AI综述专栏 | 步态识别的深度学习综述
AI综述专栏简介
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
导读
步态是人在行走过程中姿态的变化.不同于人脸、指纹、虹膜等, 步态是唯一可在远距离非受控状态下获得的生物特征.心理学证据表明, 每个人的步态存在一定的差异, 因此可用于身份的鉴别.步态识别指利用步态信息对人的身份进行识别的技术.近年来, 随着视频监控设备在机场、车站、商场的普及, 步态识别在社会安全、市场营销、生物认证、视频监控和法律援助等领域逐渐发挥重要的作用.因此, 有必要就近年来步态识别的新进展进行全面综述.
作者简介
张军平教授是复旦大学计算机科学技术学院,教授、博士生导师,中国自动化学会混合智能专委会副主任。主要研究方向包括人工智能、机器学习、图像处理、生物认证及智能交通。曾于2007.9-2008.3年作为访问学者访问加州大学圣地亚哥校,2014.8-2015.8年作为访问学者和Research Associate访问宾夕法尼亚州立大学。曾主持3个国家自然科学基金、863项目和教育部博士点基金各一项,参与国家自然基金重点一项,也是973项目“数字媒体理解的理论和方法研究”的主要参加人之一。目前主持国家自然基金面上项目一项和浦江人才计划一项。张教授发表论文近100篇,包括TPAMI, TNNLS, ToC, PR, ICML, ECCV等高档次期刊和会议,学术谷歌引用2400余次。

当前关于步态识别方面的研究综述主要围绕在相关手工特征建模和传统机器学习(非深度学习)的识别算法上.钟兴志等[2]综述步态的运动分割与分类、基于模型的特征抽取及基于模板匹配和统计方法的识别算法.王科俊等[3]围绕运动检测、周期检测、特征提取和识别算法4方面进行综述.Lü 等[4]对常用的步态模板进行详细的介绍与实验对比.贲晛烨等[5]从视频流的角度分析识别方法, 综述步态识别中的特征融合方法与研究现状.陈昌由等[6]对早期步态识别中的特征抽取方法进行详细的整理与总结.值得指出的是, 随着近年来深度学习的发展, 步态识别在识别准确率和模型鲁棒性上都具有大幅度的提升.因此, 不同于已有的综述[2, 3, 4, 5, 6], 本文将从深度学习的角度综述步态识别领域近期的进展、优势和不足, 对比和总结相关的识别算法.
1 问题定义
步态识别任务包括计算机视觉领域内多个基本研究方向.对于一段给定的包含一个或多个行人行走过程的视频序列, 广义上的步态识别流程可以分为4个主要阶段:行人检测、行人分割、行人追踪和行人识别.行人检测阶段定位行人在单帧图像中的位置, 确定行人大小.行人分割阶段针对行人检测结果进行像素级的分割并去除视频中的背景信息.行人追踪阶段确定目标的运动轨迹, 区分视频序列中的不同个体.一般意义上的步态识别, 即指行人识别阶段, 利用从行人轮廓图序列中提取特征对人进行身份辨认.近年来伴随着深度学习的发展, 通用检测分割框架, 如掩码区域卷积神经网络(Mask Region-Based Convolutional Neural Network, Mask RCNN)[7]等的提出使步态识别技术运用到实际的复杂场景中成为可能.
除了上述的步态识别流程, 也有直接利用前背景分离技术[8]剔除步态序列中的背景, 然后再进行行人追踪与识别的方法.使用前背景分离技术能获得比直接进行检测、分割更好质量的轮廓图, 但该方法只适用于视频中背景保持不变的场景.还有使用姿态估计算法[9, 10]提取视频帧中的人体关键点, 并利用关键点序列中的运动信息进行识别的方法.
图1展示上述步态识别任务的流程图.本文主要集中论述流程图中行人识别阶段的相关算法.

步态识别任务可以根据任务目标分为两类.第一类为验证(Verification)任务, 给定注册样本(Probe Sample)xp和验证样本(Gallery Sample)xg, 依据某种相似度指标或给定的阈值判断它们是否具有相同身份.第二类为辨别(Identification)任务, 即给定注册样本xp和验证(Gallery Set)中N个样本
2 常用数据集
步态数据集在收集同一个人在不同状态下的行走视频序列时, 需要测试者在协作的情况下进行, 这导致采集的困难.而验证步态算法和模型的有效性依赖于合适的步态数据集, 并且数据集中包含的对象数量对于深度学习而言也尤为关键.目前, 常用于验证基于深度学习的步态识别方法有效性的数据集包括:日本大阪大学的ISIR数据集(包括MVLP[11], LP[12]及LP-Bag β [13]3个常用子数据集)、中国科学院的CASIA-B数据集[14]、美国南佛罗里达大学的USF数据集[15].表1总结常用的步态数据集.
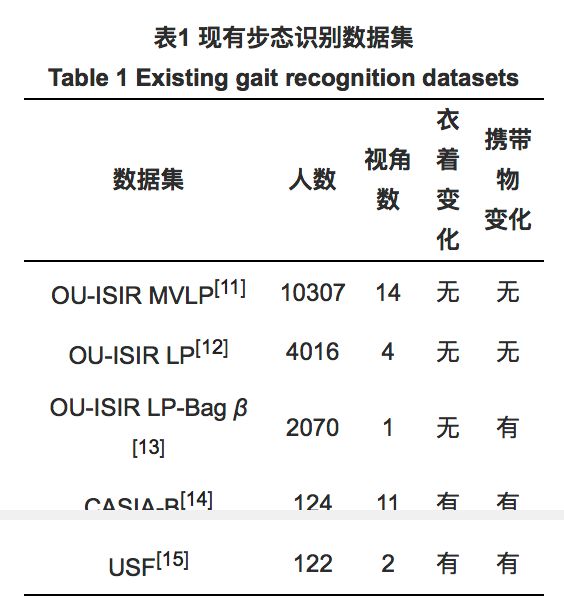
由于人在行走过程中可能处于各种不同的状态, 现有的步态识别数据集为了保证能够对算法进行有效评估, 引入视角、衣着和携带物等协变量.本节将以这3种协变量为切入点介绍常用的步态数据集.
