教程 | 如何构建自定义人脸识别数据集
选自pyimagesearch
作者:Adrian Rosebrock
机器之心编译
参与:Geek AI、路
本文介绍了构建自定义人脸识别数据集的三种方法:使用 OpenCV 和 webcam 工具收集人脸图像数据;以编程的方式下载人脸图像;手动收集人脸图像。
在接下来的几篇博文中,作者将带领大家训练一个「计算机视觉+深度学习」的模型来执行人脸识别任务。但是,要想训练出能够识别图像或视频流中人脸的模型,我们首先得收集人脸图像的数据集。
如果你使用的是「Labeled Faces in the Wild」(LFW)这样预先准备好的数据集,那么你可以不用进行这项困难的工作了。你可以使用我们下一篇博文中的方法创建自己的人脸识别应用。
然而,对于大多数人来说,我们希望识别出的人脸往往不包含在任何现有数据集中,例如:我们自己的、朋友的、家人或者同事的人脸图像。
为了完成这个任务,我们需要收集我们想要识别的人脸样本,并且以某种方式量化它们。
这个过程通常被称为「人脸识别注册」(facial recognition enrollment)。我们称之为「注册」是因为在这个过程中,我们会将用户注册、登记为我们的数据集和应用中的一个真人样本。
本文将介绍注册过程的第一步:创建自定义人脸识别数据集。
如何创建自定义人脸识别数据集
本教程中,我们将介绍 3 种创建自定义人脸识别数据集的方法。第一种方法使用 OpenCV 和 webcam 工具完成两个任务:(1)在视频中检测出人脸;(2)将人脸图像或视频帧的样本保存到磁盘上。
第二种方法将讨论如何以编程的方式下载人脸图像。
最后,我们将讨论如何手动收集人脸图像,以及这种方法何时是适用的。
让我们开始构建人脸识别数据集吧!
方法 1:通过 OpenCV 和 webcam 进行人脸注册
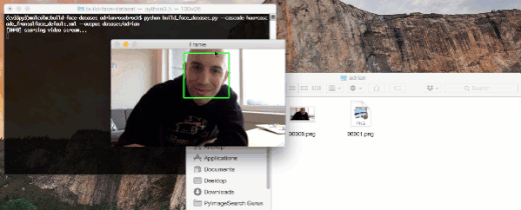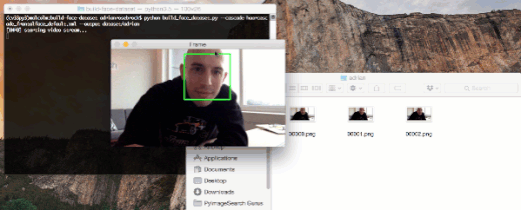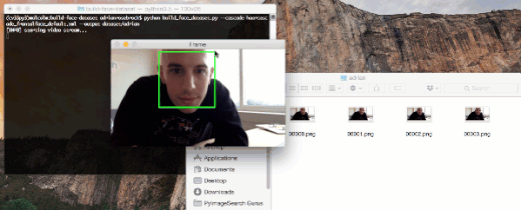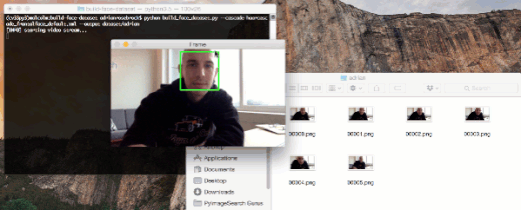
图 1:通过使用 OpenCV 和 webcam,我们可以检测出视频流中的人脸,并且将样本存储到磁盘上。这个过程可用于创建一个本地人脸识别数据集。
这种方法适用于以下情况:
1. 你要创建一个」能现场使用的」人脸识别系统;
2. 你需要拥有接触特定人的物理途径,以收集他们的人脸图像数据。
这样的系统尤其适用于公司、学校或者其他人们每天亲自出现在现场的组织。
为了收集这些人的人脸图像样本,我们可能需要将他们置于一个特殊的房间中,房间中事先安装好了视频摄影机,用于:(1)检测视频流中人脸的 (x, y) 坐标;(2)将包含用户人脸的视频帧写入磁盘。我们可能甚至需要好几天或者几周的时间执行上述操作,以收集下列几种情况下的人脸样本:
不同的光照条件
一天中不同的时间
不同的情绪和情感状态
通过收集不同情况下的人脸样本,我们可以创建一个更加多样化、更具代表性的特定用户人脸图像数据集。
