强化学习在京东广告序列推荐中的应用

分享嘉宾:赵鑫博士 京东 算法工程师
编辑整理:娄学政 小米
出品平台:DataFunTalk
导读:互联网推荐广告的排序,关键在于对流量价值的预估,其中最重要的一部分是对点击率的预估。为了提高广告的变现效率,核心的问题是如何提高广告的预估精度。同一个广告,在上下文不一样的情况下,点击率是不同的,点击率不只是受用户和广告的影响,还受上下文的影响,所以如果只是从召回到粗排再到精排做一个pointwise的预估,对于广告的CTR预估是不准的,需要对整个广告序列整体考量。
本文的介绍将围绕下面四点展开:
推荐广告排序技术选型介绍
Context-aware CTR重预估
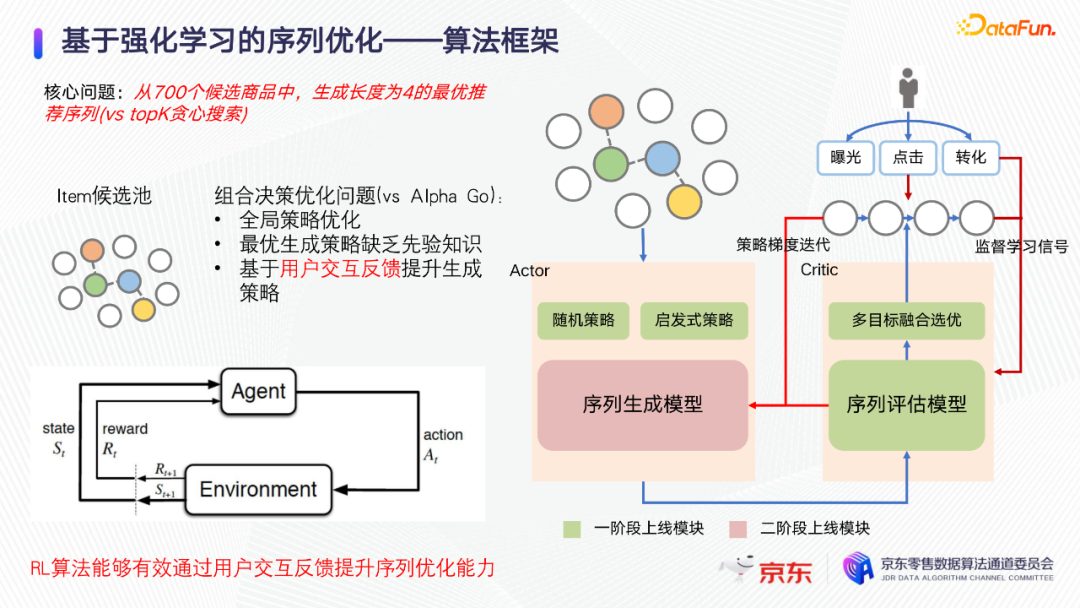
基于强化学习的序列优化
会话级别广告拍卖机制优化
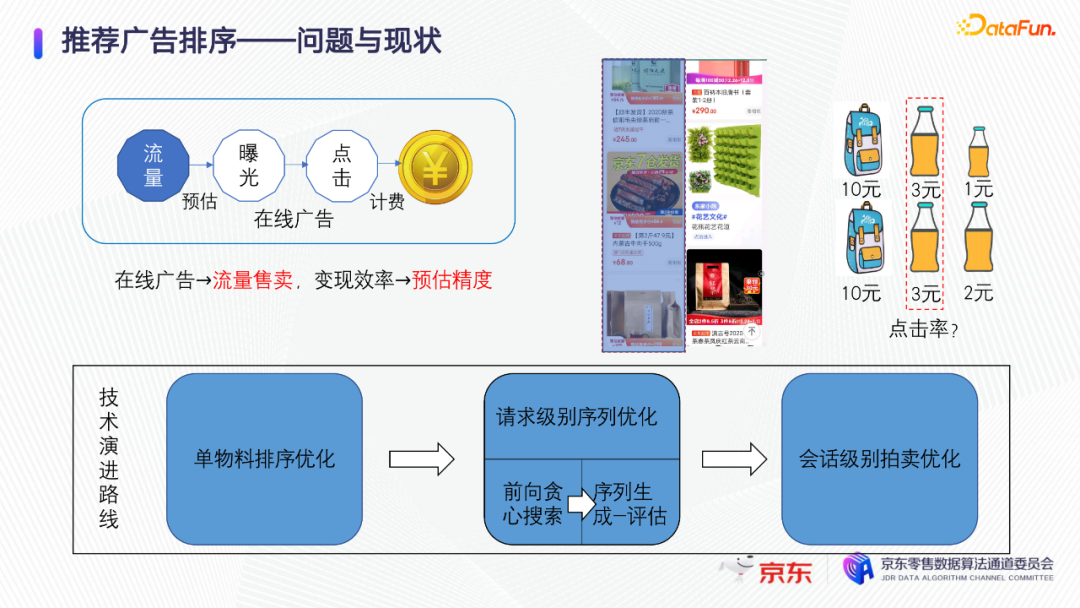
为了提高变现效率,我们的技术演进路线是从最初的对单物料的排序优化,到请求级别进行序列的整体优化,最后是会话级别的广告拍卖机制优化。其中请求级别的序列整体优化,经历了从前向贪心搜索到序列生成和评估的演进过程。
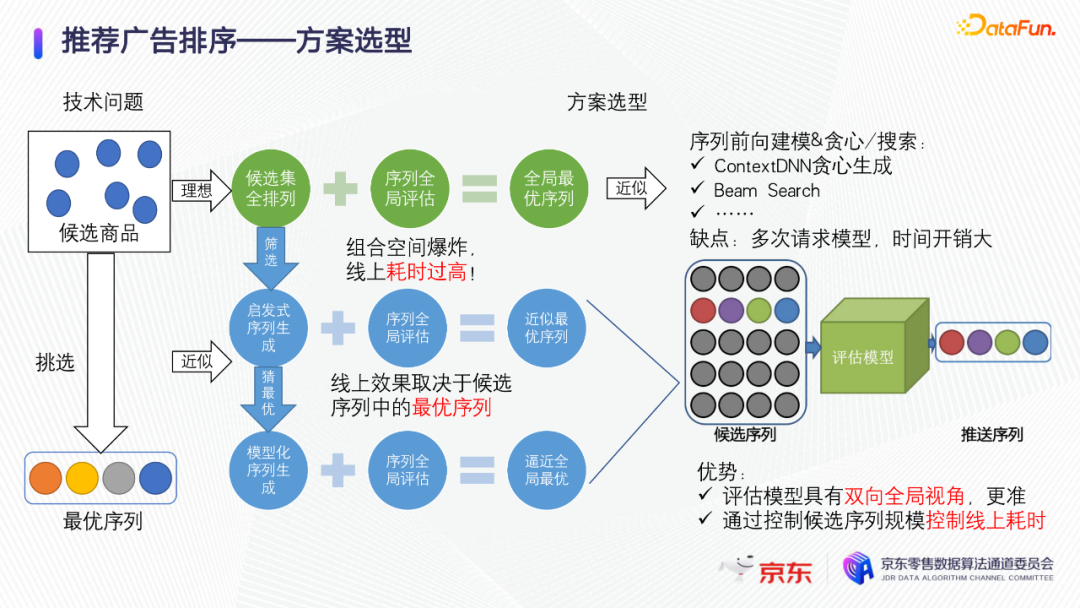
对序列进行优化,就是要对候选集的排列空间进行优化。理想的状态下是对候选集做全排列,用全局的序列评估模型,把所有的排列方式都评估出一个打分,选出全局最优序列。但这种方式难以实现,因为序列的组合空间是爆炸的,线上耗时高导致框架无法落地,所以考虑如下两种思路。
第一种是做序列的前向贪心搜索,不考虑序列的整体优化,每一次只是根据上一个item选择了什么,把它作为上文信息,然后贪心的逐个选取当前位置最有价值的一个物料进行排序。可以利用类似beam search的贪心搜索。这种前向贪心建模方式的缺点在于,决策过程和请求模型的过程是分开的,每做一次决策,就需要请求一次模型,线上就会反复的进行模型的调用,时间开销大。
