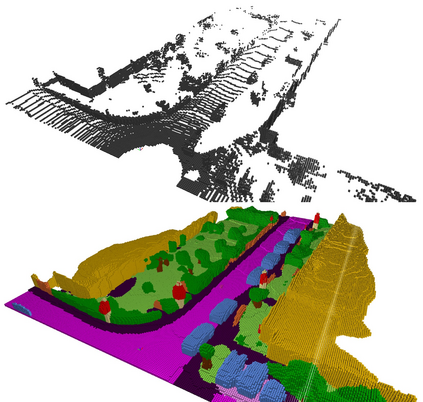
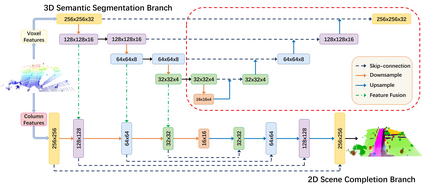
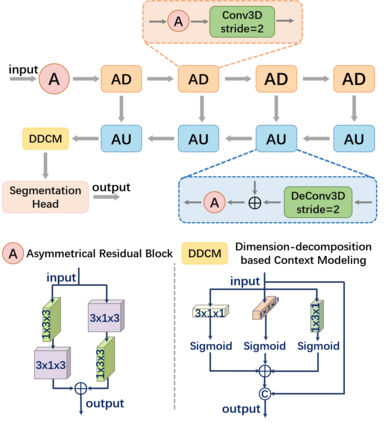
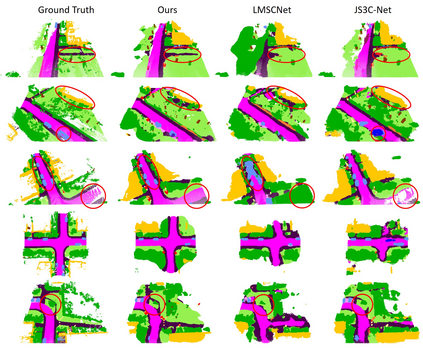
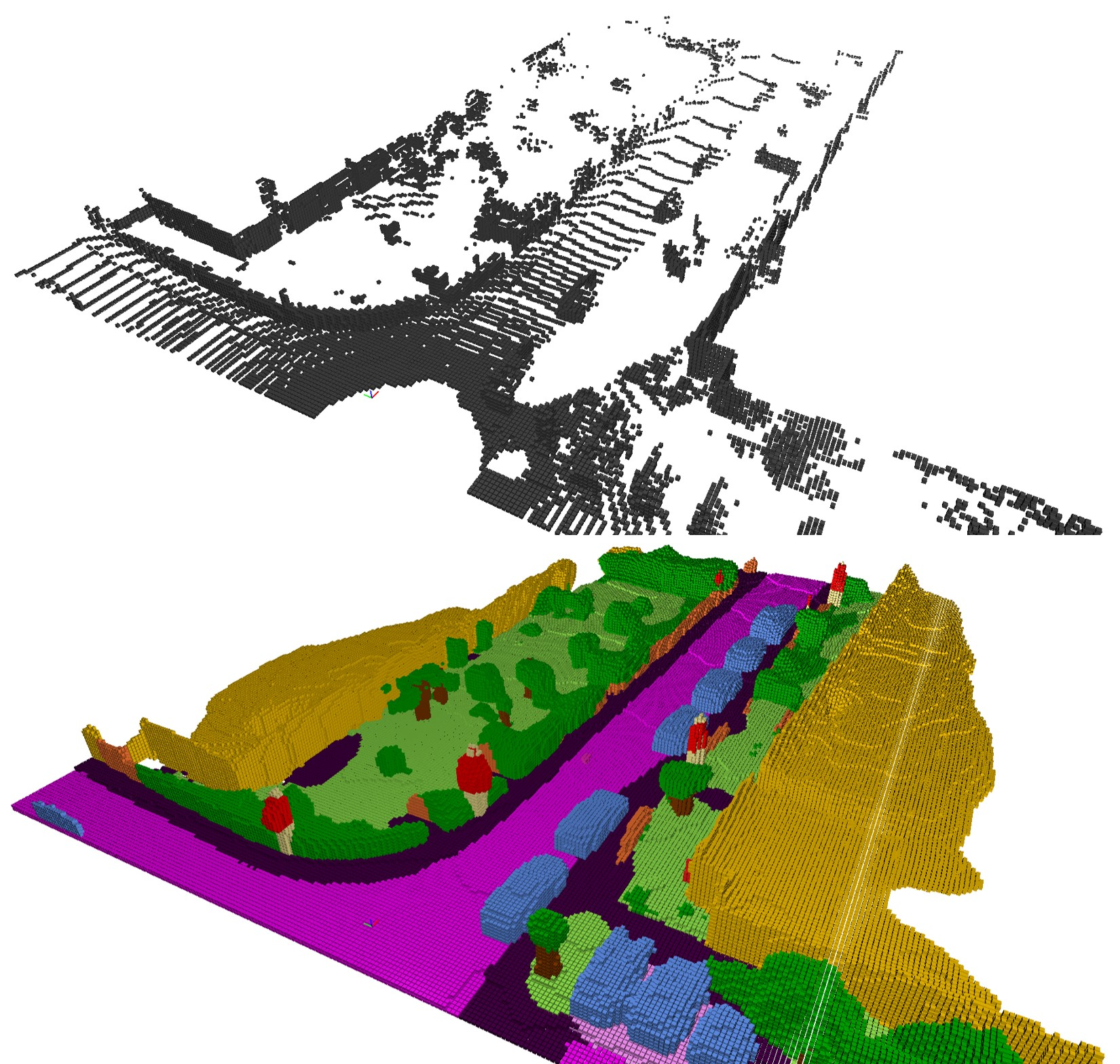
Outdoor scene completion is a challenging issue in 3D scene understanding, which plays an important role in intelligent robotics and autonomous driving. Due to the sparsity of LiDAR acquisition, it is far more complex for 3D scene completion and semantic segmentation. Since semantic features can provide constraints and semantic priors for completion tasks, the relationship between them is worth exploring. Therefore, we propose an end-to-end semantic segmentation-assisted scene completion network, including a 2D completion branch and a 3D semantic segmentation branch. Specifically, the network takes a raw point cloud as input, and merges the features from the segmentation branch into the completion branch hierarchically to provide