如何走近深度学习人脸识别?你需要这篇超长综述 | 附开源代码

作者丨葛政(早稻田大学硕士生,研究方向是深度学习,计算机视觉)
博客丨Xraft.Lab
来源 | PaperWeekly
相信做机器学习或深度学习的同学们回家总会有这样一个烦恼:亲朋好友询问你从事什么工作的时候,如何通俗地解释能避免尴尬?
我尝试过很多名词来形容自己的工作:机器学习,深度学习,算法工程师/研究员,搞计算机的,程序员…这些词要么自己觉得不满意,要么对方听不懂。经历无数次失败沟通,最后总结了一个简单实用的答案:“做人脸识别的”。
为什么这个答案管用,因为人脸识别在深度学习相关领域的课题中属于商业落地情景多,被普及率广的一项技术,以至于谁说不出几个人脸识别应用,都有那么点落后于时代的意思。
今天出这篇人脸识别,是基于我过去三个月在人脸识别方向小小的探索,希望能为非技术从业者提供人脸识别的基本概念(第一部分),以及为人脸识别爱好者和入门人员提供储备知识和实验数据参考(第二、第三部分),也欢迎专业人士提供宝贵的交流意见。
本文将从接下来三个方面介绍人脸识别,读者可根据自身需求选择性阅读:
Chapter 1:人脸识别是什么?怎么识别?
Chapter 2:科研领域近期进展
Chapter 3:实验及细节
01
人脸识别是什么?怎么识别?
▌人脸识别是什么
人脸识别问题宏观上分为两类:1. 人脸验证(又叫人脸比对)2. 人脸识别。
人脸验证做的是 1 比 1 的比对,即判断两张图片里的人是否为同一人。最常见的应用场景便是人脸解锁,终端设备(如手机)只需将用户事先注册的照片与临场采集的照片做对比,判断是否为同一人,即可完成身份验证。
人脸识别做的是 1 比 N 的比对,即判断系统当前见到的人,为事先见过的众多人中的哪一个。比如疑犯追踪,小区门禁,会场签到,以及新零售概念里的客户识别。
这些应用场景的共同特点是:人脸识别系统都事先存储了大量的不同人脸和身份信息,系统运行时需要将见到的人脸与之前存储的大量人脸做比对,找出匹配的人脸。
两者在早期(2012年~2015年)是通过不同的算法框架来实现的,想同时拥有人脸验证和人脸识别系统,需要分开训练两个神经网络。而 2015 年 Google 的 FaceNet [1] 论文的发表改变了这一现状,将两者统一到一个框架里。
▌人脸识别,怎么识别
这部分只想阐明一个核心思想:不同人脸由不同特征组成。
理解这个思想,首先需要引入的的是“特征”的概念。先看下面这个例子:
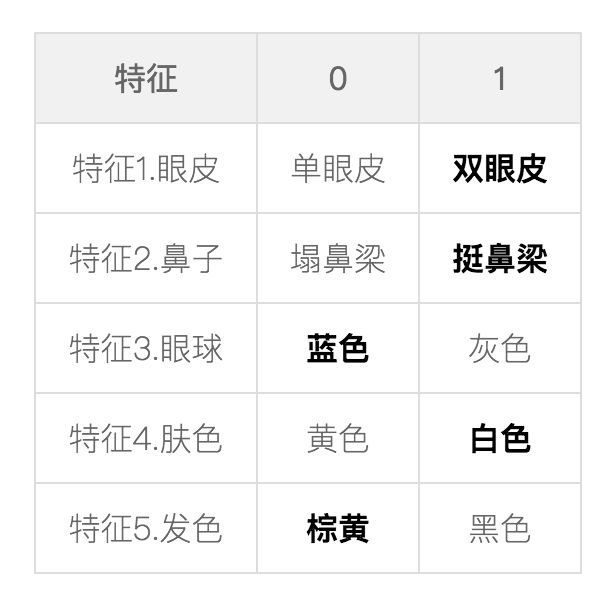
假设这 5 个特征足够形容一张人脸,那每张人脸都可表示为这 5 个特征的组合:
(特征1,特征2,特征3,特征4,特征5)
一位双眼皮,挺鼻梁,蓝眼睛,白皮肤,瓜子脸的欧美系小鲜肉即可用特征表示为(见表格加粗项):
(1,1,0,1,0)
那么遍历上面这张特征表格一共可以代表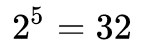
列的角度很简单,只需要增加特征数量:(特征6.脸型,特征7.两眼之间距离,特征8.嘴唇厚薄…)实际应用中通常应用 128,256,512 或者 1024 个不同特征,这么多特征从哪来,该不会人为一个一个去设计吧?这个问题在后面会解答。
从行的角度扩充也很好理解,比如“特征3”,除了值 0 代表蓝色,值 1 代表灰色,是不是可以增加一个值 2 代表黑色,值 3 代表没有头发呢?此外,除了这些离散的整数,我们也可以取连续的小数,比如特征 3 的值 0.1,代表“蓝中略微带黑”,值 0.9 代表“灰中带蓝”……