接下来,我们使用一个简单的 Python 脚本构建自定义人脸识别数据集。这个 Python 脚本可以完成以下任务:
1. 连接到我们的 webcam;
2. 检测人脸;
3. 将包含人脸的视频帧写入磁盘。
想要获取本文中使用的代码,请滚动到本文的「Downloads」部分。
准备好之后,请打开 build_face_dataset.py 文件,然后我们来一步一步解读这份代码:
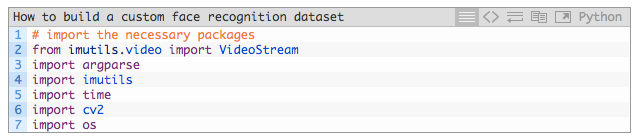
在 2-7 行中,我们导入了所需程序包。尤其是我们所需要的 Opencv 和 imutils 包。安装 Opencv 的方法请参考我提供的这篇安装指南(https://www.pyimagesearch.com/opencv-tutorials-resources-guides/)。而 imutils 包则可以很容易地通过 pip 工具进行安装或升级:
$ pip install --upgrade imutils如果你使用的是 Python 虚拟环境,请不要忘记使用 workon 命令!
环境安装好之后,我们接下来将讨论两个需要用到的命令行参数:
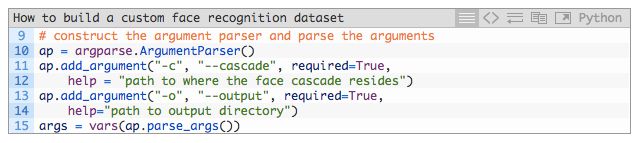
命令行参数会在运行时被一个名为 argparse 的程序包(这个程序包会在安装 Python 环境时被自动安装)解析。如果你对于 argparse 和命令行参数不太熟悉,我强烈推荐你迅速浏览这篇博文(https://www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/)。
我们有两个需要用到的命令行参数:
--cascade:哈尔级联(Haar cascade)文件在磁盘上的路径。
--output:输出文件夹的路径。人脸图像会被存储在这个文件夹中,因此我推荐你用人脸主人的名字来命名这个文件夹。例如,如果你收集的是「John Smith」的人脸图像,你可以将所有的图片存放在 dataset/john_smith 文件夹中。
下面,我们将加载人脸的哈尔级联文件并且初始化视频流:
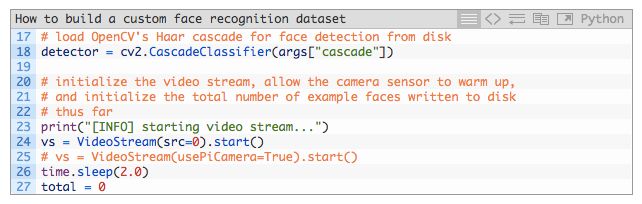
在第 18 行中,我们加载了 OpenCV 的哈尔级联 detector。这个 detector 会在接下来的逐帧循环中完成繁重的任务。
我们在第 24 行初始化并开始我们的视频流。
注意:如果你使用的是树莓派,请注释掉第 24 行,并且取消第 25 行的注释。
为了让摄像头预热,我们简单地将程序暂停 2 秒(第 26 行)。
我们还初始化了一个计数器 total,用于表示在磁盘上存储的人脸图像数量(第 27 行)。
现在让我们在视频流上进行逐帧循环:
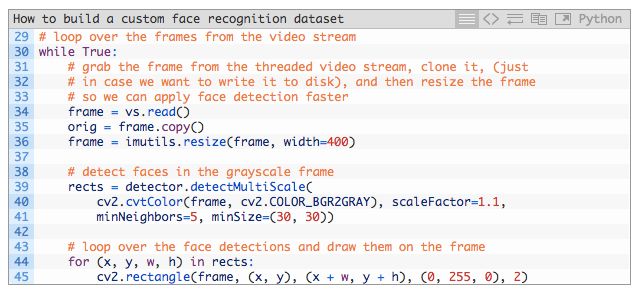
在第 30 行中,我们开始循环(按下「q」键则退出循环)。
从这一行起,我们获取了一个视频帧 frame,创建了该帧的一个副本,并且改变了图像的尺寸(第 34-36 行)。
现在,是时候执行人脸检测了!
