自动化所开源轻量易读易扩展分布式博弈学习训练框架MSAgent,发布谷歌足球联盟训练基准AI

近年来,决策智能在复杂博弈领域取得了以AlphaGo为代表的一系列重大突破,已成为国家新一代人工智能的重要发展方向。人工智能技术正在实现从感知智能到决策智能的跃迁,被广泛应用于提升智慧城市、交通管理、能源管理、双碳战略、医药生物、自动驾驶等领域的管理效能,正在深刻影响着社会经济活动。
Dota2(左)和StarCraft(右)游戏
在此背景下,中科院自动化所正式开源轻量易读易扩展的分布式博弈学习训练框架MSAgent,并基于此发布谷歌足球联盟训练基准AI,旨在支持大规模博弈学习训练,推动决策智能应用发展,发展博弈决策领域生态。
当前博弈决策技术研究主要集中在二人零和博弈问题,特别是一些复杂的不完美信息博弈,存在的技术挑战包括指数爆炸性增长的信息集数量、巨大的观测以及动作空间、稀疏奖励、长时决策、传递性策略集合和非传递性策略集合共存等等。
首先,以AlphaStar、OpenAI Five为代表性的AI技术验证了通过简单的自博弈在非传递性策略集合中找到纳什均衡解难度极大,高泛化性与鲁棒性的决策AI在训练过程中需要构建多样性策略集合。
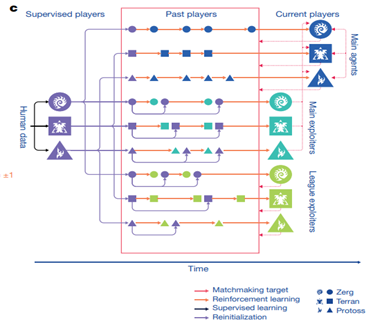
AlphaStar训练示意图
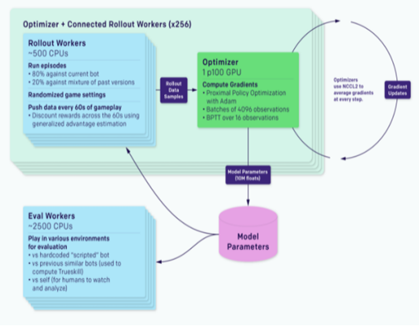
OpenAI Five训练示意图
对此,DeepMind有一个形象的"陀螺模型"描述,陀螺的宽代表策略的多样性,陀螺的高则代表技能水平,为了达到最终的纳什均衡,必须依赖足够多的策略集合。
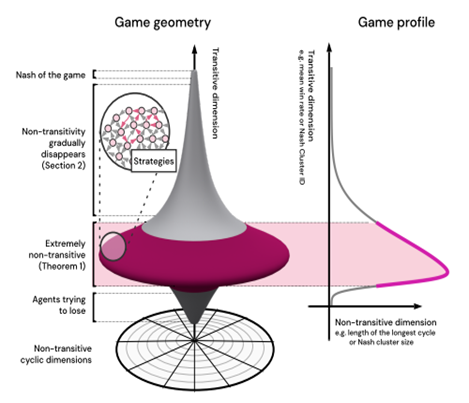
DeepMind: Real World Games Look Like Spinning Tops
其次,训练游戏AI存在着依赖大规模分布式训练、大量环境并行、海量数据传输(包括但不限于交互轨迹以及模型参数等等),针对采样、推理、学习三个子任务的解耦与优化(包括但不限于采样效率的提升),以及高效的梯度计算与参数更新模式等挑战。亟需研发高性能训练框架来降低在技术层面训练AI的难度和成本。
针对上述难题,为促进研究人员最大程度聚焦算法研究本身,自动化所研发了一套轻量易读的基于微服务模式的分布式博弈学习训练框架MSAgent。该框架简化了分布式强化学习训练的开发难度,用户只需要基于框架提供的接口编写服务脚本与环境脚本,分别指定脚本路径以及启动数量等相关参数,就可以一键启动训练。MSAgent大大提高了易用性,方便部署至大规模集群,支持大规模博弈学习训练。
MSAgent框架的高效性与易用性可以总结为以下几点:
1.支持联盟训练模式: 基于pfsp的对手选择机制以及采用内存型数据库作为模型池,以实现更高速响应请求与更低延迟的读写。
2.模块化的设计理念与微服务范式: 将强化学习的actor,learner,environment完全拆分,各个组件都可以被自定制并封装成相应服务,以微服务架构实现服务注册,服务扩展与服务发现。