经过这样的扩充,特征空间便会变得无限大。扩充后特征空间里的一张脸可能表示为:
(0, 1, 0.3, 0.5, 0.1, 2, 2.3, 1.75,…)
之前提出的问题:用于表示人脸的大量特征从哪来?这便是深度学习(深度神经网络)发挥作用的地方。它通过在千万甚至亿级别的人脸数据库上学习训练后,会自动总结出最适合于计算机理解和区分的人脸特征。
算法工程师通常需要一定的可视化手段才能知道机器到底学习到了哪些利于区分不同人的特征,当然这部分不是本节重点。
阐明了不同人脸由不同特征组成后,我们便有了足够的知识来分析人脸识别,到底怎么识别。
现在考虑最简单最理想的情况,用于区分不同人的特征只有两个:特征1和特征2。那么每一张脸都可以表示为一个坐标(特征1,特征2),即特征空间(这个例子里是二维空间)内的一个点。
人脸识别基于一个默认成立的假设:同一个人在不同照片里的脸,在特征空间里非常接近。
为什么这个假设默认成立,设想一下,一个棕色头发的人,在不同光照,遮挡,角度条件下,发色看起来虽然有轻微的区别,但依然与真实颜色非常接近,反应在发色的特征值上,可能是 0 到 0.1 之间的浮动。
深度学习的另一任务和挑战便是在各种极端复杂的环境条件下,精确的识别各个特征。
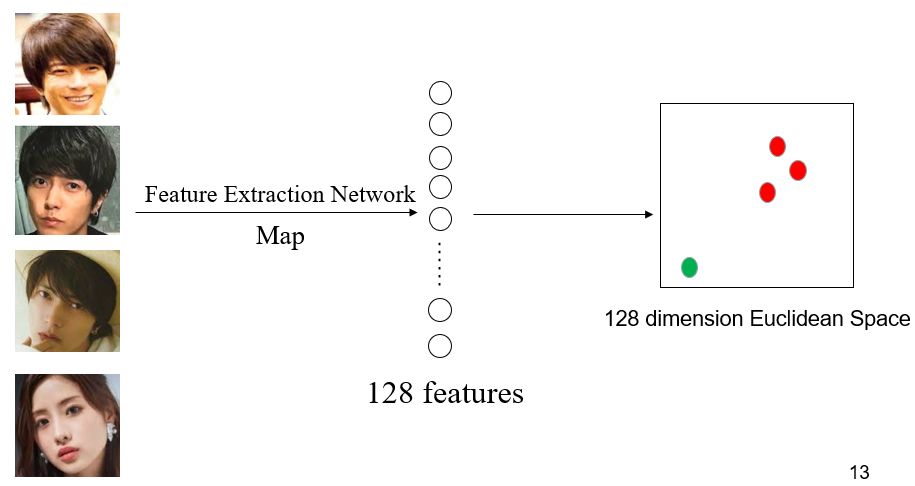
上图是在熊本做大规模人脸数据集去噪演讲时用的 PPT,三张山下智久的照片经过神经网络提取出 128 维的特征后,变成了 3 个在 128 维空间中的点(红色),石原里美的特征点为绿色。
这张 PPT 想表达同样的意思:同一人的不通照片提取出的特征,在特征空间里距离很近,不同人的脸在特征空间里相距较远。
再来考虑人脸识别领域的两个问题:人脸验证和人脸识别。
▌人脸验证
比如 FaceID 人脸解锁,iPhone 事先存了一张用户的照片(需要用户注册),这张照片变成了转换成了一连串特征数值(即特征空间里的一个点),用户解锁时,手机只需要对比当前采集到的脸和事先注册的脸在特征空间里的几何距离,如果距离足够近,则判断为同一人,如果距离不够近,则解锁失败。距离阈值的设定,则是算法工程师通过大量实验得到的。
▌人脸识别
同样考虑一个场景,人脸考勤。公司 X 有员工 A,B,C,公司会要求三名员工在入职的时候各提供一张个人照片用于注册在公司系统里,静静地躺在特征空间中。
第二天早上员工 A 上班打卡时,将脸对准考勤机器,系统会把当前员工 A 的脸放到特征空间里,与之前特征空间里注册好的脸一一对比,发现注册的脸中距离当前采集到的脸最近的特征脸是员工 A,打卡完毕。
知道了人脸识别的基本原理,便能看清它的技术局限。下图展示了一些容易识别失败的案例:

在光照较差,遮挡,形变(大笑),侧脸等诸多条件下,神经网络很难提取出与“标准脸”相似的特征,异常脸在特征空间里落到错误的位置,导致识别和验证失败。这是现代人脸识别系统的局限,一定程度上也是深度学习(深度神经网络)的局限。
面对这种局限,通常采取三种应对措施,使人脸识别系统能正常运作:
1. 工程角度:研发质量模型,对检测到人脸质量进行评价,质量较差则不识别/检验。
2. 应用角度:施加场景限制,比如刷脸解锁,人脸闸机,会场签到时,都要求用户在良好的光照条件下正对摄像头,以避免采集到质量差的图片。
3. 算法角度:提升人脸识别模型性能,在训练数据里添加更多复杂场景和质量的照片,以增强模型的抗干扰能力。
