【工大SCIR笔记】AAAI 2020 故事结局预测任务上的区分性句子建模
论文名称:Discriminative Sentence Modeling for Story EndingPrediction
论文作者:崔一鸣,车万翔,张伟男,刘挺,王士进,胡国平
原创作者:崔一鸣
下载链接:https://arxiv.org/abs/1912.09008转载须注明出处:哈工大SCIR
1. 简介
故事结局预测(Story Ending Prediction)任务需要阅读一篇故事并且根据内容选择一个合适的结局,这要求机器能够理解故事内容并且可能需要常识知识来判断出正确结局。为了解决这个任务,在本文中我们提出了一个创新的神经网络模型Diff-Net来建模结局之间的差异性。该模型从三个角度对结局进行建模:上下文表示、故事表示、区分性表示。在Story Cloze Test(SCT)数据集上的实验结果表明该模型能够显著提升故事结局预测的效果。另外,我们在SCT v1.0和v1.5数据上探究了传统神经网络模型和以BERT为代表的预训练模型之间的差异点,并且给出了一些有趣的发现,这将有助于未来在该任务上的研究。
2. 动机
早期在故事结局预测任务中的相关模型通常考虑了语言学风格分析[1],引入外部知识[2],使用大规模无标注数据[3]等方法。Cai等人[4]提出了一种完全端到端的神经网络模型,其效果与基于特征的方法相匹敌。
虽然这些工作显著提升了故事结局预测任务的效果,但他们忽略了对于结局差异性的比较。尤其当两个候选结局内容相似时,应该通过“对比”来选择出更优的一个。这就要求我们更加关注两个结局之间的差异点。

