直接与芯片厂商一起造 AI 框架,才能实现最高效率。
AI 芯片可以应对普通计算架构无法应对的挑战,但为了实现前所未有的加速,我们不仅需要强大的芯片,还需要深度学习框架与其一起深度融合优化。
深度学习技术爆发以来,GPU 巨头 NVIDIA 建立了从芯片、系统到算法和应用的完整体系,帮助从科技公司到工业,再到前沿科学等领域实现智能化。而在国内,也有一家公司正在发展「AI 的操作系统」,并和众多硬件厂商走出了共创的新模式。
在上周世界人工智能大会 WAIC 上,百度对自身的软硬件融合体系进行了一番介绍。
「飞桨从 2020 年开始发力 AI 芯片适配,我们为此花费了大量的精力,通过几年的深耕,我们和国内外芯片厂商深度合作,对 AI 芯片进行了全面适配。通过合作,我们能够真正地把 AI 芯片的算力发挥出来,」百度 AI 技术生态总经理马艳军介绍道。「今年,我们与芯片厂商的合作进入了共创的全新阶段。」
经过两年多的努力,市面上流行的大多 AI 芯片都已获得百度飞桨平台的原生加速,实现了业界领先的效率。
高质量的算力推动了 AI 技术应用。这些优化后的算力不仅被用在百度自身、合作方的智能化业务上,在学界和开发者群体中也受到了欢迎。
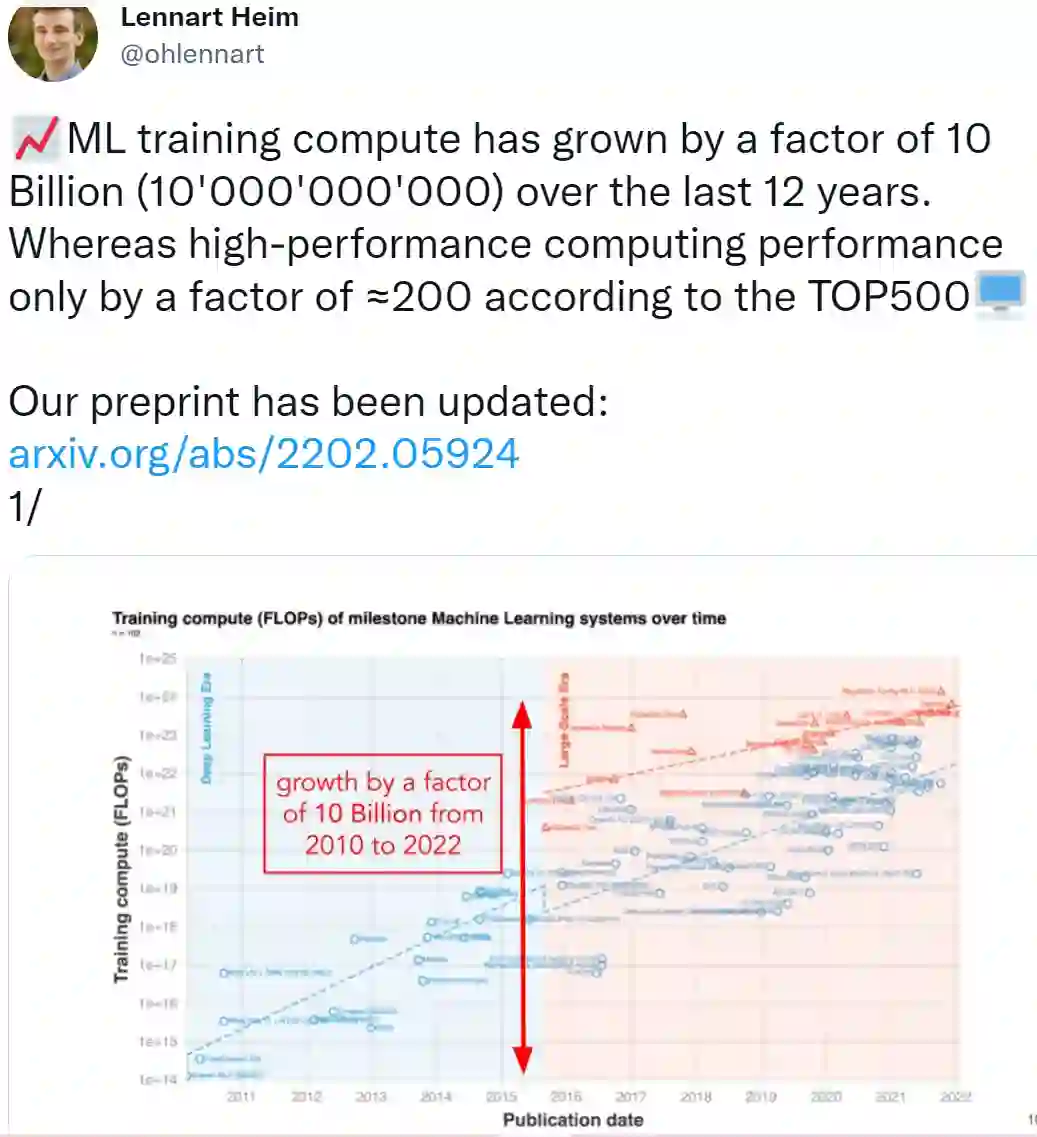
众所周知,深度学习的快速发展正在不断推动算力需求增长。有研究指出,随着 2010 年深度学习的实用化,训练 AI 所需的算力大约每 6 个月翻一番。而从 2015 年开始,因为大规模机器学习模型的出现,需求增长的速度一下子提高到了每年 10 到 100 倍。
研究者指出,在过去的 12 年里(2010-2022 年),机器学习训练算力增长了 100 亿倍。
指数级提升的算力需求让芯片厂商面临巨大挑战。人们试图通过创新架构的 AI 芯片寻求突破,然而在 PyTorch 等常用框架上,虽然项目整体开源,但因为兼容性等问题,开发团队并不接受芯片厂商的代码进入主干,这就导致很多国产 AI 硬件支持新版本框架的成本非常高,只能选择对重点版本提供支持。
百度飞桨致力于把新款 AI 芯片的代码并入主干——过去两年多以来,它一直在同硬件生态伙伴共同开发更加便捷的核心框架,构建统一的硬件接入方案。
对于 AI 框架来说,每合入一次代码都需要保证模型依然是稳定正确的,这意味着需要动用大量人力,花费大量时间验证。为此,飞桨主动邀请各家硬件厂商合作搭建了验证平台,设置专门的团队为支持芯片的每一行代码进行测试,目的只有一个:保证开发者能够方便使用。
芯片跑得动是使用的基本需求,人们能够用好 AI 芯片更需要提高效率,飞桨还能充分发挥 AI 芯片自身的设计特性。
「每款 AI 芯片都有自己的特性。针对它们的特殊能力,只有真正地与硬件核心研发团队去对接,甚至同他们共同开发框架才能实现,」马艳军说道。
在同国内、国外厂商深入合作之后,飞桨框架发挥了硬件的特性,能把这些芯片的性能发挥到极致。在性能优化上,飞桨与 NVIDIA 率先完成合作,支持 NVIDIA Tensor Core 上的结构性稀疏矩阵运算的加速能力。在特定机器学习模型的训练和推理任务中,飞桨可以充分利用硬件特性大幅提升运算速度。