总而言之,人脸识别/深度学习还远未达到人们想象的那般智能。希望各位读者看完第一节后,有能力分辨社交网络,自媒体上的信息真伪,更理性的看待人工智能,给它时间和包容,慢慢成长。
02
科研领域近期进展
这部分将从两个思路跟进现代人脸识别算法:
思路1:Metric Learning: Contrastive Loss, Triplet loss 及相关 sampling method。
思路2:Margin Based Classification: 包含 Softmax with Center loss, Sphereface, NormFace, AM-softmax (CosFace) 和 ArcFace.
关键字:DeepID2, Facenet, Center loss, Triplet loss, Contrastive Loss, Sampling method, Sphereface, Additive Margin Softmax (CosFace), ArcFace.
▌思路1:Metric Learning
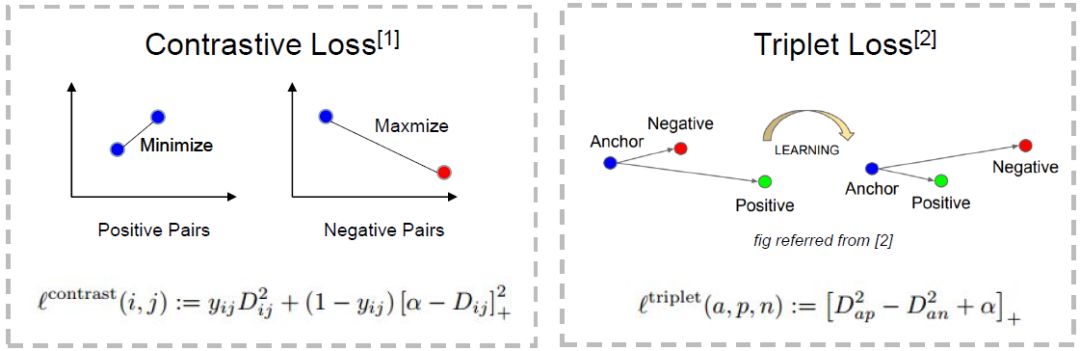
Contrastive Loss
基于深度学习的人脸识别领域最先应用 Metric Learning 思想之一的便是 DeepID2 [2] 了,同 Chapter 1 的思想,“特征”在这篇文章中被称为“DeepID Vector”。
DeepID2 在同一个网络同时训练 Verification 和 Classification(即有两个监督信号)。其中 Verification Loss 便在特征层引入了 Contrastive Loss。
Contrastive Loss 本质上是使同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值 m(听起来和 Triplet Loss 很像)。
基于这样的 insight,DeepID2 在训练的时候不是以一张图片为单位了,而是以 Image Pair 为单位,每次输入两张图片,为同一人则 Verification Label 为 1,不是同一人则 Label 为 -1,参数更新思路见下面公式(截自 DeepID2 论文):

DeepID2 在 14 年是人脸领域非常有影响力的工作,也掀起了在人脸领域引进 Metric Learning 的浪潮。
Triplet Loss from FaceNet
这篇 15 年来自 Google 的 FaceNet 同样是人脸识别领域的分水岭性工作。不仅仅因为他们成功应用了 Triplet Loss 在 benchmark 上取得 state-of-art 的结果,更因为他们提出了一个绝大部分人脸问题的统一解决框架,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。
为此,Google 在 DeepID2 的基础上,抛弃了分类层即 Classification Loss,将 Contrastive Loss 改进为 Triplet Loss,只为了一个目的:学到更好的 feature。
Triplet Loss 的思想也很简单,输入不再是 Image Pair,而是三张图片(Triplet),分别为 Anchor Face,Negative Face 和 Positive Face。Anchor 与 Positive Face 为同一人,与 Negative Face 为不同人。那么 Triplet Loss 的损失即可表示为:
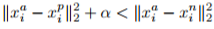
直观解释为:在特征空间里 Anchor 与 Positive 的距离要小于 Anchor 与 Negative 的距离超过一个 Margin Alpha。
有了良好的人脸特征空间,人脸问题便转换成了 Chapter 1 末尾形容的那样简单直观。附上一张我制作的 Contrastive Loss 和 Triplet Loss 的 PPT:
Metric Learning 的问题
基于 Contrastive Loss 和 Triplet Loss 的 Metric Learning 符合人的认知规律,在实际应用中也取得了不错的效果,但是它有非常致命的两个问题,使应用它们的时候犹如 pain in the ass。
1. 模型需要很很很很很很很很很很很很很很长时间才能拟合(months mentioned in FaceNet paper),Contrastive Loss 和 Triplet Loss 的训练样本都基于 pair 或者 triplet 的,可能的样本数是 O (N2) 或者 O (N3) 的。
当训练集很大时,基本不可能遍历到所有可能的样本(或能提供足够梯度额的样本),所以一般来说需要很长时间拟合。我在 10000 人,500,000 张左右的亚洲数据集上花了近一个月才拟合。
2. 模型好坏很依赖训练数据的 Sample 方式,理想的 Sample 方式不仅能提升算法最后的性能,更能略微加快训练速度。
关于这两个问题也有很多学者进行了后续研究,下面的内容作为 Metric Learning 的延伸阅读,不会很详细。
Metric Learning 延伸阅读
1. Deep Face Recognition [3]
为了加速 Triplet Loss 的训练,这篇文章先用传统的 softmax 训练人脸识别模型,因为 Classficiation 信号的强监督特性,模型会很快拟合(通常小于 2 天,快的话几个小时)。
之后移除顶层的 Classificiation Layer,用 Triplet Loss 对模型进行特征层 finetune,取得了不错的效果。此外这篇论文还发布了人脸数据集 VGG-Face。
2. In Defense of the Triplet Loss for Person Re-Identification [4]
这篇文章提出了三个非常有意思的观点:
作者说实验中,平方后的欧几里得距离(Squared Euclidean Distance)表现不如开方后的真实欧几里得距离(Non-squared Euclidean Distance),直白来说就是把下图公式中的平方摘掉。
提出了 Soft-Margin 损失公式替代原始的 Triplet Loss 表达式。
引进了 Batch Hard Sampling。
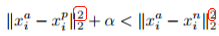
3. Sampling Matters in Deep Embedding Learning [5]
这篇文章提出了两个有价值的点:
从导函数角度解释了为什么第 2 点中提到的 Non-squared Distance 比 Squared-distance 好,并在这个 insight 基础上提出了 Margin Based Loss(本质还是 Triplet Loss 的 variant,见下图,图片取自原文)。