semantic information. By adopting BEV representation and 3D sparse convolution, we can benefit from the lower operand while maintaining effective expression. Besides, the decoder of the segmentation branch is used as an auxiliary, which can be discarded in the inference stage to save computational consumption. Extensive experiments demonstrate that our method achieves competitive performance on SemanticKITTI dataset with low latency. Code and models will be released at https://github.com/jokester-zzz/SSA-SC.
翻译:在3D 场景理解中,场外完成是一个具有挑战性的问题,这在智能机器人和自主驱动方面起着重要作用。由于LiDAR获取过程的广度,对于3D场景完成和语义分解来说,场外完成是一个复杂得多的问题。由于语义特征可以提供完成任务的制约和语义前缀,因此它们之间的关系值得探讨。因此,我们提议一个端到端的语义分解辅助场景完成网络,包括一个2D完成分支和3D语义分解分支。具体地说,网络将原始点云作为输入,并将分解分支的特征按等级合并到完成分支,以提供语义信息。通过采用 BEV 代表和 3D 分散的拼凑,我们可以在保持有效表达的同时从较低的操作中受益。此外,分解分支的解码作为辅助工具,可以在推断阶段丢弃,以节省计算消耗。广泛的实验表明,我们的方法在低纬度的SmantiKITTI数据设置上取得了竞争性的性能。代码和模型将在 http://sgis-SAS/SSASS/sgi/SAL/SAL/SASY/SAL/SAL/SAL/SAL/SAL/SAL/SAL/SAI/SALT/SAL)。