第二种优化的思路,是对整个候选集的全排列做筛选,筛选出一些很有可能成为最终比较优的候选序列集合。候选序列集合做一个序列的全局评估,选出一个近似最优的序列。第一步,如何筛选?可以使用启发式的人工规则,或者基于业务逻辑的启发式生成方法,获取候选序列集合。进一步可以做一个模型化的序列生成。优势在于,序列的全局评估模型可以看到上下文信息,对CTR的预估更准确。可以先生成序列,再对所有序列一次性预估,控制线上耗时。如下图表,对上面优化方案的耗时进行了对比。
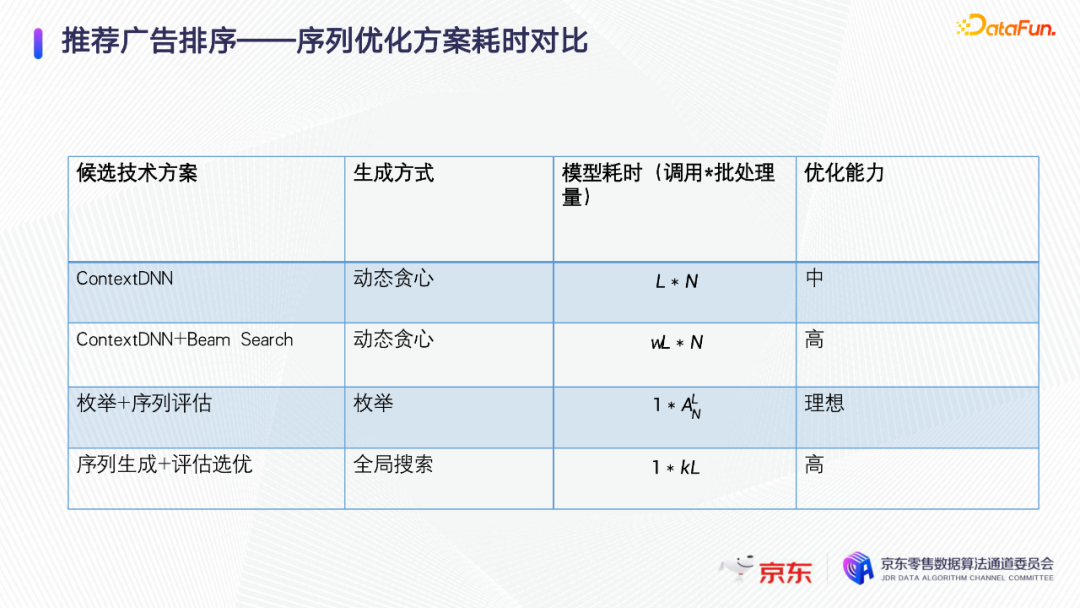
第一种是用上文作为context或者和会话里面的其他序列的上文都作为context,逐个的贪心来选取,这样模型的耗时是序列长度L乘以候选集的大小N。第二种用context DNN + beam search的方法,保存贪心搜索过程中的top 部分,因为探索了额外的分支,所以耗时变成W倍,如果W选择足够大,可以接近理想的优化能力。第三种是把所有的排列都枚举,然后加上一个序列评估,这是理想的方式,但复杂度极高。第四种是序列生成加上评估选优,近似全局搜索,只进行一次模型调用,优化能力比较强,兼顾了线上性能和优化能力。
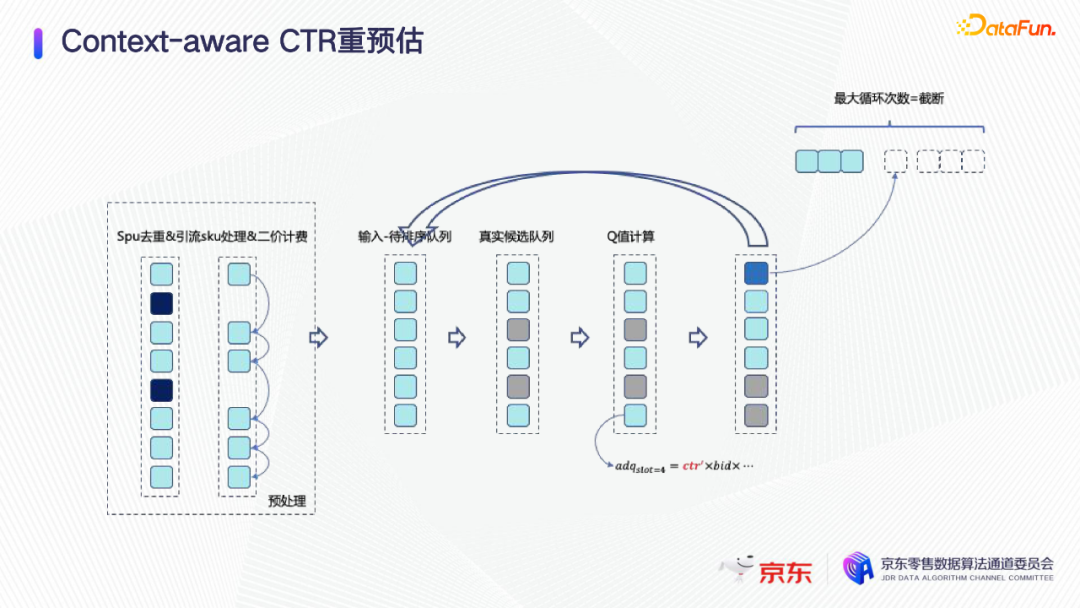
Context-aware预估,第一步就是贪心的前向搜索,如图,每放一个sku,就把它当成上文,再重新预估一次,再选第二个、第三个sku。这样训练Context-aware CTR模型,也是一个只有上文信息的模型,跟普通CTR模型没有太大差别。
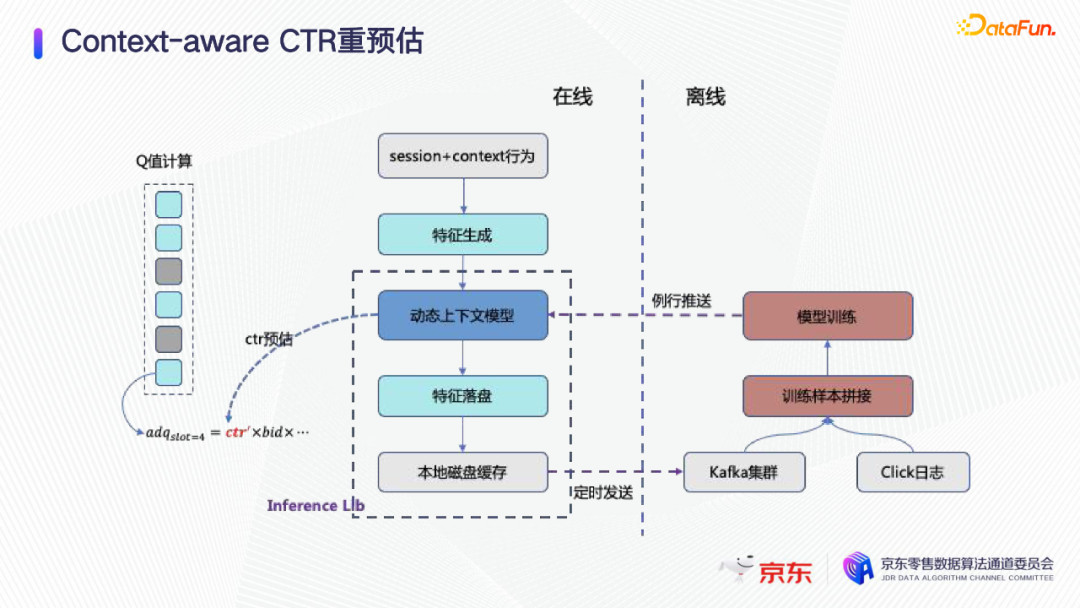