2.1 视角变化
摄像头视角变化会极大改变行人在行走过程中整体的外观.对于同一个人在不同视角下的步态序列, 如何通过有效的算法判断其是否具有相同的身份是当前步态识别领域研究的一个热点问题.现阶段常用的数据集采用将多个相机固定在不同位置的方式进行数据采集, 因此数据集会提供同一个人在多个固定视角下的步态序列.CASIA-B作为常用的多视角步态数据集, 提供11种不同视角(0° ~180° )下的数据, 视角变化范围较大.OU-ISIR LP提供4种不同视角(55° ~85° )下的数据, 相比CASIA-B数据集, 视角变化范围较小.OU-ISIR MVLP作为多视角数据集, 提供目前为止最全面的视角覆盖, 达到14种不同的视角.需要注意的是, 当前多视角数据集中的角度定义并未考虑摄像头高度的变化.
2.2 衣着变化
由于同一个人在不同的行走序列中可能会身着不同服装, 因此提取出的步态轮廓图在外观上会出现较大差异.算法在该种情况下难以提取步态中的动态信息进行身份辨认.在CASIA-B数据集中除了不穿外套时的步态序列(NM01-NM06)外, 还采集行人在身着外套时的步态序列(CL01-CL02).已有的研究结果[14]表明, 当注册样本身着外套、验证集为正常行走的步态序列时, 识别准确率会出现显著下降.此外, USF数据集也提供一组鞋子类型变化的步态序列以验证其变化对识别性能的影响.
2.3 携带物变化
当人在行走过程中携带物品时, 背景建模技术无法将人本身和携带的物品进行有效分离, 导致提取的轮廓图形状发生变化.此外, 由于携带物品导致的整体重心改变也会影响人的行走姿态, 正常行走状态下有效的识别算法在这种情况下就会失去健壮性.CASIA-B数据集中, 在每个视角下都提供2组带着包行走的步态序列(BG01-BG02).
3 步态识别方法概览
Nixon等[16]提出使用步态进行行人识别.在早期的研究中, 步态识别主要从2个角度展开:1)从轮廓图序列中手工提取与步态相关的静态或动态特征, 并利用机器学习的方法对特征进行降维或匹配[16, 17, 18, 19, 20, 21]; 2)直接通过步态轮廓图构造保持步态序列中时间与空间信息的模板[1, 22, 23, 24], 利用机器学习方法学习具有判别力的表示.步态能量图[1]和步态熵图[22]是2种常用的步态模板, 它们计算复杂度较低, 有效保持步态序列中的空间信息, 但丢失时序信息.为了解决该问题, Wang等[23]和Liu等[24]分别提出可以有效保持步态中时序信息的步态模板.
近年来关于步态识别的研究工作主要以步态模板为输入, 围绕如何从中提取具有身份信息的特征进行展开.由于行人的步态容易受到多种协变量影响而发生变化, 身份特征的提取因此会变得相当具有挑战性.其中会影响步态识别性能的协变量包括:相机视角、衣着[25]、行走速度[26]、物体遮挡[27]和分辨率[28]等.
相机与行人的相对视角是对步态识别性能影响最大的协变量.较大的视角变化会使处在不同视角下的步态特征间存在高度的非线性相关性.为了解决视角变化的问题, 机器学习识别方法[29]通过学习投影的方式将处于不同视角下的步态模板投影到一个视角无关的公共子空间中进行识别.Bashi等[30]使用典型相关分析学习针对特定视角的投影矩阵.Hu等[31]挖掘数据的低维几何结构, 学习视角无关的判别投影矩阵.Xing等[32]为了解决主成分分析与典型相关分析投影方向不一致的问题, 提出完全典型相关分析方法.
除了上述基于学习投影的方法, 已有的文献中也存在通过将步态模板从一个视角转化至另一个视角进行识别的方法.视角变换模型(View Transform Model)[33]最早提出的对步态模板进行视角变换的工作.在此基础上, 后续方法进行有效改进, 如引入支持向量回归对非线性相关性建模[34]或使用优化的步态能量图[35]等.
基于浅层模型的传统方法虽然在一定程度上缓解各种协变量的影响, 但对于解决不同视角下步态特征之间的高度非线性相关性依然缺乏有效的建模手段.此外, 早期提出的步态模板始终无法完整保存步态序列中的时空信息, 而机器学习方法又缺乏对序列数据的端到端建模能力.近年来, 深度学习技术由于具有强大的模型预测能力, 已成为计算机视觉和图像处理领域通用的技术.以卷积神经网络和递归神经网络为基础的模型也提供对图像和序列数据进行特征抽取的有效方式[36, 37].步态识别作为以图像序列为输入的任务, 在一定程度上也适合运用深度学习方法进行建模.基于神经网络的非线性模型也给消除步态识别中协变量的影响提供有效的解决手段.
4 基于深度学习的步态识别方法
近年来涌现出不少利用深度神经网络进行步态识别的研究工作.本节依据文献[11]中的划分方式将现有的基于深度学习的步态识别方法分成判别式方法和生成式方法2类, 并分别介绍每类方法.
4.1 判别式方法
给定一段步态序列样本或步态模板x, 步态识别中的判别式方法可以分为2类.第1类为学习特征表示的方法.该类方法利用基于深度神经网络的特征学习网络建模投影f, 得到低维欧氏空间中x的协变量无关的特征表示z=f(x).利用学习到的特征表示z, 该类方法使用k近邻分类器在验证集中找到与z距离最近的样本.由于可以直接保存验证集中样本的低维特征, 在进行特征匹配时计算量较小, 适用于聚类或检索任务.第2类为学习样本间的相似度函数C(xp, xg), xp为注册样本, xg为验证样本.该类方法将步态识别问题看成二分类问题, 即判断一个二元组步态序列是否来自于同一个对象.相比学习特征表示的方法, 该类方法需要在网络中进行二元组的特征融合, 因此在评估时计算复杂度较高.该类方法的优点是可以直接根据学到的相似度进行一对一的身份验证.图2给出判别式方法可能的训练架构图.