图1 Story Cloze Test数据集样例
如上例中,故事的两个结局非常相似,仅最后一个单词不同,且它们是决定结局的关键词汇。由此可见,如果显式地将结局中的不同部分进行建模将有助于故事结局预测任务。
因此,本文在故事结局预测任务中做出如下几点贡献:
我们提出了一种创新的神经网络模型Diff-Net用于解决故事结局预测任务;
在SCT v1.0和v1.5数据集上的实验结果表明模型能够带来显著性能提升;
我们给出了一些在SCT数据集上有趣的分析结果,这可能对未来研究有所帮助。
3. 模型
3.1 任务定义
本文中提到的故事结局预测任务主要针对Story Cloze Test数据集[5]展开研究。该数据集的每个样例包含由四个句子组成的小短文,并且给出了两个候选结局,其中之一是该故事的真结局。具体样例可以参考上一节中的图1。
3.2 方法
接下来我们介绍本文所提出的Diff-Net模型。该模型由上下文表示、匹配模块、区分模块、输出模块构成。整体模型结构如图2所示。
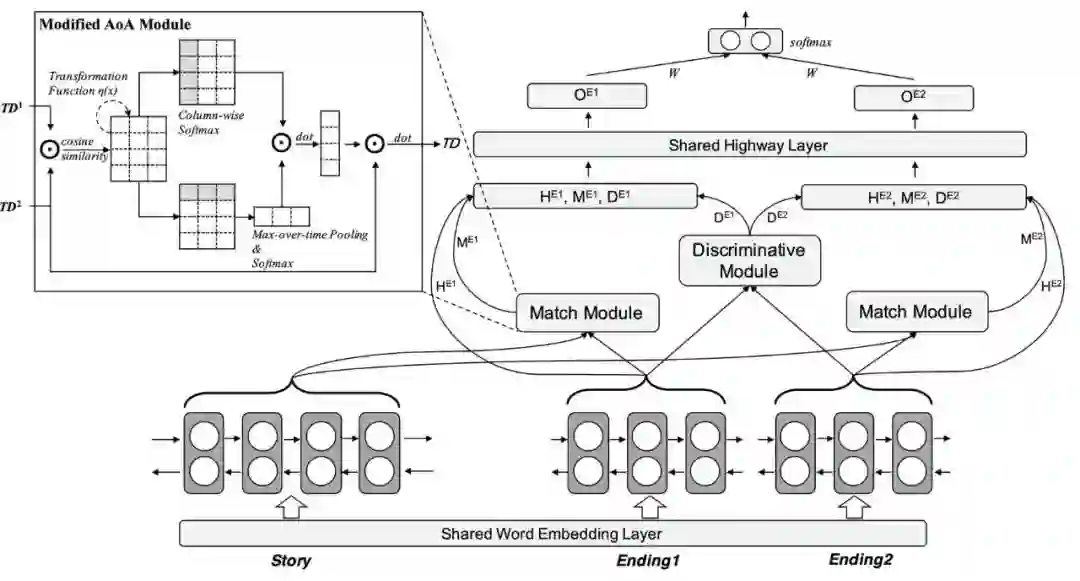
图2 Diff-Net整体模型结构
上下文表示
我们将故事和结局映射到词向量空间,并且拼接了以下三个离散特征:
结局-结局匹配:如果当前单词存在于另外一个结局中,则置为1,否则为0
结局-故事匹配:如果当前单词存在于故事中,则置为1,否则为0