3.高效的梯度更新方式: 相比于PS计算模型容易出现局部热点导致加速恶化的情况,采用了RING-ALLREDUCE模型,以充分利用集群中节点间带宽。
4.高吞吐和高并发特性: 同时支持同步任务和异步任务,采用消息队列与任务队列的理念,结合消息路由机制高效完成任务调度与执行。
足球游戏具有足够丰富的场景和多智能体模式,需要AI学习在队友之间传球,克服对手防守进球以及在进攻与防守策略之间做平衡,提供了极具挑战性的决策问题,是当前困扰世界顶尖 AI 研究团队的难题之一,吸引了众多研究者们积极探索。其中,谷歌于2019年提出了Google Research Football 强化学习环境。MSAgent框架天然适合该类问题求解。
基于该框架,团队开发并发布了谷歌足球的联盟训练基准AI,便利研究者在此基准AI上结合自身算力资源和算法条件开发自己的谷歌足球AI,推动该问题的求解。
MSAgent框架也同样适用于双人格斗游戏。团队在双人格斗游戏和足球场景下的测试结果表示框架可以有效支持基于联盟训练的智能体算法研发,并可便捷扩展到大规模集群上。
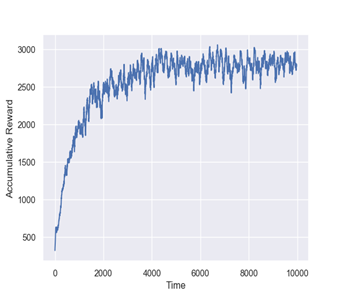
格斗累计回报示意图
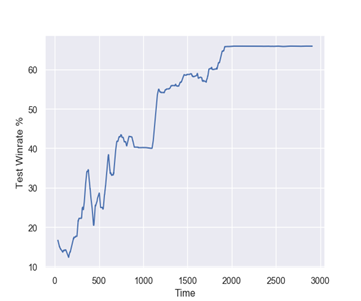
足球胜率示意图
游戏领域的应用只是冰山一角,以强化学习为代表的博弈决策智能在众多领域都拥有巨大的应用潜力。举例来说,在股票市场交易中, 基于强化学习的金融系统可以进一步优化股票回报;个性化用户体验的在线推荐中,可兼顾买卖双方进行训练,有效改进在线推荐效果;在线广告位投标中,可优化竞价过程以获取投放位置、受众与收益的平衡点。作为国家新一代人工智能的重要发展方向,博弈决策智能的研究和发展方兴未艾,也将为人工智能技术更广泛应用提供基础。
项目地址:
https://github.com/CodeBot416/decision-ai
欢迎大家批评指正。
团队介绍
该项目主要研发人员为王柏琳、李庆明、杨凯杰等人,项目得到张俊格、黄凯奇老师的联合指导。团队近年来主要致力于博弈决策智能相关理论、算法、平台以及智能体的研究,是国内较早开展星际争霸AI研究的队伍,并获得了2017年星际争霸大赛国际第四,2018年星际争霸大赛国际第三的成绩。团队研发的人机对抗AI训练场也已全网开放,是首个支撑兵棋推演AI和无限注德州扑克AI研发与训练的开放平台。
人机对抗AI训练场:
http://turingai.ia.ac.cn/training_center
参考资料:
2017年度星际争霸AI竞赛中科院自动化所第4,Facebook第6
2018 AIIDE星际争霸AI全球挑战赛结果出炉!中科院季军,三星拔得头筹
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。