4.1.1 基于预训练模型的方法
Zhang等[38]提出深度步态(DeepGait), 利用预训练模型VGG-16(Visual Geometry Group-16)[39]得到基于步态轮廓图的深度卷积特征表示.首先通过提取轮廓图序列中的感兴趣区域(Region of Interest, RoI)得到规范化后的轮廓图序列.然后利用提出的步态周期检测方法对轮廓图序列进行周期检测.最后, 将单个周期的轮廓图作为基于图像网络数据集(ImageNet Dataset)[40]预训练的VGG-16模型的输入, 获得一组对应序列长度的特征表示.基于该组特征表示, 通过如下最大池化操作计算用于识别的深度步态特征[37]:
z=maxfc6k,
其中 fc6k为步态周期中的第k帧在VGG-16第1个全连接层的输出.得到步态特征表示后, 利用归一化后的负欧氏距离作为相似度进行匹配[37]:
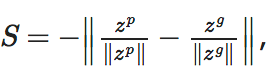
其中, ‖ · ‖ 表示l2范数, zp表示注册样本, zg表示验证样本.基于预训练模型的方法在无视角变化的情况下对步态图像具有一定的泛化能力, 但在跨视角场景及协变量变化时无法有效提取具有判别力的特征.
4.1.2 基于步态能量图网络的方法
不同于直接将步态轮廓图作为深度网络的输入, Shiraga等[41]使用步态能量图作为模型输入.步态能量图是一种混合步态轮廓图序列中静态和动态信息的步态模板, 通过计算一个步态周期中轮廓图像素的平均强度得到模板中每个像素的能量[1]:

其中, N为单个步态周期的帧数, Bt为步态周期中第t帧的轮廓图.为了解决步态识别中的跨视角问题, 提出一个带有两层卷积层的网络结构, 通过一个全连接层得到视角不变的特征表示.在训练过程中, 将识别问题看成是训练数据集上的分类问题, 在网络的最后一层使用softmax函数计算多分类的交叉熵损失.在测试阶段, 利用得到的视角不变的特征, 使用最近邻分类器进行识别.
4.1.3 基于3D卷积的方法
Wolf等[42]提出利用3D卷积[43]捕捉步态序列中的时空信息, 使用多视角3D卷积网络(Multi-view 3D Convolutional Neural Network, MV3DCNN)将具有灰度信息的步态图像序列作为网络输入, 并引入光流图像[44]处理衣着及颜色对识别性能的影响.为了解决卷积网络无法处理不定长步态序列的问题, 将一个步态序列切分成若干个固定长度的短序列进行处理.
Thapar等[45]也使用3D卷积对步态轮廓图序列进行特征抽取.与Wolf等[42]不同的是, 对于一段步态序列, 该方法首先通过一个视角分类器预测步态序列的视角, 然后根据预测视角选择一个对应的3D卷积网络进行识别.与Wolf等[42]相同的是, 该方法也将一个步态序列切分成固定长的短序列.在测试阶段, 可以得到对应每个短序列的身份估计, 最后以多数表决的方式判断原始步态序列的身份.
4.1.4 基于度量学习的方法
Takemura等[11]利用基于输入/输出架构的卷积神经网络(Input/Output Architectures Convolution-
al Neural Network, I/O-ACNN)分析不同的网络结构和损失函数对步态识别准确率的影响, 使用步态能量图作为模型输入.对于损失函数, 对比度量学习中常用的二元组损失(Contrastive Loss)[46]和三元组损失(Triplet Loss)[47].二元组损失定义为[11]
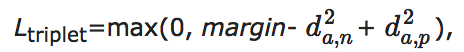
其中:δ i, j为指示函数, 表示训练集中第i个和第j个样本是否具有相同的身份, 如果相同值为1, 否则为0; di, j为特征之间的欧氏距离.该损失函数对于相同身份的样本最小化特征之间的距离, 对于不同身份的样本, 令特征之间的距离大于某一个阈值margin.
三元组损失定义为[11]

其中, da, n表示具有不同身份的特征之间的距离, da, p表示具有相同身份的特征之间的欧氏距离.为了分析步态识别中类内和类间样本空间不对齐问题对步态识别性能的影响, 文献[11]方法对比2种模型结构:1)在模型的输入层上进行求绝对差运算, 即在输入层进行特征融合; 2)直接在网络结构的高层学习特征表示.文献[11]方法的优势在于提出融合不同网络结构的方法, 可以同时适用于验证和辨别任务.
4.1.5 基于人体姿态关键点的方法
Liao等[48]利用开源的姿态估计算法[10]从原始的视频序列中提取人体的姿态信息, 其中包含6个人体关键点(左右臀部、左右膝盖和左右脚踝)在原始视频序列中每一帧的位置.为了消除相机与人的距离在行走过程中尺度变化的影响, 首先对每个关键点的坐标进行规范化处理[48]:
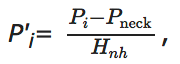
其中, Pi为第i个关键点的坐标, Pneck为人体脖颈处关键点的坐标, Hnh为臀部中心位置到脖子处的高度.在得到规范化的步态关键点序列后, 提出使用基于姿态的时空网络(Pose-Based Temporal-Spatial Network, PTSN)学习步态特征表示.具体地, 利用卷积神经网络提取关键点序列中的空间信息, 利用长短时记忆模块(Long Short-Term Memory, LSTM)[49]提取时间信息.LSTM已经证明可以有效建模序列数据[50, 51].对于损失函数的选择, 同时使用多分类交叉熵损失和二元组损失, 以加权求和的方式训练模型.
