2018 机器阅读理解技术竞赛冠军 Naturali 分享问答系统新思路

AI 研习社按:7 月 28 日,由中国中文信息学会和中国计算机学会联合举办的第三届语言与智能高峰论坛于北京语言大学举办,Naturali 奇点机智团队作为 2018 机器阅读理解技术竞赛冠军团队,受邀参加本次活动的「机器阅读理解评测论坛及颁奖仪式」,Naturali 联合创始人兼 CTO、国际计算语言学协会会士(ACL Fellow)林德康作为代表进行了 2018 阅读理解技术竞赛系统报告。
机器阅读理解任务一直是自然语言处理领域的重要问题。2018 机器阅读理解技术竞赛提供了一个基于真实场景的大规模中文阅读理解百度数据集,共包含来自百度搜索的 30 万个来自真实用户的问题,对中文阅读理解系统提出了很大的挑战。Naturali 的系统在正式测试集上 ROUGE-L 和 BLEU-4 分别达到了 63.38 和 59.23,在 800 多支报名队伍、105 支提交最终结果的队伍中取得了第一名。
以下为 Naturali 奇点机智联合创始人兼 CTO 林德康在现场分享的竞赛报告:

一、DuReader 阅读理解数据集的特点
现在有很多阅读理解问答数据集,百度数据集算是中文阅读理解数据集里最好的。百度数据集相比 Stanford 经典数据集 SQuAD 更真实、更具挑战性。SQuAD 是从维基百科的信息来源集成问题,答案必定出现在文本里面,句法比较标准。而此次比赛的百度数据集都是用户的真实提问,不仅包括事实性的问题,还包括意见性的问题,部分问题在百度搜索里没有标准答案,并且问题的表达方式不一定很直接。
比如说意见性问题「iPhone X 好不好用」,或现象描述「响一声就说正在通话中」,这类问题回答起来难度更高。
二、竞赛题目实例
问题:昆特牌什么时候公测
人工标注答案:[‘时间为 6 月 6 日,暂定为期两周,即 6 月 6 日-6 月 19 日。']
Naturali 答案: [‘巫师之昆特牌国服山丘试炼开启时间为 6 月 6 日,暂定为期两周,即 6 月 6 日-6 月 19 日。’]
参考文档
['文章 阅读','巫师之昆特牌山丘试炼马上开启了,帅编来告诉大家开启时间。','巫师之昆特牌国服山丘试炼开启时间为 6 月 6 日,暂定为期两周,即 6 月 6 日-6 月 19 日。','参与过“青草试炼”的玩家将直接获得本次测试的资格,无需激活码。','国服公测时间暂未公布。','声明:本文由入驻搜狐公众平台的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。','一款专为游戏动漫爱好者打造的 app 全面的资讯福利,热门资讯图鉴攻略应有尽有。国内外热门手游推荐,精彩不容错过。','itmo 爱萌游戏-二次元游戏第一门户 itmo 爱萌游戏是国内第一二次元游戏门户网站,致力于打造全新型的手机游戏网站。']