我们可以使用 detectMultiScale 方法检测视频帧 frame 中的人脸。该函数需要用到下列参数:
image:一个灰度图;
scaleFactor:指定在每个尺度上,图像缩小多少;
minNeighbor:为了保证检测的有效性,该参数指定每一个候选矩形边界框需要有多少相邻的检测点;
minSize:可能的最小图片尺寸。
不幸的是,有时我们需要对这种方法进行调优,以消除误判或者检测出一张完整的人脸,但是对于「近距离」拍摄的人脸图像的检测来说,这些参数是一个很好的起点。
话虽如此,你是否也在寻找一种更加先进、更加可靠的方法呢?在之前的博文中(https://www.pyimagesearch.com/2018/02/26/face-detection-with-opencv-and-deep-learning/),我用 OpenCV 和深度学习实现了人脸检测。你可以通过文章中使用了预训练模型的深度学习方法很容易地更新本文中的脚本。该方法的好处是,不用调参并且训练十分快。
这种人脸识别方法的结果是一个 rects(矩形边界框)列表。在第 44、45 行中,我们在 rects 上进行循环,并且在帧上画出矩形边框,以方便展示。
最后一步,我们将在循环中进行两个工作:(1)在屏幕上展示视频帧;(2)处理按键响应。具体代码如下:
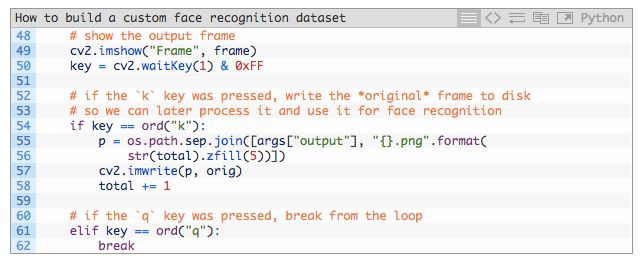
在第 48 行中,我们在屏幕上展示了视频帧,接下来在第 49 行中获取了键入值。
根据按下的是「k」还是「q」,我们会:
如果按下「k」键,我们将保留视频帧并将它存储到磁盘上(第 53-56 行),并且增加表示获取到的总帧数的计数器 total(第 58 行)。我们需要在想保留的每一帧处按下「k」键。我建议保留不同角度、不同的帧区域、戴/不戴眼镜等不同情况下拍摄的人脸图像。
如果按下「q」键,则退出循环,准备退出脚本(quit)。
如果没有按下任何键,我们就回到循环的开头,从视频流中获取一帧。
最终我们将在终端上打印出最终存储的图像数量,并进行清理:

现在让我们运行脚本,收集人脸图像吧!
请确保你已经从本文的「Downloads」部分下载了代码和哈尔级联。
在你的终端设备中执行下列命令:
$ python build_face_dataset.py --cascade haarcascade_frontalface_default.xml \
--output dataset/adrian
[INFO] starting video stream...