现有的姿态估计算法对于自遮挡、衣着和携带物变化具有较高的容忍性.相比使用步态图像, 利用姿态关键点进行步态识别可以有效缓解协变量变化对步态识别性能的影响.但缺点之一是未能在跨视角的场景下验证模型的有效性.
4.1.6 基于相似度学习的方法
Wu等[52]提出通过深度卷积神经网络(Deep Convolutional Neural Networks, DeepCNNs)直接学习步态能量图或步态序列之间的相似度, 提出的相似度预测模型可以简洁定义为
S=C(g(f(xp), f(xg))),
其中:xp为注册样本, xg为验证样本; 投影f由一组或多组卷积层构成, 将样本投影至一个公共子空间; 运算g计算网络输入的绝对差, 结构也可以包含卷积层或全连接层; 分类器C用于预测样本对的相似度.在训练阶段, 使用二分类交叉熵损失作为模型的目标函数.依据上述公式, 设计3种不同的预测模型用于验证模型结构对步态识别性能的影响.除此以外, 在实验阶段, 分别就组稀疏技术、输入像素的大小、输入的步态模板、数据增强、时间信息等因素的影响进行详细分析.引入3D卷积和特征集成技术, 提取步态序列中的时间信息, 在单模型上取得较高的识别准确率.
Chen等[53]同样提出使用卷积神经网络学习样本间的相似度.不同于Wu等[52]将步态能量图作为输入或使用3D卷积抽取时间信息, 该方法将网络分为3个子模块:特征卷积网络(Feature Convolutional Neural Network, fCNN)、映射卷积网络(Mapping Convolutional Neural Network, mCNN)和全连接层.在fCNN模块, 将单帧的步态轮廓图及前后两帧轮廓图之间的差作为模块输入.在时间维度上对特征图进行最大池化(Feature Map Pooling, FMP)操作, 去除相邻帧之间信息的高度冗余.该模块能在处理变长序列的情况下融合步态序列中的时间信息.在mCNN模块, 以fCNN模块输出的特征图作为输入, 计算2个特征图的绝对差后再进行卷积操作, 得到一个相似向量表示, 最后通过全连接层计算相似度.
4.2 生成式方法
步态识别的生成式方法将某种状态下输入的步态特征变换到另一种状态下再进行匹配或特征抽取.以跨视角场景下的步态识别为例, 生成式方法首先将各种不同视角下的步态特征通过编码器进行编码, 然后通过一个特征变换网络将编码后的特征变换到一个典型视角或某个验证集视角, 最后通过解码器对变换后的特征进行重构.图3为生成式方法的训练架构图.

4.2.1 基于长短时记忆模块和人体关节热图的方法
Feng等[54]提出利用基于姿态的长短时记忆模块(Pose-Based LSTM, PLSTM)对人体关节热图序列进行端到端的重构.首先使用基于卷积神经网络的人体姿态估计模型[55]得到人体12个关节点的热图, 并以此作为LSTM模块的输入.在编码阶段, 把LSTM最后一个时间戳的输出作为该步态序列的特征表示.在解码阶段, 通过重构另一视角的步态序列处理视角变化的问题.利用姿态估计方法的优势在于人体关节热图对于衣着变化等协变量的影响小于步态轮廓图.劣势在于单个模型只能得到两种视角下视角不变的特征表示, 无法对三个及三个以上视角下的步态序列同时进行建模.
4.2.2 基于生成对抗网络的方法
Yu等[56]提出的基于步态生成对抗网络(Gait Generative Adversarial Network, GaitGAN)的方法能够同时缓解视角、衣着等协变量对识别性能的影响.生成对抗网络已经证明可用于对样本分布进行有效拟合[57, 58].GaitGAN主要由编码器、生成器及2个具备不同功能的判别器组成.其中编码器以任意视角或行走状态下的步态能量图作为输入, 得到具有身份信息的隐表示.生成器以隐表示为输入, 输出侧面视角下正常行走的步态能量图.为了保证生成器能够生成真实的步态图像, 第一种判别器DR以单幅步态图像作为输入, 并将对应判别器的损失函数定义为[56]
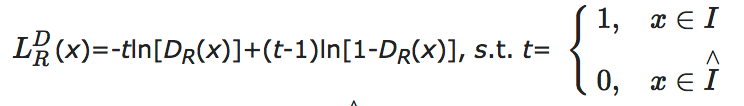
其中, I为真实步态图像的集合,
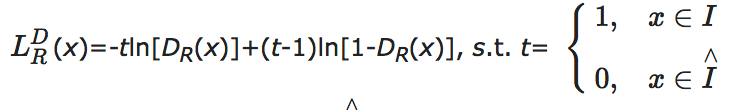
其中, xS为变换前的原始图像, IT为具有和xS相同身份的侧面视角图像集合, 
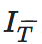
4.2.3 基于多层自编码器的方法
传统的生成式方法需要提前估计步态序列相对摄像头的角度, 且对于每对角度都需要分别训练一个模型进行识别, 缺乏在真实场景中的使用价值.
为了提高生成式的方法在步态识别中的实用性, Yu等[60]提出基于多层自编码器(AutoEncoder)的统一模型, 缓解步态识别中的视角、衣着、携带物等协变量改变对识别性能的影响.该模型使用步态能量图作为多层自编码器中每层的输入及重构对象.前二层编码器以任意行走状态的步态能量图为输入, 依次重构不受衣着和携带物影响的步态能量图.之后每层中, 对输入的步态能量图进行逐步式的视角变换, 即每层解决一个相对小的视角变化.通过这种方式, 在网络的最后一层重构侧面视角下的步态图像.在训练阶段, 首先独立训练每层自编码器的参数.训练完成后, 优化器再对整个网络的参数进行微调.在测试阶段, 以拼接模型后三层的隐特征作为视角不变的特征表示进行识别.
文献[60]方法在一定程度上提高生成式方法的实际应用价值, 但只能解决在多个不同的水平视角下进行步态识别的问题, 无法处理视角的高度变化.