提出了 Distance Weighted Sampling。文章说 FaceNet 中的 Semi-hard Sampling,Deep Face Recognition [3] 中的 Random Hard 和 [4] 中提到的 Batch Hard 都不能轻易取到会产生大梯度(大 loss,即对模型训练有帮助的 triplets),然后从统计学的视角使用了 Distance Weighted Sampling Method。

4. 我的实验感想
2、3 点中提到的方式在试验中都应用过,直观感受是 Soft-Margin 和Margin Based Loss 都比原始的 Triplet Loss 好用,但是 Margin Based Loss 实验中更优越。
Distance Weighted Sampling Method 没有明显提升。
延伸阅读中有提到大家感兴趣的论文,可参考 reference 查看原文。最后,值得注意的是,Triplet Loss 在行人重识别领域也取得了不错的效果,虽然很可能未来会被 Margin Based Classfication 打败。
▌思路2:Margin Based Classification
顾名思义,Margin Based Classficiation 不像在 feature 层直接计算损失的 Metric Learning 那样,对 feature 加直观的强限制,而是依然把人脸识别当 classification 任务进行训练,通过对 softmax 公式的改造,间接实现了对 feature 层施加 margin 的限制,使网络最后得到的 feature 更 discriminative。
这部分先从 Sphereface [6] 说起。
Sphereface
先跟随作者的 insight 理下思路(图截自原文):

图 (a) 是用原始 softmax 损失函数训练出来的特征,图 (b) 是归一化的特征。不难发现在 softmax 的特征从角度上来看有 latent 分布。
那么为何不直接去优化角度呢?如果把分类层的权重归一化,并且不考虑偏置的话,就得到了改进后的损失函数:
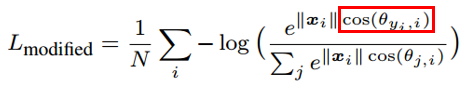
不难看出,对于特征 x_i,该损失函数优化的方向是使得其向该类别 y_i 中心靠近,并且远离其他的类别中心。这个目标跟人脸识别目标是一致的,最小化类内距离并且最大化类间距离。
然而为了保证人脸比对的正确性,还要保证最大类内距离还要小于最小类间距离。上面的损失函数并不能保证这一点。所以作者引入了 margin 的思想,这跟 Triples Loss 里面引入 Margin Alpha 的思想是一致的。
那么作者是如何进一步改进上式,引入 margin 的呢?
上式红框中是样本特征与类中心的余弦值,我们的目标是缩小样本特征与类中心的角度,即增大这个值。换句话说,如果这个值越小,损失函数值越大,即我们对偏离优化目标的惩罚越大。
也就是说,这样就能进一步的缩小类内距离和增大类间距离,达到我们的目标。基于这样的思想最终的损失函数为如下:
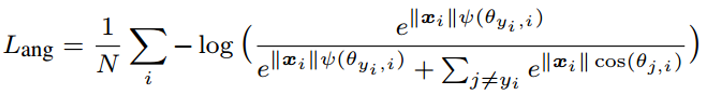
原始的 cos(θ) 被换成了 phi(θ),phi(θ) 的最简单形式其实是 cos(mθ),之所以在原文中变得复杂,只是为了将定义域扩展到 [0,2π] 上,并保证在定义域内单调递减。
而这个 m 便是增加的 margin 系数。当 m=1 时,phi(θ) 等于 cos(θ),当 m>1 时,phi 变小,损失变大。超参 m 控制着惩罚力度,m 越大,惩罚力度越大。
