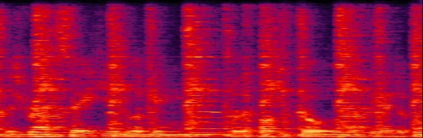
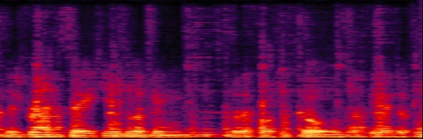
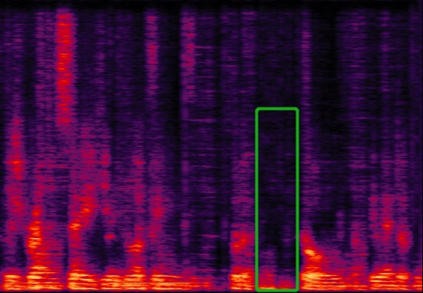
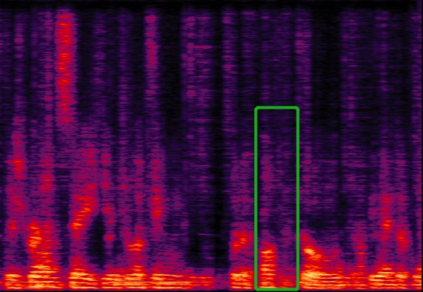
We propose a multi-channel speech enhancement approach with a novel two-level feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion level, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second level of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.
翻译:我们提出多通道语音增强办法,采用新型的双级特征聚合法和多任务学习模式中经过预先训练的多任务学习模式的声学模型。 在第一个聚合级别上,时间-域和频率-域特性是分开分离的。在时间域中,多通道共变和(MCS)和循环共变差异(ICDs)特性是计算出来的,然后与2层相融合。在频率域中,原频道和超导波形成型超级波段的原动力光谱(LPS)特性与另一个2层相融合。要充分整合多频道演讲的丰富信息,即时间-频域特性和阵列的几何度测量,我们在第二层混合中应用第三个2层电动层,以获得最后的革命特性。此外,我们提议使用一个固定的清洁声学模型,在零端至端无顶层的最大相互信息标准下,以实施强化的输出,另一个2D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D-D---D-D-D-D-D-D--D---------------------------------------------------------------------------------------------------------