5 现有基于深度学习的工作对比
为了对比现有的基于深度学习的工作, 表2和表3分别整理CASIA-B和OU-ISIR LP数据集上的结果.需要注意的是, 当前基于深度学习的方法对于输入特征及训练/测试数据集的划分并不统一, 部分方法[41, 60]使用步态能量图作为输入, 而另一些方法[43, 48, 52]直接使用关键点或轮廓图序列作为输入.对于数据集的划分, 当前常用的步态数据集并未提供固定的训练集和测试集, 因此各方法实验中的划分方式会存在差异.对于实验结果的报道, 本文提供已有方法在各数据集上的平均rank-1准确率作为参考.对于非跨视角的步态识别方法, 平均rank-1准确率为相同视角下识别准确率的平均.而对于跨视角场景下的方法, 平均rank-1准确率为所有视角对下准确率的平均.本节就各种方法的类型、输入特征、训练/测试数据划分、使用场景(是否跨视角)和评估方式在表2和表3中进行注明.现有的大部分基于深度学习的方法主要提出用于解决步态识别中的跨视角问题.DeepCNNs[52]和I/O-ACNN[11]分别在CASIA-B和OU-ISIR LP数据集上取得较高的识别准确率.虽然这些工作提出的模型有效缓解视角变化对步态识别性能的影响, 但对于其它协变量如衣着和携带物依然缺乏足够的鲁棒性.


Liao等[48]提出的基于人体姿态关键点的方法有效缓解协变量对识别性能的影响, 但由于姿态估计算法本身的误差和关键点特征的维数较低等原因, 学习到的特征表示中无法包含足够的身份信息.
生成式方法[56, 60]对协变量变化进行显式的建模, 思想来源于早期提出的视角变换模型[33].对于视角变化, 该类方法可以通过重构某个典型视角或验证集视角下的步态特征进行识别.为了消除衣着等协变量影响, 该类方法可以重构正常行走的步态特征.由于生成式方法的目标函数通常定义为重构损失, 与判别式方法具有较大的差异性, 因此通过这类方法学习到的步态特征并不能保证足够的判别性.
6 未来可能的研究方向
虽然近年来随着深度学习的发展, 步态识别的准确率已经具有较大提升, 但在该领域仍然存在一些需要解决的问题.为了更好地将步态识别运用到实际应用中, 本节总结当前研究过程中存在的一些问题及未来可能的研究方向.
1)对于序列数据的建模.机器学习方法为了降低模型的计算复杂度, 选择使用特征维数低于步态轮廓图序列的步态模板作为模型输入, 但是现有的步态模板通常会造成步态序列中时间与空间信息的丢失.直接对序列数据进行建模的方法(文献[52]和文献[54]中都有涉及)将变长序列分割成若干个短序列以抽取多个特征, 但是, 对多个特征进行平均池化的操作会丢失变长序列中完整的步态信息.虽然Feng等[54]使用长短时记忆模块解决变长序列的问题, 但在识别准确率上的提升有限, 因此如何有效处理变长序列, 提取步态中的时序信息值得进一步的研究.
此外, 现有的处理步态序列数据的方法多为离线算法.在实际的视频监控场景中, 紧急预警对算法的实时性可能存在要求, 因此, 挖掘合适的在线识别算法也具有一定的应用价值.
2)借鉴行人再识别与人脸识别中的方法.当前基于深度学习的步态识别方法中使用的损失函数最早在人脸识别和行人再识别中提出, 如三元组损失[47].因此后续的工作可以从人脸识别的相关工作中挖掘更多的可以用于步态识别的技术, 并进行有效改进使其适用于步态数据.行人再识别利用计算机视觉技术判断视频或图像中是否存在特定行人.与步态识别的区别在于, 行人再识别研究并不会分割原始图像, 从而保留衣着颜色和背景信息.因此, 行人再识别中的特征提取方式与步态识别可能存在差异.但是, 同样作为对图像或视频的检索问题, 行人再识别在模型和目标函数的选择上具有一定的借鉴价值.
3)结合步态轮廓图与人体关键点.人体姿态估计算法是计算机视觉领域的一个热点研究方向.现有工作[9]已经可以有效处理人体姿态关键点的自遮挡, 做到实时的运算效率.Liao等[48]也将提取的人体关键点用于步态识别.该工作虽然在有衣着变化和物体遮挡的情况下已被验证有效性, 但并未扩展到跨视角的场景.因此, 一个有意义的研究方向是探索如何有效结合步态轮廓图与人体关键点两种特征, 在保证识别准确率的同时增强模型对于视角、衣着、物体遮挡等因素的鲁棒性.
4)多模态识别.随着生物认证技术对可靠性要求的进一步提高, 单一模态的生物特征已经无法满足需求.多模态生物认证技术作为一种新兴的互补式生物认证方式, 可以有效缓解在单模态识别场景下的可靠性问题.通过将步态与人脸、指纹和虹膜等其它生物特征进行有效融合, 多模态识别能够有效提高生物认证的可靠性, 具有较强的研究价值.
5)数据集与实验设置标准化.在现有的步态数据集上, 评估模型或算法的有效性仍然缺乏统一的实验标准.对比相同实验设置下的识别准确率不仅需要提前定义训练集与测试集的对象数量, 还需要考虑注册集与验证集的划分方式.已有的工作存在实验设置与数据集划分不一致的问题, 对实验结果的评估与对比造成困难.因此, 对数据集和实验设置进行标准化也是一个值得研究的方向.
为了方便对不同算法进行性能评估, 后续步态数据集的增加可以考虑提前划分训练集和测试集.对于测试集, 应尽可能地再进行注册集和验证集的划分, 并设置易复现的基线算法进行评估.评估度量可选择使用首位命中率(Rank-1 Accuracy)和均值平均精度(Mean Average Precision, mAP)等.在数据集的采集方面可参考行人再识别问题中相关的数据集, 如Mars数据集[61]等.
