外,还提议采用多视角变异器,在时间被利用的特征和像素调的特征之间进行交叉保护,以便整合从多个视图中观测的结果。在ZJU-Mochap/AISTSMAD 和AISF 数据设置方法上进行实验。