第二个思路,是序列生成加序列选优的集成框架。有两个问题需要解决:
第一个问题是如何对序列的样本进行选优和正确的评估,即如何得到序列评估模型。没有上线序列的优化框架之前,整个线上排序系统都是一个ranking base的排序系统,所有的序列的组成都是按照广告的Q值得分排序的。如果用这样的训练样本,模型无法感知顺序打乱之后会怎么样。
第二个问题是序列生成是怎么样的,我们只能知道某一些情况可能是好的序列,但是到底什么是最好的序列,无从判断。
因此设计了两步上线流程。先解决相对比较简单的序列评估问题。Ranking base的序列和打乱顺序的序列是有差别的。但基于Ranking方式生成的样本训练对的模型虽然是有偏的,我们也认为是可以接受的。先用Ranking Base方法生成的样本去徐莲序列评估模型,然后在线上使用这个模型对样本做小流量序列选优,配合随机的策略和启发式序列生成策略,这样线上的一部分流量生成一些打乱顺序的样本,这样的小流量的样本落盘下来,再去retrain序列评估模型。迭代一段时间之后,就把随机策略叠加启发式策略,跟序列评估模型配合上线。
第二步是解决如何让Actor自学习的问题,目标是让生成模型倾向于生成出一些更好的序列被评估模型选出来。序列生成模型要做的是模拟评估模型选取的序列的样子。第二阶段主要是上线了序列生成模型和蒙特卡洛采样序列生成算法。
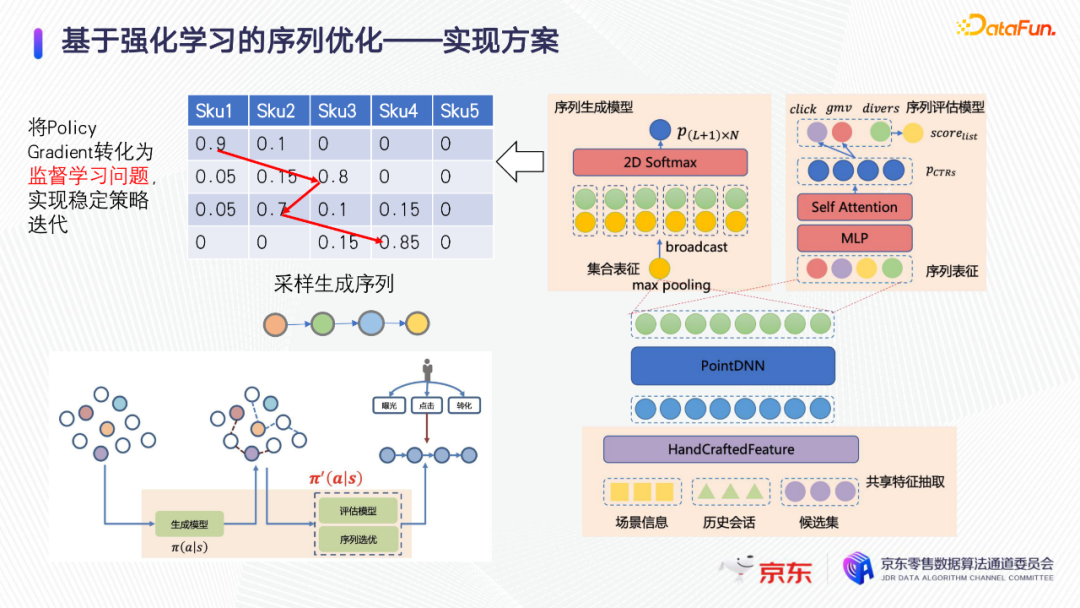
序列生成和评估模型结构设计如上图右半部分,底层是特征抽取,往上是PointDNN结构,Point DNN是对每一个item单独抽取特征,把这些稀疏的embedding转化为dense feature,得到绿色的item的特征向量,然后在序列评估模型里,把序列对应的向量抽取出来组成一个序列,上面进行序列的attention操作,将最相关的特征高亮出来。最后,输出预估序列里每一个item的预估点击率,item的预估点击率会和它的出价、多样性等业务指标融合成一个最终的得分。
