阿里开源支持10万亿模型的自研分布式训练框架EPL(EasyParallelLibrary)

一 导读
二 EPL是什么
1 项目背景
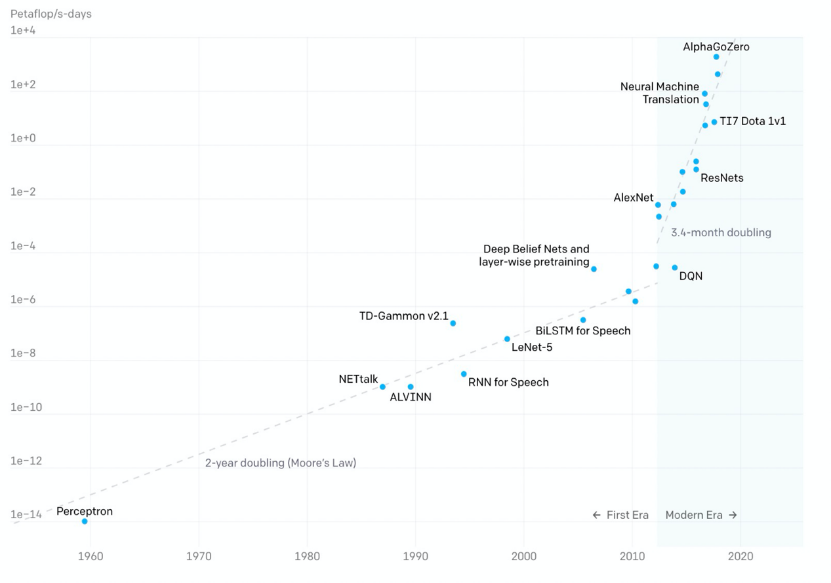
2012年以前,模型计算耗时每2年增长一倍,和摩尔定律保持一致;
2012年后,模型计算耗时每3.4个月翻一倍,远超硬件发展速度;
如何简洁易用:
接入门槛高:用户实现模型分布式版本难度大、成本高,需要有领域专家经验才能实现高效的分布式并行策略;
最优策略难:随着研究人员设计出越来越灵活的模型以及越来越多的并行加速方法,如果没有自动并行策略探索支持,用户很难找到最适合自身的并行策略;
迁移代价大:不同模型适合不同的混合并行策略,但切换并行策略时可能需要切换不同的框架,迁移成本高;
如何提高性价比:
业界训练万亿规模模型需要的资源:英伟达 3072 A100、谷歌 2048 TPU v3,资源成本非常高;
如何降本增效,组合使用各种技术和方法来减少需要的资源,提高训练的速度;
2 主要特性
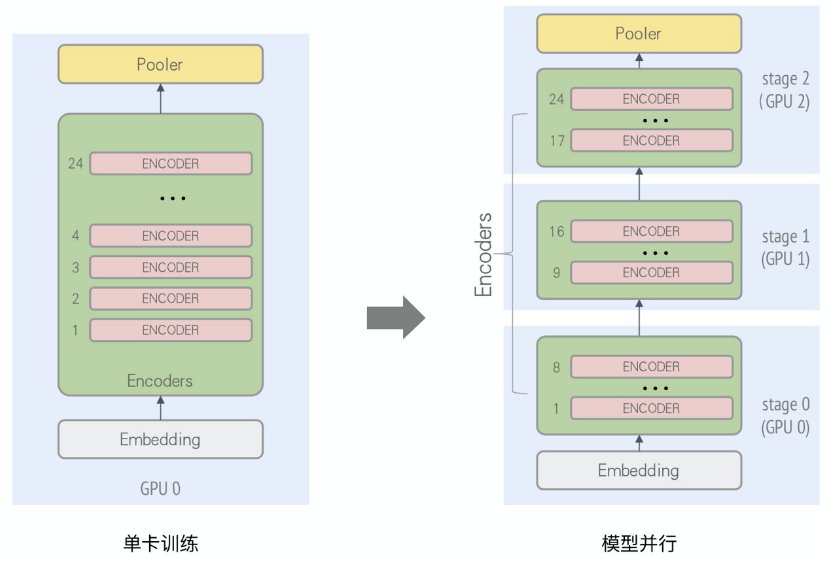
多种并行策略统一:在一套分布式训练框架中支持多种并行策略(数据/流水/算子/专家并行)和其各种组合嵌套使用;
接口灵活易用:用户只需添加几行代码就可以使用EPL丰富的分布式并行策略,模型代码无需修改;
自动并行策略探索:算子拆分时自动探索拆分策略,流水并行时自动探索模型切分策略;
分布式性能更优:提供了多维度的显存优化、计算优化,同时结合模型结构和网络拓扑进行调度和通信优化,提供高效的分布式训练。
3 开源地址见文末
三 EPL主要技术特点