结局-故事模糊匹配:经过词干提取后,如果当前单词存在于故事中,则置为1,否则为0
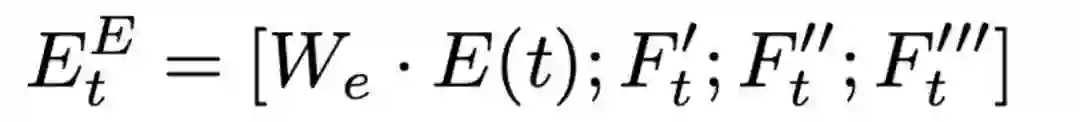
然后我们使用双向LSTM得到故事和结局的表示。同时我们利用MaxPooling来得到结局的二维表示HE用于后续的计算。
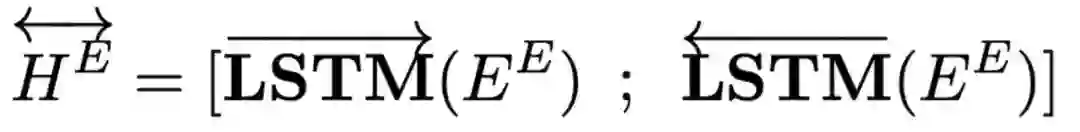
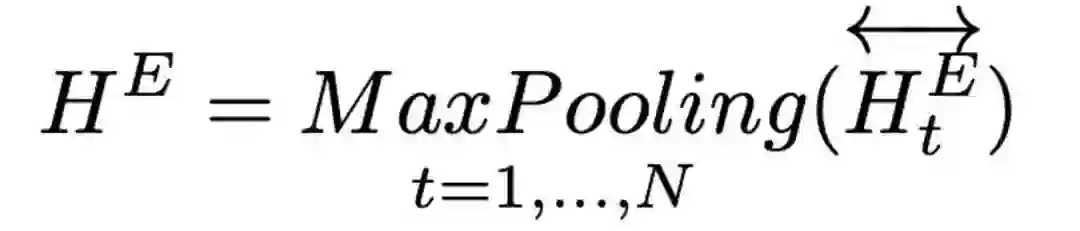
匹配模块
得到上述表示后,我们使用额外的全连接层来获得维度减半的向量。
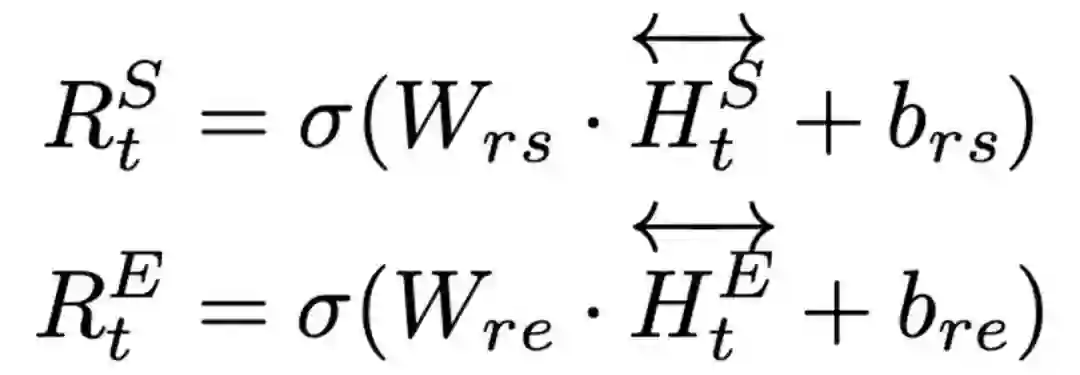
为了计算故事和结局之间的关联,我们使用了Attention-over-Attention (AoA) 结构[6]。在本文中我们对原始的AoA结构进行了一些调整,其中包括:
1. Dot计算替换为Cosine计算
2. MaxPooling替换为AveragePooling
3. 在匹配矩阵上添加了转换函数
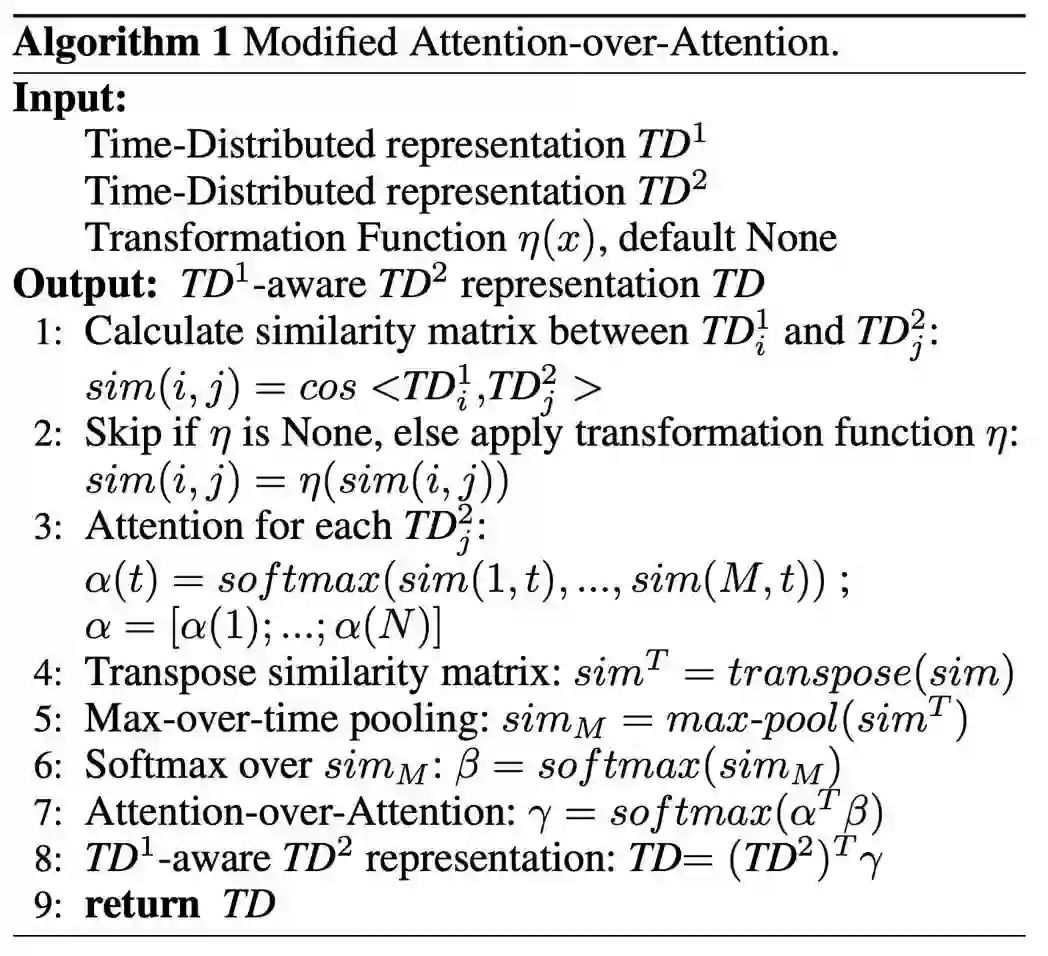
经过修改的AoA算法如图3所示,也可以通过系统结构图2中左上角的部分直观地进行理解。经过该结构的计算,我们可以获得每个结局与故事之间的匹配程度,并且能够得到Story-aware的表示。
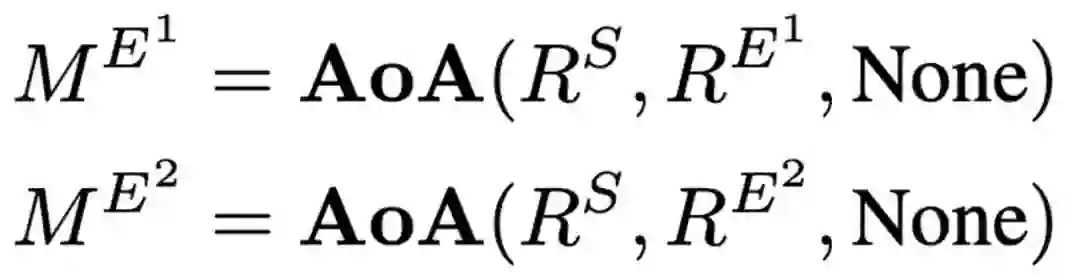
区分模块
为了建模两个结局之间的差异性,我们在修改过的AoA结构中应用转换函数η。在本文中我们定义η(x)=-x。由此我们可以得到两个结局差异点的表示。