序列生成模型建模过程如下。首先把整个候选集的集合作为生成模型的输入,把所有候选集中item的特征做max pooling处理后的特征向量作为候选集合的特征向量,去和每一个item的特征向量拼接起来,得到一个新的特征。新的特征去经过几层DNN,最后得到一个表。如图举例,假设一共有五个item,序列长度是四。如上图左上的表格,按行来看表示的是每一个item出现在当前这个位置的概率,按列来看表示的是item出现在不同位置的概率。模型训练使用2D softmax的交叉熵loss。如果一个item在候选集里被选中了,并且是出现在第一个位置,它的第一个位置的label就是1。如图,SKU1在第一个位置label是1,SKU2在第三个位置label是1。训练完成的模型在线上预测过程中预测采样频率,用一个受控的temperature参数来控制这个采样频率。按照这个表去生成序列,逐个位置去采样多次生成多个序列。举例来说,生成第一个位置需要的SKU,类似扔一个骰子,如果小于0.9,SKU1被选中,如果是0.9到1,SKU2被选中。第二个位置去除第一个位置已经出现过的SKU,进行重新归一化,再采样一次,这样可以生成多个候选序列。再把这些候选序列与启发式的或者随机生成的序列融合起来,变成一个序列的候选集,统一交给序列的评估模型去评估,选出一个最好的序列。
强化学习解决的是在策略空间做探索以得到新的更好的策略的问题。序列生成和序列评估是互相迭代的,因为如果序列生成不是一个好的模型,序列评估就只能在一个差的候选序列集合里面选择。如果切换其他的模式上进行探索,序列评估模型可能会在新的模式下不准,有可能把错误的东西推给用户。序列评估模型在探索模式下变好了,序列生成模型就会学习到新的生成策略,会在一个序列评估模型不准的地方去学习,直到序列评估模型模型变准为止。所以这是一个交互迭代的过程。模型上线过程有三个指标用来监控:
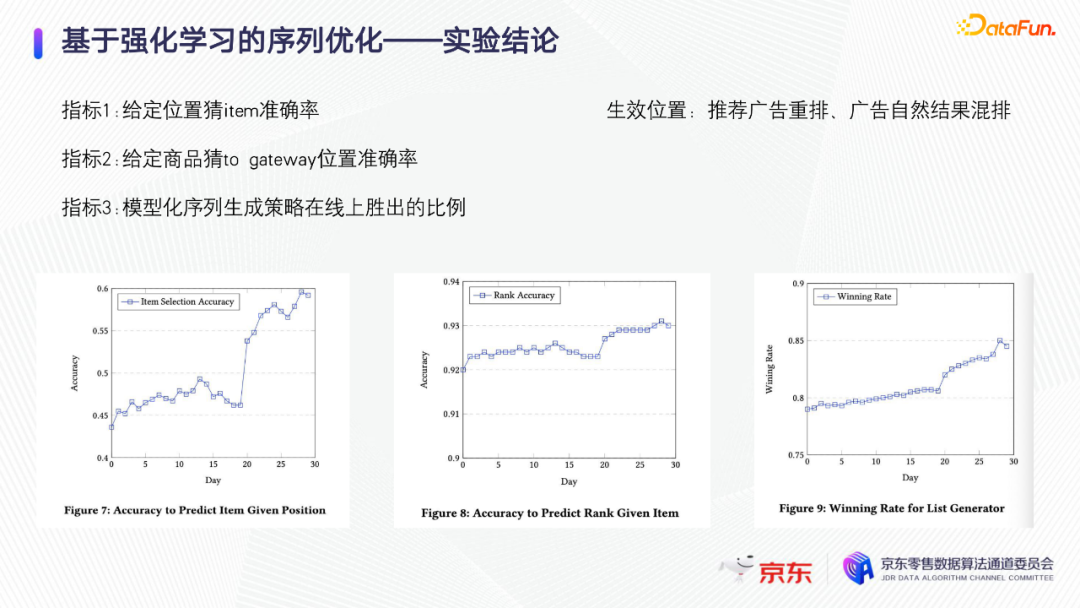
给定一个位置,猜item被选择的准确率;
给定一个商品,猜能不能出现在这个to gateway 某一位置的准确率,这对应于图表里边的按行求accuracy和按列求accuracy;
模型化的序列生成策略在线上胜出的比例。类似召回评估里,某一路召回能够在下游出现的比例。
线上监控可以看到,按天来观察,这些指标都在上涨,可以让生成和评估模型变得越来越准。这个算法有两个生效位置,一是推荐广告内部的重排,二是广告和自然推荐的混排。
基于序列推荐和评估选优的机制,可以解决通用推荐问题,但是在广告业务里有一定的问题。受广告竞价机制的限制,我们只能让广告先计费,然后再重排。广告主允许平台收此费用,应该是让sku展现在当前这个位置需要花的钱,确定了费用之后又改变位置不太合理。计费机制既不满足广义二价计费,又不激励相容。而且,序列生成加评估选优的机制,只能量化请求内的若干个SKU排列的价值,没有办法量化会话内部的长期价值,所以我们需要实现会话级别的广告拍卖机制,优化此问题。
拍卖机制有几个设计原则:
激励相容,鼓励竞价者说真话,要求它能够展现的概率和它的bid是单调的;
对平台的这些多目标以及平台的长期价值敏感;
排序和计费机制比较容易实现。
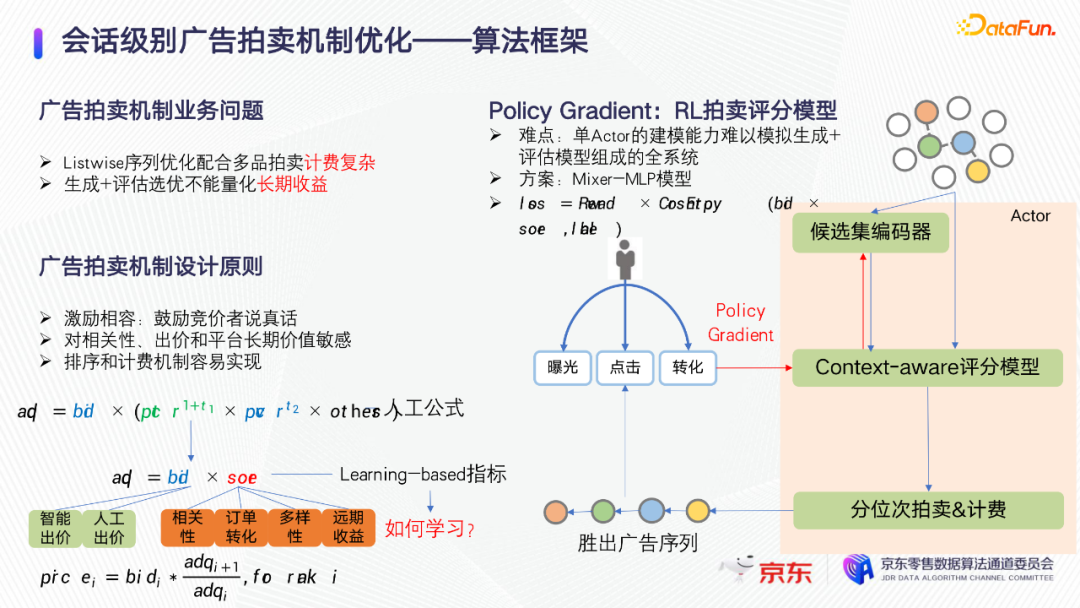