6)步态识别在其它任务上的扩展.需要指出的是, 本文综述内容主要来自狭义的步态识别.从广义的角度上看, 步态识别不仅包括对行人身份进行认证的技术, 相关工作也可以扩展到其它领域, 如使用步态进行年龄估计[62]与性别识别[63, 64]等.此外, 步态识别用于疾病和健康监测已有十余年的历史.通过对步态进行测量得到的相关指标可用于评估人体的健康状态、进行运动分析或用于对疾病的评估与预防等[65, 66].
7 结 束 语
本文从判别式和生成式的角度出发, 对当前步态识别领域中基于深度学习方法的相关文献进行综述.不同于传统的步态识别方法, 基于深度学习的步态识别通常能取得更高的性能指标, 学到的模型对于协变量的变化也更具有鲁棒性.除此以外, 本文也探讨一些未来可能的研究方向, 包括对数据集及实验设置标准化的展望等.
The authors have declared that no competing interests exist.
引用本文格式:何逸炜,张军平. 步态识别的深度学习:综述. 模式识别与人工智能, 2018, 31(5), 442-452
参考文献
文献选项
HAN J, BHANU B. Individual Recognition Using Gait Energy Image. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 28(2): 316-322. [本文引用:4]
钟兴志 ,王晨升 ,刘丰 ,等 .步态识别综述 . 软件,2013 ,34 (4 ):160 -164 .
( [本文引用:2]ZHONG X Z WANG C S LIU F et al .A Survey of Gait Recognition . Software,2013 ,34 (4 ):160 -164 . )王科俊 ,侯本博 .步态识别综述 . 中国图象图形学报,2007 ,12 (7 ):1152 -1160 .
( [本文引用:2]WANG K J HOU B B A Survey of Gait Recognition . Journal of Image and Graphics,2007 ,12 (7 ):1152 -1160 . )LÜ Z W, XING X L, WANG K J, et al. Class Energy Image Analysis for Video Sensor-Based Gait Recognition: A Review. Sensors, 2015, 15(1): 932-964. [本文引用:2]
贲晛烨 , 徐森 , 王科俊 . 行人步态的特征表达及识别综述 . 模式识别 与人工智能, 2012 , 25 ( 1 ): 71 - 81 .
( BEN X Y , XU S , WANG K J , et al . Review on Pedestrian Gait Feature Expression and Rec ognition . Pattern Recognition and Artificial Intelligence, 2012 , 25 ( 1 ): 71 - 81 . ) [本文引用:2] 陈昌由, 张军平. 步态识别的特征提取综述. 计算机研究与发展, 2007, 44(S2): 361-365. (CHEN C Y, ZHANG J P. A Survey of Feature Extraction on Gait Recognition. Journal of Computer Research and Development, 2007, 44(S2): 361-365 ) [本文引用:2] HE K M , GEORGIA G , PIOTR D , et al . Mask R-CNN // Proc of the IEEE International Conference on Computer Vision. Washington, USA : IEEE , 2017 : 2980 - 2988 . [本文引用:1] BOYKOV Y Y , JOLLY M P . Interactive Graph Cuts for Optimal Boundary and Region Segmentation of Objects in N-D Images // Proc of the 8th IEEE International Conference on Computer Vision. Washington, USAUSA : IEEE , 2001 : 105 - 112 . [本文引用:1] BULAT A , TZIMIROPOULOS G . Human Pose Estimation via Convo-lutional Part Heatmap Regression // Proc of the European Confe-rence on Computer Vision. Berlin, Germany : Springer , 2016 : 717 - 732 . [本文引用:2] CAO Z , SIMON T , WEI S E , et al . Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2017 : 1302 - 1310 . [本文引用:2] TAKEMURA N , MAKIHARA Y , MURAMATSU D , et al . On Input/Output Architectures for Convolutional Neural Network-Based Cross-View Gait Recognition . IEEE Transactions on Circuits and Systems for Video Technology, 2018 . DOI DOI:10.1109/TCSVT.2017.2760835 . [本文引用:8] IWAMA H , OKUMURA M , MAHIKARA Y , et al . The OU-ISIR Gait Database Comprising the Large Population Dataset and Performance Evaluation of Gait Recognition . IEEE Transactions on Information Forensics and Security , 2012 , 7 ( 5 ): 1511 - 1521 . [本文引用:1] MAKIHA RA Y , SUZUKI A , MURAMA TSU D , et al . Joi nt In t ensity and Spatial Metric Learning for Robust Gait Recognition // Proc of the IEEE Conference on Computer Vision and Pattern Re-cognition. Washington, USA : IEEE , 2017 : 6786 - 6796 . [本文引用:1] YU S Q , TAN D L , TAN T N . A Framework for Evaluating the Effect of View Angle, Clothing and Carrying Condition on Gait Recognition // Proc of the IEEE International Conference on Pa-ttern Recognition. Washington. USA : IEEE , 2006 : 441 - 444 . [本文引用:2] SARKAR S , PHILLIPS P J , LIU Z Y , et al . The HumanID Gait Challenge Problem: Data Sets, Performance, and Analysis . IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005 , 27 ( 2 ): 162 - 177 . [本文引用:1] NIXON M S , CATER J N , CUNADO D , et al . Automatic Gait Recognition . Motion Analysis and Tracking, 1999 , 7 ( 2 ): 3 - 6 . [本文引用:2] WANG L , TAN T N , NING H Z , et al . Silhouette Analysis-Based Gait Recognition for Human Identification . IEEE Transactions on Pattern Analysis and Machine Intelligence , 2003 , 25 ( 12 ): 1505 - 1518 . [本文引用:1] WANG L , TAN T N , HU W M , et al . Automatic Gait Recognition Based on Statistical Shape Analysis . IEEE Transactions on Imag , 2003 , 12 ( 9 ): 1120 - 1131 . [本文引用:1] WANG L , NING H Z , TAN T N , et al. Fusion of Static and Dynamic Body Biometrics for Gait Recognition . IEEE Transactions on Circuits and Systems for Video Technology , 2004 , 14 ( 2 ): 149 - 158 . [本文引用:1] HAYFRON-ACQUAH J B , NIXON M S , CARTER J N . Automa-tic Gait Recognition by Symmetry Analysis . Pattern Recognition Letters , 2003 , 24 ( 13 ): 2175 - 2183 . [本文引用:1] BOBICK A F , JOHNSON A K . Gait Recognition Using Static, Activity-Specific Parameters // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2001 : 423 - 430 . [本文引用:1] BASHIR K , XIANG T , GONG S . Gait Recognition