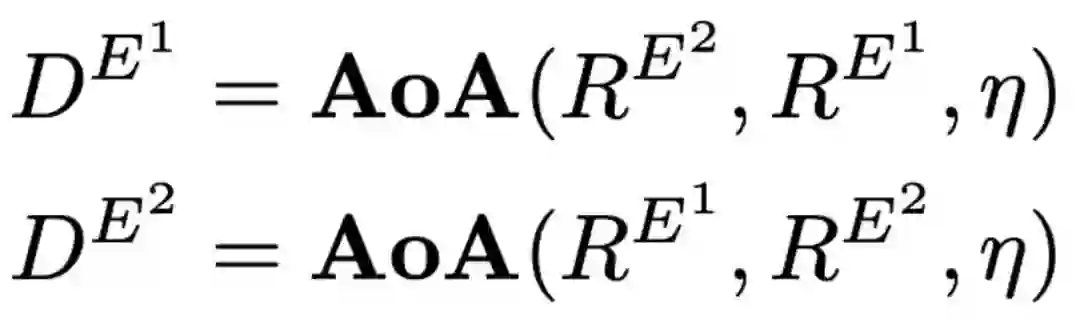
最终输出
最后我们对上下文表示、匹配表示、区分表示进行拼接并得到最终的概率输出。
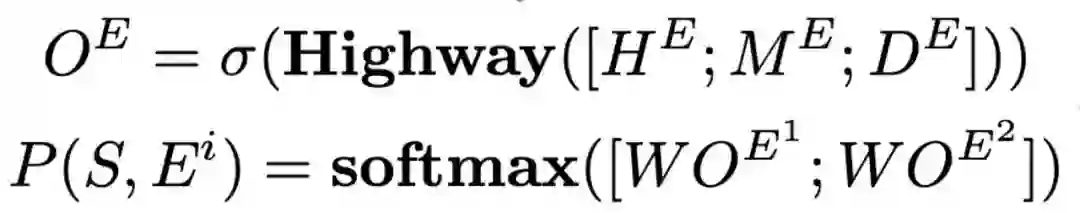
除了常规的交叉熵损失之外,我们还添加了额外的cosine损失,用来拉远两个结局表示的空间距离。我们在实验中发现这种方法能够稳定实验结果。
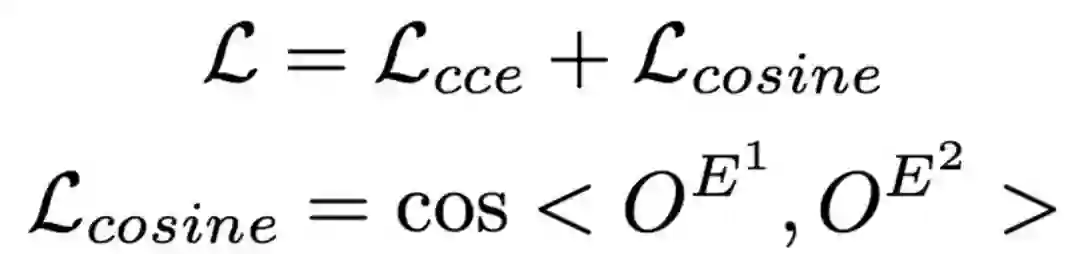
在BERT中精调
以上介绍的是基于传统模型的Diff-Net。如果要与BERT[7]进行结合使用,只需要将最后的表示拼接替换为如下公式,即使用BERT的表示与区分表示进行拼接,并得到最终的概率输出。
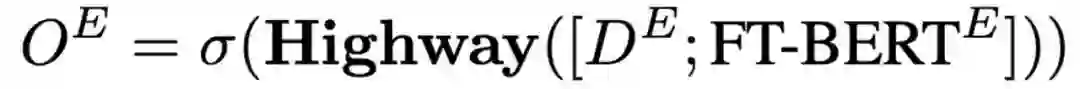
4. 实验结果
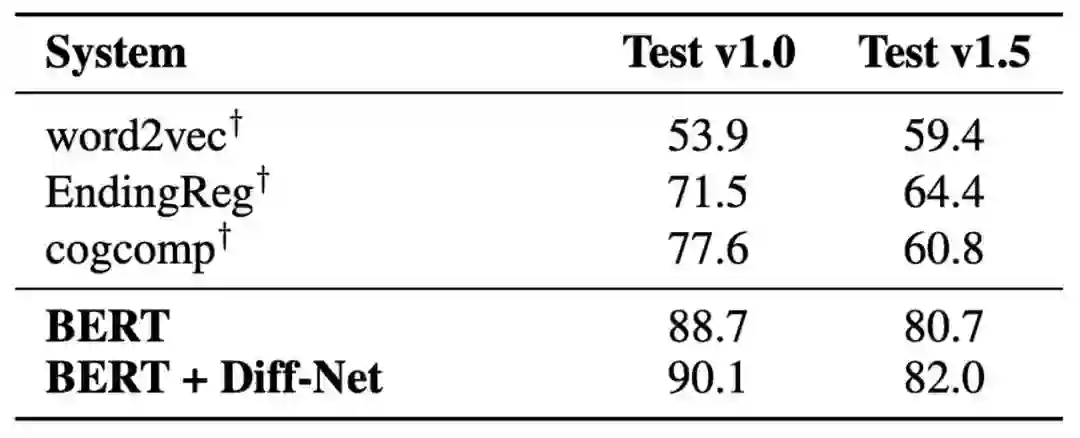
我们在Story Cloze Test v1.0和v1.5数据集上验证了我们的模型。可以看到Diff-Net相比其他传统模型能够得到显著性能提升。在融合BERT表示后仍然能够相对BERT基线得到进一步提升,说明建模结局之间的差异点是非常有必要的。
表1 SCT v1.0上的实验结果
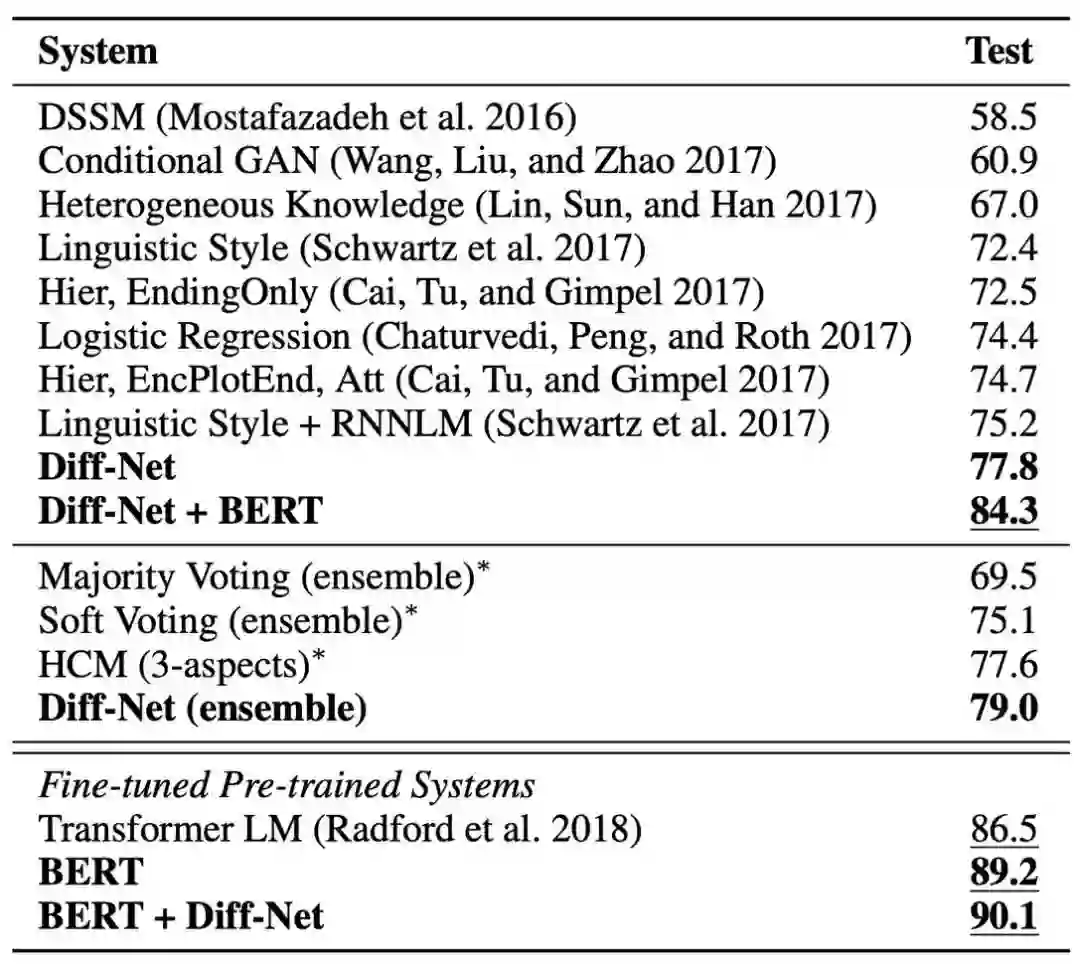
表2 SCT v1.5上的实验结果
5. 讨论