为计算方便,m 一般设为整数。作者从数学上证明了,m>=3 就能保证最大类内距离小于最小类间距离。实现的时候使用倍角公式。
另外:Sphereface 的训练很 tricky,关于其训练细节,这篇文章并没有提到,而是参考了作者前一篇文章 [10]。有关训练细节读者也可以去作者 Github 上去寻找,issues 里面有很多讨论。
Normface
Sphereface 效果很好,但是它不优美。在测试阶段,Sphereface 通过特征间的余弦值来衡量相似性,即以角度为相似性的度量。
但在训练阶段,不知道读者有没有注意到,其实 Sphereface 的损失函数并不是在直接优化特征与类中心的角度,而是优化特征与类中心的角度在乘上一个特征的长度。
也就是说,我在上文中关于 Sphereface 损失函数优化方向的表述是不严谨的,其实优化的方向还有一部分是去增大特征的长度去了。
我在 MNIST 数据集上做过实验,以下图片分别为 m=1 和 m=4 时的特征可视化,注意坐标的尺度,就能验证上述观点。

然而特征的长度在我们使用模型的时候是没有帮助的。这就造成了 training 跟 test 之间目标不一致,按照 Normface 作者原话说就是存在一个 gap。
于是 Normface 的核心思想就出来了:为何在训练的时候不把特征也做归一化处理?相应的损失函数如下:
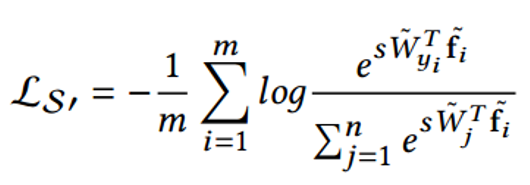
其中 W 是归一化的权重,f_i 是归一化的特征,两个点积就是角度余弦值。参数 s 的引入是因为数学上的性质,保证了梯度大小的合理性,原文中有比较直观的解释,这里不是重点。
如果没有 s 训练将无法收敛。关于 s 的设置,可以把它设为可学习的参数。但是作者更推荐把它当做超参数,其值根据分类类别多少有相应的推荐值,这部分原文 appendix 里有公式。
文章中还有指出一点,FaceNet 中归一化特征的欧式距离,和余弦距离其实是统一的。还有关于权重与特征的归一化,这篇文章有很多有意思的探讨,有兴趣的读者建议阅读原文。
AM-softmax [11] / CosFace [12]
这两篇文章是同一个东西。Normface 用特征归一化解决了 Sphereface 训练和测试不一致的问题。但是却没有了 margin 的意味。AM-softmax 可以说是在 Normface 的基础上引入了 margin。直接上损失函数:
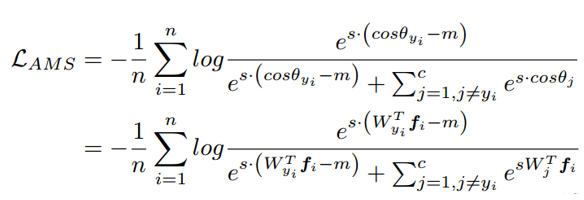
其中这里的权重和特征都是归一化的。
直观上来看,cos(θ)-m 比 cos(θ) 更小,所以损失函数值比 Normface 里的更大,因此有了 margin 的感觉。
m 是一个超参数,控制惩罚的力度,m 越大,惩罚越强。作者推荐 m=0.35。这里引入 margin 的方式比 Sphereface 中的‘温柔’,不仅容易复现,没有很多调参的 tricks,效果也很好。
ArcFace [13]
与 AM-softmax 相比,区别在于 Arcface 引入 margin 的方式不同,损失函数:

乍一看是不是和 AM-softmax一样?注意 m 是在余弦里面。文章指出基于上式优化得到的特征间的 boundary 更为优越,具有更强的几何解释。
然而这样引入 margin 是否会有问题?仔细想 cos(θ+m) 是否一定比 cos(θ) 小?