丰富的并行化策略:EPL提供了多种并行化策略及其组合策略,包含数据并行、流水并行、算子拆分并行及并行策略的组合嵌套。丰富的策略选择使得不同的模型结构都能找到最适合自己的分布式训练方式。
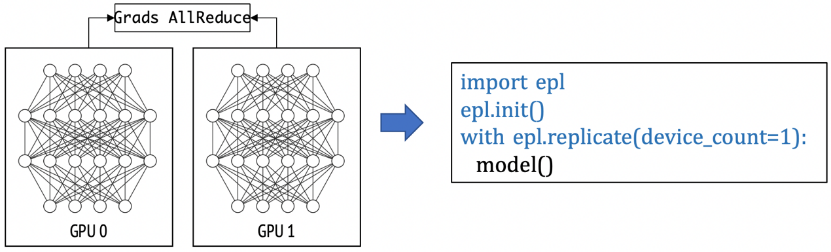
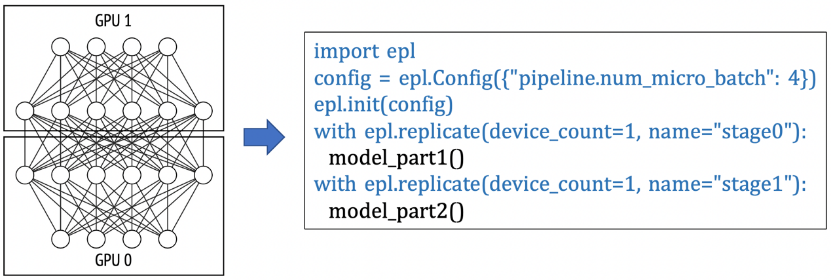
易用性:用户的模型编程接口和训练接口均基于TensorFlow,用户只需在已有的单机单卡模型上做简单的标记,即可实现不同的分布式策略。EPL设计了两种简单的策略接口(replicate/split)来表达分布式策略及混合并行。分布式策略标记的方式让用户无需学习新的模型编程接口,仅需几行代码即可实现和转换分布式策略,极大降低了分布式框架的使用门槛。
显存优化:EPL提供了多维度的显存优化技术,包含自动重算技术(Gradient Checkpoint),ZeRO数据并行显存优化技术,CPU Offload技术等,帮助用户用更少的资源训练更大的模型。
通信优化技术:EPL深度优化了分布式通信库,包括硬件拓扑感知、通信线程池、梯度分组融合、混合精度通信、梯度压缩等技术。
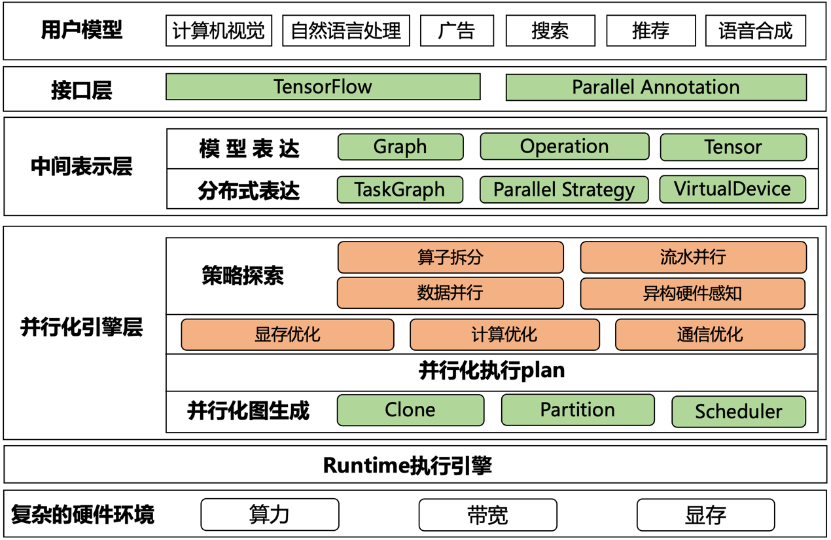
1 技术架构
接口层:用户的模型编程接口基于TensorFlow,同时EPL提供了易用的并行化策略表达接口,让用户可以组合使用各种混合并行策略;
中间表达层:将用户模型和并行策略转化成内部表达,通过TaskGraph、VirtualDevices和策略抽象来表达各种并行策略;
并行化引擎层:基于中间表达,EPL会对计算图做策略探索,进行显存/计算/通信优化,并自动生成分布式计算图;
Runtime执行引擎:将分布式执行图转成TFGraph,再调用TF 的Runtime来执行;
2 并行化策略表达