虽然BERT以及我们的模型在故事结局预测上获得了不错的效果,但仍有如下几个问题亟待回答。
这些模型是否真正理解了故事?
Story Cloze Test(v1.0和v1.5)数据集是否适合作为故事理解数据集?
除了客观指标之外,相比传统模型,BERT的优势是什么?
为了回答如上几个问题,我们对故事中的部分句子进行了删除、倒置、随机打乱,以此来探究故事中的哪些部分对于最终预测有效。
表3 使用不同故事句子组成的实验结果
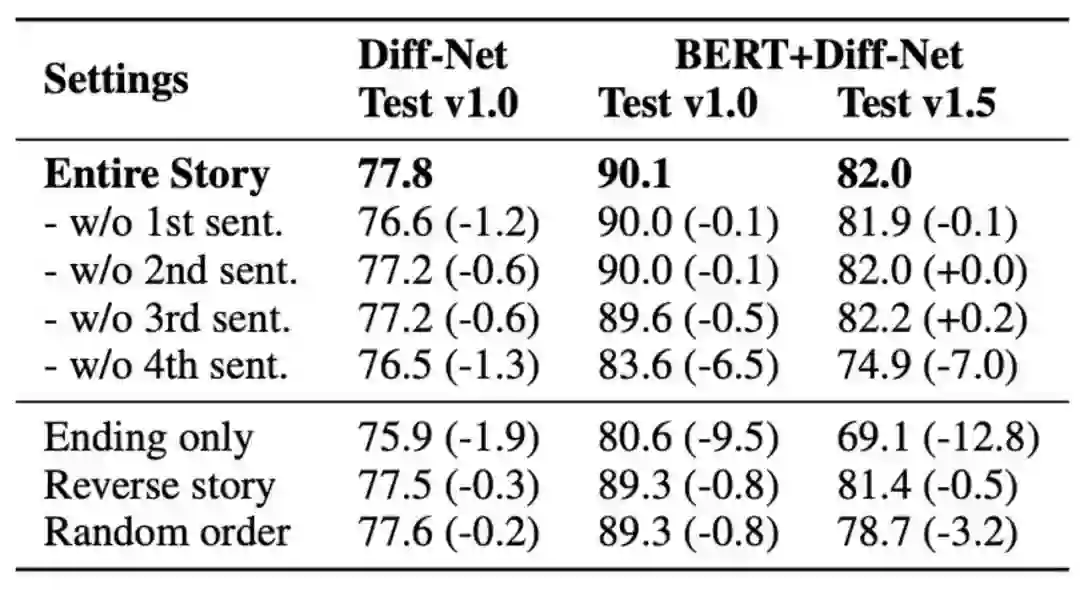
从表3的实验结果,我们能够得到如下观察结论。
1)新数据SCT v1.5仍然存在“最后一句偏置”问题
从实验结果来看,去掉故事中的最后一句(w/o 4th sent.)来预测结局的情况下,SCT v1.0的效果降幅较小,而SCT v1.5上的降幅较大,说明SCT v1.5在“最后一句偏置”问题上有所改善。然而,从下例中可以看到故事的前三句对于最终任务选择毫无作用,模型只需要知道最后一句中的“tie(平局)”即可选择出正确的结局。

2)BERT在联系故事和结局方面优于传统神经网络
在SCT v1.0数据上,对比 Diff-Net 以及 BERT+Diff-Net 的实验效果,我们可以看到当不使用任何故事信息时含有BERT的模型效果下降较大,说明BERT模型更加依赖故事信息,并且能够更好地挖掘故事和结局之间的联系。
3)脚本知识可能在该任务上收益甚微