最后我们用文章中的图来解释这个问题,并且也由此做一个本章 Margin-based Classification 部分的总结。
▌小结
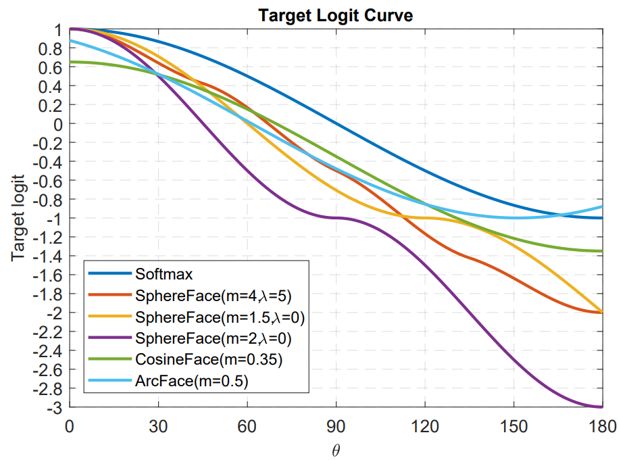
这幅图出自于 Arcface,横坐标为 θ 为特征与类中心的角度,纵坐标为损失函数分子指数部分的值(不考虑 s),其值越小损失函数越大。
看了这么多基于分类的人脸识别论文,相信你也有种感觉,大家似乎都在损失函数上做文章,或者更具体一点,大家都是在讨论如何设计上图的 Target logit-θ 曲线。
这个曲线意味着你要如何优化偏离目标的样本,或者说,根据偏离目标的程度,要给予多大的惩罚。两点总结:
1. 太强的约束不容易泛化。例如 Sphereface 的损失函数在 m=3 或 4 的时候能满足类内最大距离小于类间最小距离的要求。此时损失函数值很大,即 target logits 很小。但并不意味着能泛化到训练集以外的样本。施加太强的约束反而会降低模型性能,且训练不易收敛。
2. 选择优化什么样的样本很重要。Arcface 文章中指出,给予 θ∈[60° , 90°] 的样本过多惩罚可能会导致训练不收敛。优化 θ ∈ [30° , 60°] 的样本可能会提高模型准确率,而过分优化 θ∈[0° , 30°] 的样本则不会带来明显提升。至于更大角度的样本,偏离目标太远,强行优化很有可能会降低模型性能。
这也回答了上一节留下的疑问,上图曲线 Arcface 后面是上升的,这无关紧要甚至还有好处。因为优化大角度的 hard sample 可能没有好处。这和 FaceNet 中对于样本选择的 semi-hard 策略是一个道理。
▌Margin based classification 延伸阅读
1. A discriminative feature learning approach for deep face recognition [14]
提出了 center loss,加权整合进原始的 softmax loss。通过维护一个欧式空间类中心,缩小类内距离,增强特征的 discriminative power。
2. Large-margin softmax loss for convolutional neural networks [10]
Sphereface 作者的前一篇文章,未归一化权重,在 softmax loss 中引入了 margin。里面也涉及到 Sphereface 的训练细节。
注:思路二由陈超撰写
03
实验及细节
基于前两章的知识,我在 lfw 上取得了 99.47% 的结果,这个结果训练在 Vggface2 上,未与 lfw 去重,也没经历很痛苦的调参过程,算是 AM-softmax 损失函数直接带来的收益吧。
过程中踩了很多坑,这一章将把前段时间的实验结果和心得做一个整理,此外也将回答绝大部分工程师在做人脸识别时最关心的一些问题。やりましょう!
项目地址:
https://github.com/Joker316701882/Additive-Margin-Softmax
包含代码可以复现所有实验结果
一个标准的人脸识别系统包含这几个环节:人脸检测及特征点检测->人脸对齐->人脸识别。
▌人脸检测 & Landmark检测
目前最流行的人脸及 Landmark 检测是 MTCNN [7],但是 MTCNN 一方面偶尔检测不到 face,一方面 Landmark 检测不够精准。这两点都会给后续的对齐和识别带来不利影响。
另外在 COCO Loss [8] 论文里提到:好的检测和对齐方法,仅用 softmax 就能达到 99.75%,秒杀目前大多数最新论文的结果。COCO Loss 的 Github issue [16] 里提到了更多细节。
此外,因为 alignment 算法性能的区别,2017 年及以后的论文更加注重相对实验结果的比较,以排除 alignment 算法引入的优劣势,方便更直观比较各家的人脸识别算法,lfw 上轻松能达到 99% 以上也是现在更倾向于采用相对结果的原因。
▌人脸对齐
人脸对齐做的是将检测到的脸和 Landmark 通过几何变换,将五官变换到图中相对固定的位置,提供较强的先验。
广泛使用的对齐方法为 Similarity Transformation。更多对其变换方法和实验可以参考这篇知乎文章 [17]。
作者代码实现:
https://github.com/Joker316701882/Additive-Margin-Softmax/blob/master/align/align_lfw.py
值得探讨的一个问题是:人脸检测和对齐真的有必要吗?现实应用中常出现人脸 Landmark 无法检测的情况,没有 Landmark 就无法使用 Similarity Transoformation。
针对这个问题也有相关研究,通过使用 Spatial Transform Network [9] “让网络自己学习 alignment”,论文参考 End-to-End Spatial Transform Face Detection and Recognition。这方面的研究进展还不充分,所以实际系统中多数情况下还是使用了 detection->alignment 这套流程。
▌人脸识别
可以说人脸识别的项目中绝大部分问题都是人脸检测和对齐的问题。识别模型之间的差距倒没有那么明显。不过训练 AM-softmax 过程中依然碰到了些值得注意的问题。
Spheraface 里提出的 Resface20,AM-softmax 中也同样使用,一模一样复现情况下在 lfw 上只能达到 94%。
TensorFlow 中能拟合的情况为如下配置:
Adam, no weight decay, use batch normalization.