6 月 30 日最新发布的国际权威 AI 基准测试榜单 MLPerf 上,百度使用飞桨框架和百度智能云百舸计算平台提交的 BERT Large 模型 GPU 训练性能结果,在同等配置下的所有提交结果中排名第一,超越了高度定制优化且长期处于榜单领先位置的 NGC PyTorch 框架,向世界展现了飞桨的性能优势。
以同 NVIDA 的合作为例,百度和更多厂商开启了联合研发的历程。所谓联合研发,就是共同打磨基础软件栈,推进硬件与飞桨的适配与性能优化工作。在这之后是技术的实践和推广,成功获得应用的技术方案会获得双方的联合授权,向生态伙伴进行推荐。除此之外,百度还会提供开发教程,向开发者带来与行业专家探讨 AI 领域最新动态的机会。
2022 年 5 月,飞桨携手 NVIDIA、英特尔、瑞芯微、Arm、Imagination 等国内外硬件厂商联合发布了「硬件生态共创计划」,结合伙伴自有软硬件基础开发栈特色,针对不同应用场景和产品共同推出定制版飞桨框架,建设开源开放模型库,开发课程与培训内容等,目标更好服务开发者。
![]()
截至目前,加入飞桨「硬件生态共创计划」的成员企业已有 17 家。
这其中包括一些人工智能芯片领域的明星企业。在 Graphcore 的专用 AI 芯片上,飞桨提供了完善的支持能力,针对其 IPU 分布式处理器与存储架构,飞桨集成了相关接口,让普通开发者也能完全利用芯片的全部性能。
同样的事情发生在很多国产芯片上,和其他框架比,飞桨原生支持更多的 AI 芯片,对于用户来说用起来更方便、速度更快。「这种定制化是不对上层用户可见的。」马艳军表示。「对于开发者来说使用的接口没变,但由于在框架和芯片这一层完成了深度定制化,把性能优化到了极致,人们可以体验到更快的速度。我们解决了框架和芯片适配的问题,从某种程度上来说,也降低了使用者应用 AI 技术的门槛。」
自 2016 年正式开源以来,百度飞桨已经让深度学习技术研发的全流程开始具备显著的标准化、自动化和模块化的工业大生产特征,门槛也在不断降低。飞桨的能力,正在帮助千行百业完成智能化升级。
在世界人工智能大会「软硬协同赋能产业未来」专题论坛中,英特尔、NVIDIA、Imagination、芯原股份、黑芝麻智能、紫光展锐、昆仑芯分别介绍了与飞桨合作的成果。
在论坛中,专家们探讨了「软硬一体赋能芯片设计」的理念。飞桨作为开源的深度学习平台,对上承接 AI 应用,对下接入智能芯片,是整个产业链中非常关键的一环。飞桨可以把开发者对于算子、模型、算力等 AI 应用落地各层面需求快速传递给 IP 厂商,并与 IP 厂商共同从产业链源头优化 AI 软件工具链设计。而这些源头的工作,将为下游的各类开发工作提供良好基础,提升芯片设计厂商乃至终端厂商开发效率。
对于芯片厂商来说,获得飞桨深度支持意味着 AI 芯片的能力可以被百万开发者应用。而在开发者看来,在充分了解芯片能力之后,如何为自己的工作选择合适的 AI 芯片也不再是个复杂的问题了。