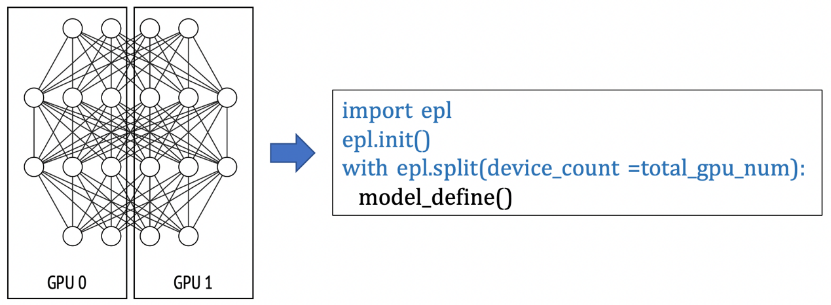
3 显存优化
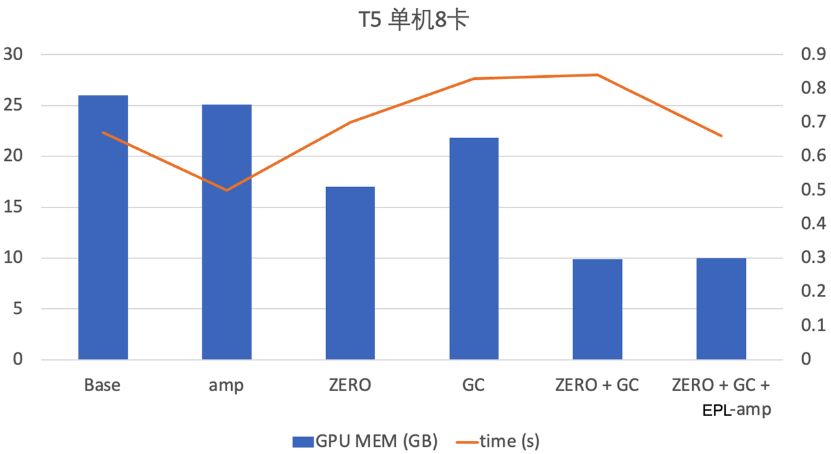
重算 Recomputation (Gradient Checkpoint):正常的DNN前向过程中会生成activation,这部分activation会在后向过程中用于梯度计算。因此,在梯度生成之前,前向的activation会一直存留在显存中。activation大小和模型结构以及batch size相关,通常占比都非常高。Gradient Checkpoint (GC) 通过保留前向传播过程中的部分activation,在反向传播中重算被释放的activation,用时间换空间。GC中比较重要的一部分是如何选择合适的checkpoint点,在节省显存、保证性能的同时,又不影响收敛性。EPL提供了自动GC功能,用户可以一键开启GC优化功能。
ZeRO:在数据并行的场景下,每个卡上会存放一个模型副本,optimizer state等,这些信息在每张卡上都是一样,存在很大的冗余量。当模型变大,很容易超出单卡的显存限制。在分布式场景下,可以通过类似DeepSpeed ZeRO的思路,将optimizer state和gradient分片存在不同的卡上,从而减少单卡的persistent memory占用。
显存优化的AMP(Auto Mixed Precision):在常规的AMP里,需要维护一个FP16的weight buffer,对于参数量比较大的模型,也是不小的开销。EPL提供了一个显存优化的AMP版本,FP16只有在用的时候才cast,从而节约显存。
Offload: Offload将训练的存储空间从显存扩展到内存甚至磁盘,可以用有限的资源训练大模型。