京东广告的精排公式如图所示。我们希望将目标优化成learning base的指标,一方面它和Bid成正比,一方面它和平台融合的learning base的综合score成正比。这样用一个learning base的融合广告分可以做二价计费。这个算法和前文提到的序列评估选优的算法框架不同点在于它是一个单actor强化学习算法。候选集先输入一个候选集编码器,然后被模型评分。针对多个广告坑位的拍卖问题,这里做了一些思考,因为推荐广告本来就是一个多广告坑位的一个拍卖问题。我们使用分位次拍卖的方式解决多坑位的拍卖问题。按照分位次拍卖和计费的结果,得出一个新的胜出广告序列,然后把这个序列展现出来,让用户做出一些反馈,用户的反馈可以通过计算会话内部的长期收益,用policy gradient的方式来反馈到评分模型里。
这里有2个难点:
第一个难点是,在序列评估加选优的框架上面迭代新的会话级别广告拍卖机制,从推荐效率的角度上,单actor模型建模能力和生成模型加评估模型组合的全系统相比很难打平。
第二个难点是,如何融合业务先验知识。
解决第一个难点,这里的方案把actor做成更大的模型,使用CV领域的模型mixer MLP,它很适合集合建模。第二个难点的解决方案是,把业务reward以某种方式融合到loss function里。分位次的序列采样和分位次的广告拍卖,有非常大的共同之处。分位次序列采样是对每一个位次有一个采样概率,分位次的广告拍卖,是对每个位次给出每一个竞争商品的数值得分。
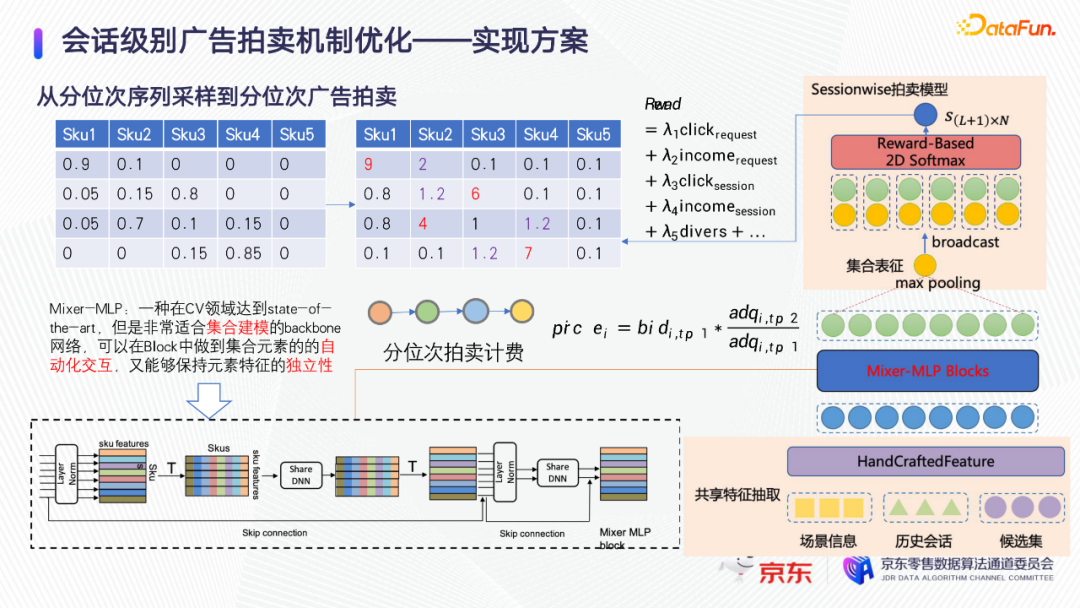
这里类似序列生成模型的结构,只是它的backbone网络变成更大更复杂的mixer MLP,模型的输出是一个像右边蓝色的表格,对于每一个SKU在每一个位置有一个得分,模型训练的reward融合了当前广告收入,远期广告收入,推荐的多样性,以及所有要考虑的业务指标。广告拍卖是一个二价计费过程,但是二价计费过程并不是每一个SKU都只有一个得分,并根据此打分做排序。