[INFO] 6 face images stored
[INFO] cleaning up...在运行完脚本之后,我们发现有 6 张图像被存储到了 dataset 文件夹的 adrian 子文件夹中:
$ ls dataset/adrian
00000.png 00002.png 00004.png
00001.png 00003.png 00005.png我建议将人脸图像样本存在以图像所属人的名字命名的子文件夹中。
通过这种方式可以强化你的自定义人脸识别数据集的组织结构。
方法 2:通过编程下载人脸图像
图 2:另一种构建人脸识别数据集的方法(如果此人是公众人物,或者在网络上出现过),是通过一个脚本在谷歌上进行图像搜索,或者使用一个利用了 Bing 图像搜索 API 的 Python 脚本。
如果你不能在现场拍摄一个人的图像,或者他们是在网络上存在感很强的公众人物(在某种程度上),你可以通过各种平台上的 API 以编程的方式下载他们的人脸图像样本。选择哪种 API 很大程度上取决于你想要收集的是谁的人脸图像。
例如,如果一个人一直在 Twitter 或 Instagram 上发帖,你可能想要用其中一种(或者其他的)社交网络 API 获取人脸图像。
另一种选择是,使用像谷歌或 Bing 这样的搜索引擎:
使用这篇文章中的方法(https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/),你可以使用谷歌图像「Google Images」手动+编程地为给定的查询下载示例图像。
在我看来,一个更好的选择可能是,使用 Bing 的图像搜索 API,它是完全自动化的且不需要手动干预。我在这篇文章中实现了这个全自动化方法(https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/)。
使用后一种方法,我可以从《侏罗纪公园》和《侏罗纪世界》中下载 218 张人脸图像。
通过 Bing 图像搜索 API 下载 Owen Grady 的人脸图像的命令示例如下:
$ mkdir dataset/owen_grady
$ python search_bing_api.py --query "owen grady" --output dataset/owen_grady
现在让我们来看整个数据集(删除不包含该人物人脸的图像后):
$ tree jp_dataset --filelimit 10
jp_dataset
├── alan_grant [22 entries]
├── claire_dearing [53 entries]
├── ellie_sattler [31 entries]
├── ian_malcolm [41 entries]
├── john_hammond [36 entries]
└── owen_grady [35 entries]
6 directories, 0 files在短短 20 多分钟内(包括删除误判样本的时间),我就能收集到《侏罗纪公园》/《侏罗纪世界》的自定义人脸数据集:

图 3:通过 Python 和 Bing 图像搜索 API 以编程的方式创建出的人脸识别数据集示例。图中是《侏罗纪公园》系列电影中的六个人物。
方法 3:手动收集人脸图像
图 4:手动下载人脸图像是最不可取的选项,但你不该忘记它。当一个人并不经常在网络上出现,或者图像没有标签时,你可以使用这种方法。
最后一种创建自定义人脸识别数据集的方法也是最不可取的一种,是手动寻找并存储人脸图像样本。
这种方法显然是最乏味的,且需要耗费最多的人工工作时间——通常我们更喜欢「自动化」的解决方案,但是在某些情况下,你不得不付诸人工。
使用此方法,你需要手动检查:
搜索引擎的搜索结果(例如,谷歌和 Bing)
社交网络资料(Facebook、Twitter、Instagram、SnapChat 等)
图片分享服务(Google Photos、Flickr 等)
然后手动将这些图像存储到磁盘上。
在这些场景下,用户通常具备某种类型的公开资料,但是比以编程的方式用爬虫爬到的图像要少得多。
PyImageSearch Gurus(免费)示范课程
图 5:在 PyImageSearch Gurus 课程(https://www.pyimagesearch.com/pyimagesearch-gurus/)中,你将学会构建人脸识别安防系统。当一个未经授权的入侵者坐在你的桌前时,它会通过文本消息(包含图像)提醒你。
总结
本文介绍了三种为人脸识别任务创建自定义人脸数据集的方法。
你具体会选择哪种方法完全取决于你自己的人脸识别应用。
如果你正在构建一个「现场」的人脸识别系统,例如用于教室、公司或其他组织的人脸识别系统,你可能会让用户进入专门用于收集示例人脸图像的房间,然后在那里继续从视频流中捕获人脸图像 (方法 1)。
另一方面,如果你正在构建一个包含公众人物、名人、运动员等的人脸识别系统,那么在网上可能有他们足够多的人脸图像样本。在这种情况下,你可以利用现有的 API 以编程方式下载人脸图像样本 (方法 2)。
最后,如果你试图识别的面孔在网上没有公开的个人资料(或者个人资料非常有限),你可能需要手动收集和管理人脸数据集 (方法 3)。这显然是最人工、最繁琐的方法,但在某些情况下,如果你想识别某些面孔,可能需要使用这种方法。

原文链接:https://www.pyimagesearch.com/2018/06/11/how-to-build-a-custom-face-recognition-dataset/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