对应原文配置:
Momentum, weight decay, no batch normalization.
以及在实验中发现的: 除了 Adam 以外的任何一个 optimizer 都达不到理想效果,这可能是不同框架底层实现有所区别的原因,Sphereface,、AM-softmax都是基于 Caffe,本文所有实验全使用 TensorFlow,结论有区别也算正常。
另一点,Sandberg FaceNet 中的 resnet-inception-v1 搬过来套用 AM-softmax 在 lfw 上的结果达不到 97%,这是过程中不太理解的点。
从其他论文里看,如果 loss 选的没问题,那诸如 resnet-inception,不同深度的 Resnet,甚至 Mobile-net,Squeezenet 等结构的表现也不该有明显差距(AM-softmax 的情况下至少也该达到99%)。
此外,直接套用 Arcface 也无法拟合,需要进一步实验。
最后,关于 Sandberg 的 code 中一个值得关注的点,他将 train_op 定义在了 facenet.train() 函数里,仔细阅读这个函数会发现,Sandberg 的代码中所有网络参数并不是采用每次更新梯度后的值,而是采用滑动平均值作为网络实际的参数值。
也正是因为这个原因,解释了 Sandberg 在 batch_norm 的参数 configuration中,甚至没把”is_training”的值交给 placeholder,而是默认 train 和 test 时都采用 local statistics 的模式。
如果不是因为所有参数都用了滑动平均,那么这种使用 batch_norm 的做法其实是错误的。Sandberg 这样实现的好坏只能交给实验结果来评判了。
如果想正常使用网络参数和 batch norm,而不是用滑动平均参数和全程开着“is_training”,只需要将 facenet.train() 函数替换成普通的 Optimizer,然后将 batch_norm的“is_training”交给 placeholder 处理,详细可以参考我的 AM-softmax 实现。

感谢大家坚持阅读到最后,以 TensorBoard 的 plot 作为结尾吧!

参考文献
[1] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proc. CVPR, 2015.
[2] Y. Sun, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. CoRR, abs/1406.4773, 2014.
[3] O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. In BMVC, 2015
[4] A. Hermans, L. Beyer, and B. Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017
[5] Wu, C. Manmatha, R. Smola, A. J. and Krahenb uhl, P. 2017. Sampling matters in deep embedding learning. arXiv preprint arXiv:1706.07567
[6] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017
[7] Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multi-task cascaded convolutional networks. arXiv preprint, 2016
[8] Yu Liu, Hongyang Li, and Xiaogang Wang. 2017. Learning Deep Features via Congenerous Cosine Loss for Person Recognition. arXiv preprint arXiv:1702.06890, 2017
[9] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.
[10] W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional neural networks. In ICML, 2016.
[11] F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. In arXiv:1801.05599, 2018.
[12] CosFace: Large Margin Cosine Loss for Deep Face Recognition
[13] Deng, J., Guo, J., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: Arxiv preprint. 2018
[14] Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discriminative feature learning approach for deep face recognition. In ECCV, 2016.
[15] Y. Liu, H. Li, and X. Wang. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv:1710.00870, 2017.
[16] https://github.com/sciencefans/coco_loss/issues/9
[17] https://zhuanlan.zhihu.com/p/29515986
扫描二维码,关注「人工智能头条」
回复“秘籍”获取 吴恩达机器学习训练秘籍前19章英文版