['南方公园游戏在 U2 上放出了新的宣传片昆特牌公测日期发布南方公园游戏这都从去年 4 月延到今年 10 月不过动画 21 季今年 9 月开始播刚好可以衔接到游戏发售日期','反正昆特牌打了一下午电脑一盘没赢我就放弃了','我巫师 3 二周目开始玩昆特牌,毕竟一周目没钱,二周目也不继承。现在走到哪打到哪。','下周就公测?好突然,这么快','昆特盘看测试录像,氪金也是厉害啊。。。这南方公园竟然跳票到这个时候。。','昆特牌国际服已经激活就是看不懂挺期待南方公园的','期待 spOktoberfest! 另外希望昆特正式服早日上线','南方公园一听就是垃圾游戏,大家千万别买','应用吧活动,去领取','活动截止:2100-01-01','要不是川普赢了,也不至于这么跳票','昆特牌还没公测啊,我都以为大家已经玩了好久了','打牌才是正事 打牌打到十一月玩高清二战 美滋滋’]
解析说明:参考文档是从搜索引擎得到的排名靠前结果的网页全文,一个问题会对应多篇长文档;标注答案是人工根据文档总结撰写而成,一个问题可能对应多个答案,特别是对意见性的问题来说,有多个答案是很常见的。从以上案例可见,Naturali 阅读理解系统给出的答案比人工答案甚至还要全面。
三、数据预处理
百度提供五个篇文章作为参考文档。由于文章没有长度限制,我们根据关键词密度,句子位置等信息将超过 500 词的文章压缩到 500 词以内。
以下是我们数据预处理的具体方法:
如果标题和各段内容中间插入特殊分割符号连接在一起,没有超过预设最大长度,则将得到结果作为预处理的结果;
否则,我们计算各段落和问题的 BLEU-4 分数,以衡量段落和问题的相关性;
在分数排名前 k 的段落中,选择最早出现的段落;
选取标题,这个段落以及下一个段落;
对于第 3 到第 10 个段落,选取每个段落的第一句话;
将所有选取的内容以特殊分隔符连接在一起,截取最前面不超过预设最大长度的内容,将得到的结果作为预处理的结果。
四、模型整体结构
我们使用的模型整体结构,是经典的端对端阅读理解模型结构,分为四层:
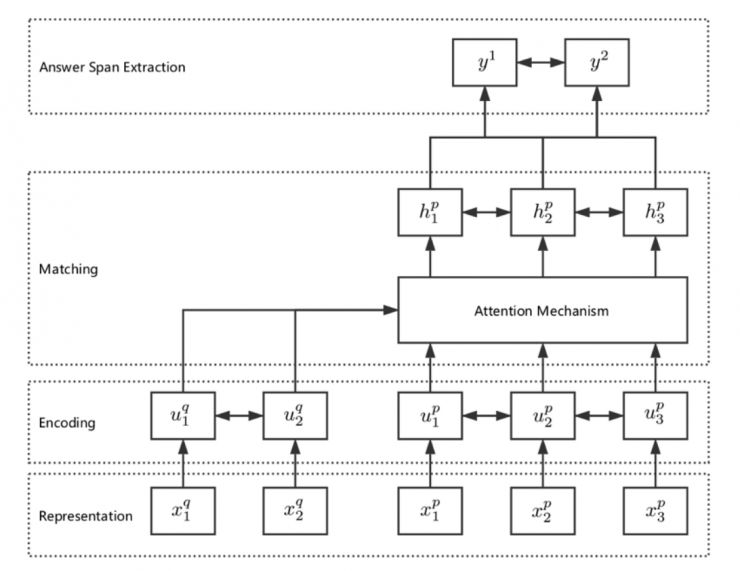
第一层:特征表示层(Representation)
第二层:编码层(Encoding)
第三层:匹配层(Matching)
第四层:答案片段抽取层(Answer Span Extraction)
下面我们对每一层进行简单介绍。
第一层:特征表示层
首先,给定一个问题的词序列和篇章的词序列,我们要对它进行特征抽取,将它变成一个特征向量序列。
我们是在搜狗互联网语料库上进行的预训练。这个数据集比百度数据集还要大好几个量级,所有中文网页都在里,每一词用什么向量表达就是在这里面训练的。
第二层:编码层
得到问题和篇章的向量特征表示序列后,我们分别进行编码。
第三层:匹配层
匹配层是模型比较核心的部分,我们利用注意力机制融合问题和篇章信息。
经过了几种模型的测试,最后我们的系统里用到了 Match-LSTM、BiDAF、DCA 这三种集成模型,相比其他模型,这几种模型效果接近,训练速度较快。在单一模型中我们运用 BiDAF,在集成模型中则会运用到不同的匹配层得到的结果进行集成。
第四层:答案片段抽取层
最终,我们利用指针网络进行答案抽取。
根据百度数据集特点,回答里面可能会包含多个答案,所以我们采用的是第二种利用多个参考答案的公式进行计算,即在多个答案上损失的平均数作为损失函数。
● 常用损失函数
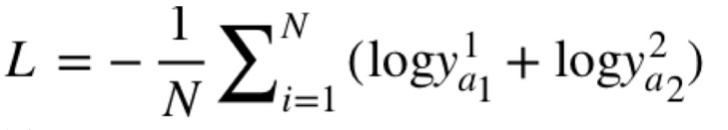
● 利用多个参考答案
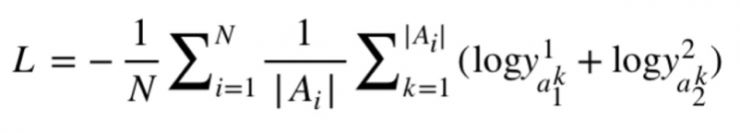
五、最小风险训练