举例说明,第一个位置应该胜出哪一个SKU。如图,第一个位置应该胜出得分等于9的SKU1,它计费应该是Sku1的bid*2÷9,因为第二名的SKU的得分是2。第二个位置的拍卖不取决于第一行,而是第二行,应该胜出SKU3,它的计费是SKU3的bid*1.2÷6。
每一个位置只根据模型在这个位置的打分来做排序和计费。因为每个sku在每一个位置的得分是不同的,所以可以解决分位次拍卖的问题。此外,Mixer MLP适合集合建模的原因是,它可以对每一个item都有一个特征抽取,在每一个block中对每一个item的dense feature做特征交互,因此它既能把集合的共有的特征建模到item当中去,又能保持每一个item的独立性,让每一个item能够计算出自己的得分。模型训练过程与序列生成模型基本一致,用一个2D的softmax的loss function来训练,只是把点击,广告收入等一系列业务指标融合进来,变成一个reward base的softmax。
Q:在京东的广告重排工作,和业界其他的一些rerank的工作有什么关联,场景上的主要差异是什么?
A:业界阿里和百度有公开的rerank工作,原理是类似的,京东的方案是一种可以平滑上线的工程化方案,这是一个通用的序列推荐解决方案。场景上的差异不大。
Q:在京东内部,混合排序是怎么去衡量或者怎么度量广告价值和自然流量价值差异?
A:第一版方案,是不管自然结果出什么,广告侧只优化广告出什么,加上一些必要的策略。第二版是和斯坦福的经济学家合作,给自然结果提出了一个virtual bid的概念,相当于把自然流量也当成是一个广告流量,它有一个虚拟的竞价,用virtual bid来衡量自然流量业务价值。这样就可以用virtual bid把自然流量和广告当成一个一样的东西来排序。这个策略还在实验中。