我们可以看到将故事中的四个句子进行倒序排列(Reverse story),甚至是将四个句子完全随机排列(Random order)之后最终的结果并没有显著下降。这说明目前模型对于故事中的事件顺序不敏感,模型更加依赖的可能仍然是词汇级别的信息,而非事件顺序。所以我们怀疑该使用脚本知识(这也是数据集制作人的初衷)来提升该任务的收益可能非常小。
6. 结论
在本文中,我们在故事结局预测任务上提出了一种创新模型 Diff-Net。该模型能够从三个角度动态建模故事结局并且能够抽取出相关信息,并且使用额外的余弦距离来拉远两个结局的语义空间。在SCT v1.0和v1.5上的实验结果表明,该结构能够在传统神经网络以及BERT上获得进一步性能提升。
同时通过我们的分析发现,目前的故事理解模型并没能实现“故事理解”,距离真正的目标还有很长一段距离。正如我们的分析,故事里句子的顺序并不会影响最终结局,所以在未来我们将尝试利用脚本知识来验证该任务是否真正需要此类外部知识。同时我们将探索使用无标注的训练数据(例如进行预训练或构件知识库)来进一步提升该任务的效果。
参考文献
[1] Schwartz et al., 2017. The Effect of Different Writing Tasks on Linguistic Style: A Case Study of the ROC Story Cloze Task. In CoNLL 2017.
[2] Lin et al., 2017. Reasoning with Heterogeneous Knowledge for Commonsense Machine Comprehension. In ACL 2017.
[3] Wang et al., 2017. Conditional Generative Adversarial Networks for Commonsense Machine Comprehension. In IJCAI-17.
[4] Cai et al., 2017. Pay Attention to the Ending: Strong Neural Baselines for the ROC Story Cloze Task.In ACL 2017.
[5] Mostafazadeh et al., 2016. A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories.In NAACL 2016.
[6] Cui et al., 2017. Attention-over-Attention Neural Networks for Reading Comprehension. In ACL 2017.
[7] Devlin et al., 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT 2019.
赛尔原创 | AAAI20 基于多任务自监督学习的文本顺滑研究
赛尔原创 | AAAI20 基于选择两方面信息的文档级文本内容改写
赛尔原创 | AAAI20 基于关键词注意力机制和回复弱监督的医疗对话槽填充研究
本期编辑:王若珂