从智能云和 C 端业务,到服务工业界的端侧 AI 和 IoT 设备,飞桨服务的生态中使用了大量不同的 AI 算力,不同类型的芯片都可以找到发挥价值的地方。
截至目前,与飞桨展开合作的国内外硬件厂商数量已超过 30 家,国内外主流的机器学习芯片基本都已适配飞桨。百度使用与芯片厂商共同研发产品的方式,已让很多不同的 AI 芯片找到了广泛应用场景。
只有更加开放、真正体现商业价值的合作才能推动生态构建。飞桨在软硬协同的探索,为领先 AI 框架的应用找准了定位。
值得一提的是,飞桨提供的能力不仅在工业界应用广泛,在学界和开发者群体中也受到了欢迎。
百度一方面提供 AI 技术,同时也是 AI 算力的大规模使用者。在公司内部,「百舸」AI 异构计算平台每月要跑 18 万个训练任务,而普通用户的每次搜索都要调用一次 AI 模型,每天需要处理 60 亿次请求。
这些需求考验着 AI 基础设施的实时响应能力,「在百度智能云深入行业数智化转型升级后,企业对于 AI 芯片的需求已经出现变化。企业使用的芯片必须足够强,否则已经无法支撑起业务需求,」马艳军说道。「在百度的一些业务中,大模型已经成为了工作流的一部分,『文心』的实践是实打实的,只要你调用接口就可以使用。」
说到大模型,我们一直以来的看法都是「用不起」。但飞桨一直在不停降低大模型应用的门槛,从大模型的训练、推理、压缩等环节上支撑文心大模型规模化生产和产业级应用。
尤其是针对学界的支持,飞桨一直在提供 AI 算力资源。据介绍,上海开设 AI 专业的高校本科有 70% 在用飞桨进行教学,其中包括上海交通大学的人工智能编程实践、复旦大学的机器学习、同济大学的计算机科学导论等课程。
在大学的 AI 课程中,飞桨提供了免费的算力及大量教学内容,甚至连预训练大模型的能力也可以通过 PaddleHub 实现「三行代码」即可调用。
「我们在 PaddleHub 上开放文心大模型以后,因为用户使用量出乎预料的增长,很快挤爆了后台服务器。」马艳军说道。「教授和学生是客观理性的群体,只有你做的东西好用,人们才会真正用起来。」
深度学习框架被认为是「智能时代的操作系统」,作为国内应用规模第一的深度学习框架和赋能平台,全球前三的人工智能开源开放生态,飞桨其已具备灵活、高效、广泛适配的核心框架,功能丰富、场景广泛的产业级模型库,越来越多的行业开发者,正在其生态中发挥新的生产力。
截至今年 5 月,飞桨已经吸引了 477 万开发者,在产业应用上服务 18 万企业,有超过 56 万个 AI 模型在平台中得到了应用。
正如百度 CTO 王海峰所说的:「基于飞桨平台,人人都可以成为 AI 应用的开发者。」
而随着 AI 应用的不断落地,硬件算力和软件算法将进入协同创新的新阶段,飞桨的一大波合作,在「软硬协同」的道路上迈出了重要的一步。
参考内容:
https://github.com/ML-Progress/Compute-Trends
投稿或寻求报道:content@jiqizhixin.com