四 应用场景
1 万亿/10万亿 M6模型预训练
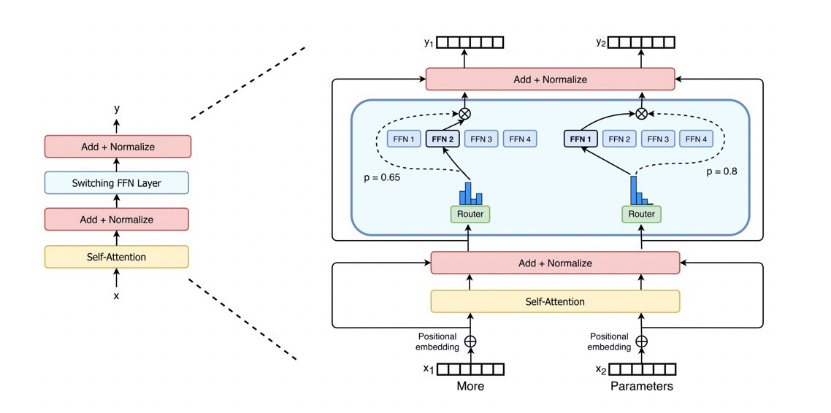
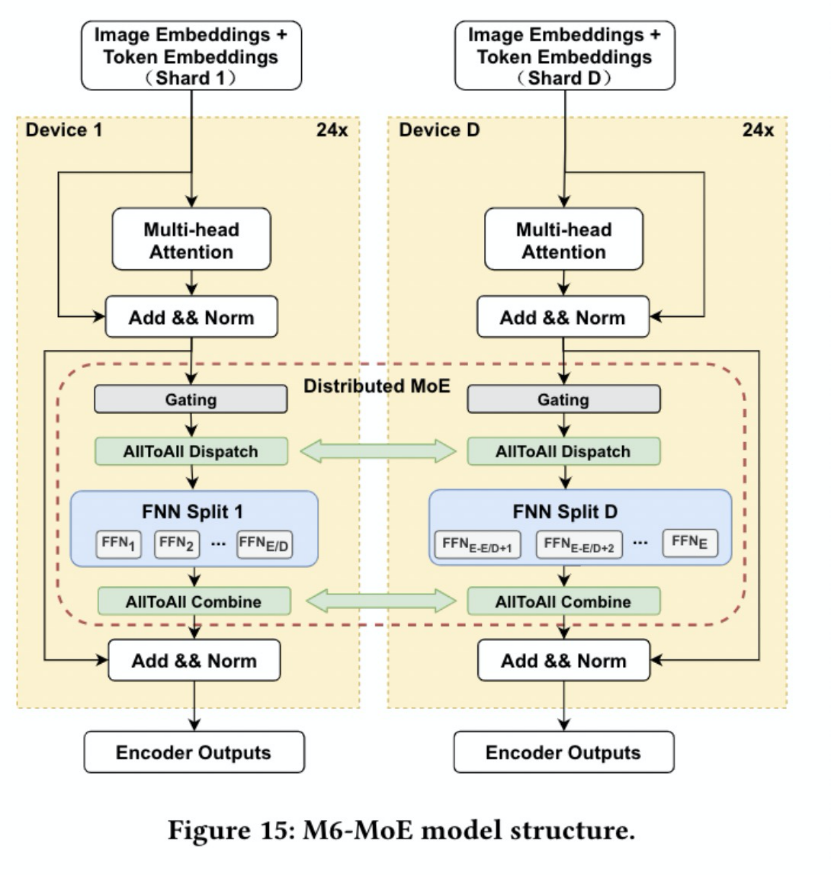

2 流水并行加速Bert Large模型训练


五 Roadmap
EPL发源于阿里云内部的业务需求,很好地支持了大规模、多样性的业务场景,在服务内部业务的过程中也积累了大量的经验,在EPL自身随着业务需求的迭代逐渐完善的同时,我们也希望能够开源给社区,将自身积累的经验和理解回馈给社区,希望和深度学习训练框架的开发者或深度学习从业者之间有更多更好的交流和共建,为这个行业贡献我们的技术力量。
我们希望能够借助开源的工作,收到更多真实业务场景下的用户反馈,以帮助我们持续完善和迭代,并为后续的工作投入方向提供输入。
同时,我们希望借助开源的工作,能吸引一些志同道合的同学、公司或组织来参与共建,持续完善深度学习生态。
持续的性能优化和稳定性改进;
通用算子拆分功能;
自动拆分策略探索的基础版;
自动流水并行策略探索;
全自动的模型并行策略探索;
高效的策略探索算法和精准的CostModel评估;
eager model下的并行策略探索;
更多新硬件的支持、适配和协同优化;
高效的算子优化和集成、极致的显存优化、软硬一体的通信优化;
3月9日19:00,阿里云开发者社区重磅评测栏目《开发者评测局》暨无影评测大赛颁奖典礼重磅开播。CSDN TOP 1 博主“处女座程序猿”、清华大学教授卓晴,苏宁消金安全运维总经理顾黄亮等来自开发者、高校、企业的参赛代表嘉宾将与无影内部团队将展开深度圆桌论坛,共话“云时代云办公”。点击阅读原文进入直播间!