Using Gait Entropy Image // Proc of the International Conference on Crime Detection and Prevention. London, UK : IET , 2010 . DOI: DOI:10.1049/ic.2009.0230 . [本文引用:2] WANG C , ZHANG J P , WANG L , et al . Hu man Identification Using Temporal Information Preserving Gait Template . IEEE Transactions on Pattern Analysis and Machine Intelligence , 2012 , 34 ( 11 ): 2164 - 2176 . [本文引用:2] LIU J Y , ZHENG N N . Gait History Image: A Novel Temporal Template for Gait Recognition // Proc of the IEEE International Conference on Multimedia and Expo. Washington, USA : IEEE , 2007 : 663 - 666 . [本文引用:2] GUAN Y , LI C T , HU Y J . Robust Clothing-Invariant Gait Recognition // Proc of the 8th IEEE International Conference on Intelligent Information Hiding and Multimedia Signal Processing. Wa-shington, USA : IEEE , 2012 : 321 - 324 . [本文引用:1] HUANG S , ELGAMMAL A , LU J W , et al . Cross-Speed Gait Recognition Using Speed-Invariant Gait Templates and Globality-Locality Preserving Projections . IEEE Transactions on Information Forensics and Security, 2015 , 10 ( 10 ): 2071 - 2083 . [本文引用:1] SINGH S , BISWAS K K . Biometric Gait Recognition with Carrying and Clothing Variants // Proc of the 3rd International Conference on Pa ttern Recognition and Machine Intelligence. Berlin, Germany : Springer , 2009 : 446 - 451 . [本文引用:1] ZHANG J P , PU J , CHEN C Y . Low-Resolution Gait Recognition. IEEE Transactions on Systems, Man, and Cybernetics(Cyberne-tics) , 2010 , 40 ( 4 ): 986 - 996 . [本文引用:1] KUSAKUNNIRAN W , WU Q , ZHANG J , et al . Recognizing Gaits Across Views through Correlated Motion Co-clustering . IEEE Transactions on Image Processing , 2014 , 23 ( 2 ): 696 - 709 . [本文引用:1] BASHI K , XIANG T , GONG S G . Cross View Gait Recognition Using Correlation Strength // Proc of the British Machine Vision Conference. London, UK : BMVA , 2010 : 1 - 11 . [本文引用:1] HU M D , WANG Y H , ZHANG Z X , et al . View-Invariant Discriminative Projection for Multi-view Gait-Based Human Identification . IEEE Transactions on Information Forensics and Security , 2013 , 8 ( 12 ): 2034 - 2045 . [本文引用:1] XING X L , WANG K J , YAN T , et al . Complete Canonical Correlation Analysis with Application to Multi-view Gait Recognition . Pattern Recognition , 2016 , 50 : 107 - 117 . [本文引用:1] MAKIHARA Y , SAGAWA R , MUKAIGAWA Y , et al . Gait Re-cognition Using a View Transformation Model in the Frequency Domain // Proc of the European Conference on Computer Vision. Berlin, Germany : Springer , 2006 , III : 151 - 163 . [本文引用:2] KUSAKUNNIRAN W , WU Q , ZHANG J , et al . Support Vector Regression for Multi-view Gait Recognition Based on Local Motion Feature Selection // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2010 : 974 - 981 . [本文引用:1] KUSAKUNNIRAN W , WU Q , LI H D , et al . Multiple Views Gait Recognition Using View Transformation Model Based on Optimized Gait Energy Image // Proc of the 12th IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2010 : 1058 - 1064 . [本文引用:1] KRIZHEVSKY A , SUTSKEVER I , HINTON G E. ImageNet Cla-ssification with Deep Convolutional Neural Networks // Proc of the 26th Annual Conference on Neural Information Processing Systems. Cambridge, USA : The MIT Press , 2012 : 1097 - 1105 . [本文引用:1] BENGIO Y , SIMARD P Y , FRASCONI P . Learning Long-Term Dependencies with Gradient Descent Is Difficult . IEEE Transactions on Neural Networks, 1994 , 5 ( 2 ): 157 - 166 . [本文引用:3] ZHANG X F , SUN S Q , LI C , et al . DeepGait: A Learning Deep Convolutional Representation for Gait Recognition // Proc of the Chinese Conference on Biometric Recognition. Berlin, Germany : Springer , 2017 : 447 - 456 . [本文引用:1] SIMONYAN K , ZISSERMAN A . Very Deep Convolutional Networks for Large-Scale Image Recognition [C/OL]. [2017-11-25]. https://arxiv.org/pdf/1409.1556.pdf . [本文引用:1] DENG J , DONG W , SOCHER R , et al . ImageNet: A Large-Scale Hierarchical Image Database // Proc of the IEEE Conference on Com puter Vision and Pattern Recognition. Washington, USA : IEEE , 2009 : 248 - 255 . [本文引用:1] SHIRAGA K , MAKIHARA Y , MURAMATSU D , et al . GEINet: View-Invariant Gait Recognition Using a Convolutional Neural Network // Proc of the International Conference on Biometrics. Wa-shington, USA : IEEE , 2016 . DOI: DOI:10.1109/ICE.2016.7550060 . [本文引用:2] WOLF T , BABAEE M , RIGOLL G . Multi-view Gait Recognition Using 3D Convolutional Neural Networks // Proc of the IEEE International Conference on Image Processing. Washington, USA : IEEE , 2016 : 4165 - 4169 . [本文引用:3] TRAN D , BOURDEV L , FERGUS R , et al . Learning Spatiotemporal Features with 3D Convolutional Networks // Proc of the IEEE International Conference on Computer