通常的 RC 系统是以提高标准答案概率作为训练的目标,但实际评测的标准是 ROUGE。最小风险训练是拿评测的标准作为训练的目标,需要对每个片段都计算损失函数,所以优化的时间比较长。我们的系统首先用最大似然估计训练得到初始模型,然后直接优化 ROUGE 函数,让我们的 ROUGE 值达到最高。这里 delta(y_i, y_i*) 是候选答案 y_i 与标准答案 y_i* 在 ROUGE 函数上的差。
● 最小风险训练
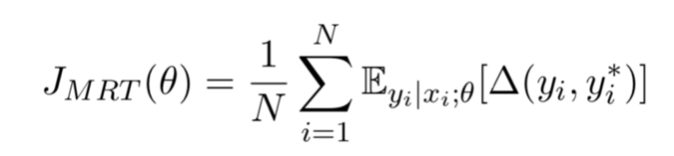
● 以最大似然估计训练得到的模型初始化继续训练
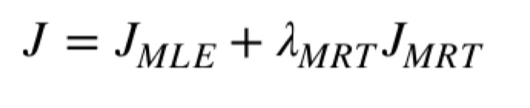
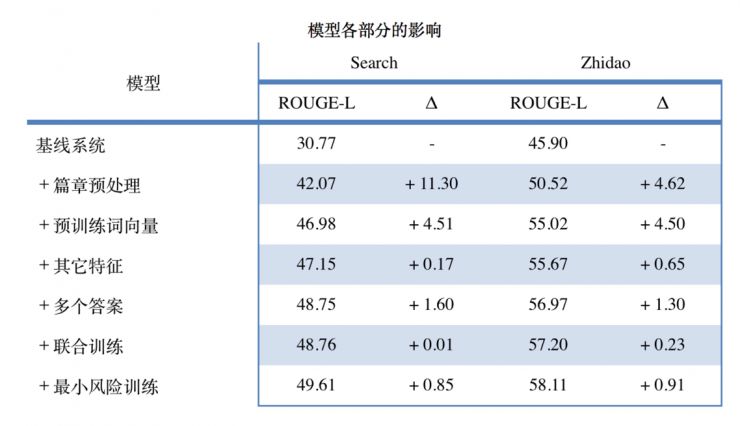
六、单一模型实验结果
我们的 ROUGE 分数最终能够远远超出基线系统分数,是通过篇章预处理、预训练词向量、其他特征、多个答案、联合训练、最小风险训练等方法综合累计得来的。
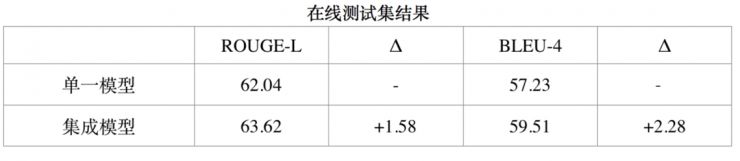
七、集成模型
我们提交的数据是通过集成模型计算出来的,最终根据不同种模型(BiDAF, MatchLSTM, DCA)和不同参数(Dropout:0.1, 0.15, 0.2,联合学习比率:4.0, 5.0)做成了一个集成模型,比单一模型的 ROUGE 分数又高出了 1.5 个点。
八、总结及展望
我们本次竞赛用的是神经网络端到端的系统,而我曾经在谷歌做搜索问答用的是模块化的系统。模块化系统会把问题分成几部分,首先识别答案类型,再根据类型和问题、文本的匹配度去计算分数。而神经网络系统把所有的步骤放到一个网络里面,虽然没有专门为不同的答案类型建模,但是训练完成后仍然能够覆盖到不同问题类型,比如问「什么时候......」,找的答案里就有日期。
相比模块化系统,神经网络端到端的系统代码简单很多,并且每次改动、优化都是全局的优化。然而模块化系统的优化,是优化某一个模块,模块之间已经适应了各自的缺陷,其中一个模块变好,其他模块不一定随之改善,使整个系统的优化会变得比较困难。
目前有很多问答系统已经上线了,但是背后的实现还是模块化的机制。很有可能神经网络系统现在的表现暂时还不及模块化系统,但到现阶段它的准确度已经可以有一些应用。比如我们做语音助手的时候,经常将搜索作为一个「兜底」的功能。比如在智能客服应用中,拿客服文档做关键词匹配,但用自动阅读理解就可以把阅读理解系统当做一个「兜底」,找到文档以后便可以把更精简、准确的答案找出来。
最后,如果有对我们的团队感兴趣的同学,欢迎投简历到 jobs@naturali.io,期待你与我们一起,在 AI 语音交互这条路上共同前行。
谢谢大家。
附 Naturali 奇点机智简介:
Naturali 创立于 2014 年 11 月,目前已经将业务聚焦在两个方面:一个是 NI 开放平台——「零编码、五分钟 ,创造属于你的语音技能」,为各类硬件、APP 赋予 AI 语音交互能力。另一个是一款带有学习功能的第三方语音助手 APP「布点语音」,已经在各大安卓商店上线,目前已经可以覆盖 300+APP,支持 12000+ 语音技能。
想阅读更多语音语义文章
欢迎点击“阅读原文”
或者移步 AI 研习社社区~