Q:在模型训练之中可能会考虑到多个指标,这多个指标之间的融合在训练中是怎么样的?怎么设计多个指标之间融合loss,或者其他的一个训练方式也好?
A:多个指标的融合,最主要的就是在后面拍卖机制优化reward。这个东西基本上就是通过调参和业务的先验知识,暂时也没有找到特别好的方法来自动化的把这些参数给定出来。
Q:对于强化学习的bidding策略,相对原来固定的bid,它的主要的优势在哪里?以及说应用了之后,对于线上的业务结果的提升,主要是来自哪些方面?
A:这里其实没有做一个基于强化学习的bidding策略,做的是一个基于强化学习的拍卖机制优化,Bid还是原来的Bid。Bid分两种,一种是广告主手动出的,一种是它用智能出价产品来出的,这不是优化的目标,优化的目标是根据广告主的Bid,用一个learning base的方式来学习一个平台多目标融合的分数,然后基于这个分数和广告主的Bid来实现流量重新的分配和pricing的过程。这个过程一方面考虑了会话级别的长期价值,不只是说当前的请求能拿到多少业务价值。第二点,优化拍卖机制,解决了广告拍卖的生态问题,让它变得更激励相融,让广告竞价生态变得更好。
Q:对于这样的一个多版本的重排的迭代,在线上的话,大概各自取得什么样的收益?
A:序列生成评估这个框架上线了多次,因为生成的策略也是可以调的,评估模型也是可以调的,以及融合公式都是可以调的,打包反转显示RPM涨15%左右。在京东的场景下,会话级别的广告拍卖机制,第一版小流量做出来,RPM涨五六个点,在机制的优化上面,至少有20个点的空间,所以这个方向的优化空间应该是非常大的。
今天的分享就到这里,谢谢大家。
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“强化学习” 就可以获取《强化学习专知资料大合集》专知下载链接