Vision. Washington, USA : IEEE , 2015 : 4489 - 4497 . [本文引用:2] SUN D Q , ROTH S , BLACK M J . Secrets of Optical Flow Estimation and Their Principles // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2010 : 2432 - 2439 . [本文引用:1] THAPAR D , AGGARWAL D , AGARWAL P , et al . VGR-Net: A View Invariant Gait Recognition Network [C/OL]. [2017-10-13]. https://arxiv.org/pdf/1710.04803.pdf . [本文引用:1] HADSELL R , CHOPRA S , LECUN Y . Dimensionality Reduction by Learning an Invariant Mapping // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2006 : 1735 - 1742 . [本文引用:1] SCHROFF F , KALENICHENKO D , PHILBIN J . FaceNet: A Unified Embedding for Face Recognition and Clustering // Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA : IEEE , 2015 : 815 - 823 . [本文引用:2] LIAO R J , CAO C S , GARCIA E B , et al . Pose-Based Temporal-Spatial Network(PTSN) for Gait Recognition with Carrying and Clothing Variations // Proc of the Chinese Conference on Biometric Recognition. Berlin, Germany : Springer , 2017 : 474 - 483 . [本文引用:5] HOCHREITER S , SCHMIDHUBER J . Long Short-Term Memory . Neural Computation , 1997 , 9 ( 8 ): 1735 - 1780 . [本文引用:1] GRAVES A , MOHAMED A R , HINTON G . Speech Recognition with Deep Recurrent Neural Networks // Proc of the IEEE International Conference on Acoustics, Speech and Signal Processing. Washington, USA : IEEE , 2013 : 6645 - 6649 . [本文引用:1] SUTSKEVER I , VINYALS O , LE Q V. Sequence to Sequence Learning with Neural Networks // Proc of the 28th Annual Confe-rence on Neural Information Processing Systems. Cambridge, USA : The MIT Press , 2014 : 3104 - 3112 . [本文引用:1] WU Z F , HUANG Y Z , WANG L , et al . A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs . IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017 , 39 ( 2 ): 209 - 226 . [本文引用:5] CHEN Q , WANG Y H , LIU Z , et al . Feature Map Pooling for Cross-View Gait Recognition Based on Silhouette Sequence Images [C/OL]. [ 2017 -11-26]. https://arxiv.org/pdf/1711.0935-8.pdf . [本文引用:1] FENG Y , LI Y C , LUO J B . Learning Effective Gait Features Using LSTM // Proc of the 23rd IEEE International Conference on Pattern Recognition. Washington, USA : IEEE , 2017 : 325 - 330 . [本文引用:3] PFISTER T , CHARLES J , ZISSERMAN A . Flowing ConvNets for Human Pose Estimation in Videos // Proc of the IEEE International Conference on Computer Vision. Washington, USA : IEEE , 2016 : 1913 - 1921 . [本文引 YU S Q , CHEN H F , REYES E B G , et al . GaitGAN: Invariant Gait Feature Extraction Using Generative Adversarial Networks // Proc of the IEEE Conference on Computer Vision and Pattern Re-cognition. Washington, USA : IEEE , 2017 : 30 - 37 . [本文引用:4] MIRZA M , OSINDERO S . Conditional Generative Adversarial Nets [C/OL]. [2014-11-06]. https://arxiv.org/pdf/1411.1784.pdf . [本文引用:1] CHEN X , DUAN Y , HOUTHOOFT R , et al. InfoGAN: Interpre-table Representation Learning by Information Maximizing Generative Adversarial Nets // LEE D D, SUGIYAMA M, LUXBURG U V, et al. , eds. Advances in Neural Information Processing Systems 29. Cambridge, USA : The MIT Press , 2016 : 2172 - 2180 . [本文引用:1] YOO D , KIM N , PAR S , et al . Pixel-Level Domain Transfer // Proc of the European Conference on Computer Vision. Berlin, Germany : Springer , 2016 : 517 - 532 . [本文引用:1] YU S Q , CHEN H F , WANG Q , et al . Invariant Feature Extraction for Gait Recognition Using Only One Uniform Model . Neurocomputing , 2017 , 239 : 81 - 93 . [本文引用:4] ZHENG L , BIE Z , SUN Y F , et al . Mars: A Video Benchmark for Large-Scale Person Re-identification // Proc of the European Conference on Computer Vision. Berlin, Germany : Springer , 2016 : 868 - 884 . [本文引用:1] LU J W , TAN Y P . Gait-Based Human Age Estimation . IEEE Transactions on Information Forensics and Security , 2010 , 5 ( 4 ): 761 - 770 . [本文引用:1] YU S Q , TAN T N , HUANG K Q , et al . A Study on Gait-Based Gender Classification . IEEE Transactions on Image Processing , 2009 , 18 ( 8 ): 1905 - 1910 . [本文引用:1] EBENEZER R H P I . Robust Analytics for Video-Based Gait Biometrics. Ph. D. Dissertation . Chennai, India: Anna University, 2017 . [本文引用:1] O'SULLIVAN J D , SAID C M , DILLON L C , et al . Gait Analysis in Patients with Parkinson's Disease and Motor Fluctuations: Influence of Levodopa and Comparison with Other Measures of Motor Function . Movement Disorders , 1998 , 13 ( 6 ): 900 - 906 . [本文引用:1] MURO-DE-LA-HERRAN A , GARCIA-ZAPIRAIN B , MENDEZ-ZORRILLA A . Gait Analysis Methods: An Overview of Wearable and Non-wearable Systems, Highlighting Clinical Applications . Sensors , 2014 , 14 ( 2 ): 3362 - 3394 . [本文引用:1]

历史文章推荐:
AI综述专栏 | 脑启发的视觉计算2017年度关键进展回顾(附PPT)
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI



