![]()
本文为约4049字,建议阅读8分钟
本文介绍
了“全球最强智算”——位于河北省张北县的阿里云飞天智算平台所启用的张北智算中心。
来自中国
河北省张北县的“中国选手
”
,一举击败谷歌。
而其所凭借的算力值,每秒浮点运算次数已经高达
12EFLOPS
(百亿亿次)。
相比之下,谷歌单集群算力峰值是9EFLOPS,特斯拉也仅有1.9EFLOPS。
举个例子
![]() 。
以前要训练一个自动驾驶的模型,大概需要花费的时间是7天。
而在“全球最强算力”加持之下,这个时间直接缩短到了
1小时之内
,整整提速了将近
170倍
!
智算,即为人工智能专门提供的AI算力。这个“全球最强智算”的庐山真面目,正是来自位于河北省张北县的阿里云飞天智算平台所启用的张北智算中心。
而且这个智算中心不仅是在AI算力上取得第一这么简单,据了解,这个智算中心还“解锁”了
如下能力
:
。
以前要训练一个自动驾驶的模型,大概需要花费的时间是7天。
而在“全球最强算力”加持之下,这个时间直接缩短到了
1小时之内
,整整提速了将近
170倍
!
智算,即为人工智能专门提供的AI算力。这个“全球最强智算”的庐山真面目,正是来自位于河北省张北县的阿里云飞天智算平台所启用的张北智算中心。
而且这个智算中心不仅是在AI算力上取得第一这么简单,据了解,这个智算中心还“解锁”了
如下能力
:
-
千卡并行效率达90%以上,计算资源利用率可提升3倍
-
最高可将存储IO性能提升10倍,将系统时延显著降低90%
-
-
如此智算都用在了哪里?
此前,阿里云便和小鹏汽车打造了中
国最大的自动驾驶智算中心“扶摇”
。
而这也是国内第一个投入实际运营的,专为自动驾驶服务的超大智能算力集群。
也正如其名,“扶摇”之意,是指阿里云提供的超大算力和AI研发工具链,能让小鹏汽车的自动驾驶技术的迭代效率“直上九天”。
首先就是
以超大规模GPU算力作为AI模型迭代的基础
。
这是因为自动驾驶、或者说智能汽车上的核心功能,其实都是AI,是大规模的深度学习算法。
而无论是训练,还是测试这样的模型,扮演主角的不再是传统CPU的逻辑推理能力,而是以AI加速器为主的浮点计算能力,GPU则是当前AI加速器的主流。
其次,便是
提供了针对自动驾驶应用特征的计算集群、性能加速软件和AI大数据一体式平台,使得模型训练速度、GPU资源利用率和算法研发效能都大大提升
。
据了解,目前已经建成交付的扶摇智算中心,总算力达到600PFLOPS,即每秒进行6x1017次浮点运算。
整体计算效率上,扶摇实现了
算力的线性扩展
。存储吞吐比业界20GB/s的普遍水准提升了40倍,数据传输能力相当于从送快递的微型面包车,换成了20多米长的40吨集装箱重卡。
这也就是自动驾驶核心模型训练时间,能够由7天缩短至1小时内的主要原因。
阿里云的智能算力,可以将靶向药研究数据集计算效率提升了
100倍
。
此前算法依赖的是单机式算力,受限于软硬件的限制,往往系统整体性能偏低,无法满足快速增长的算力需求。
而通过集群进行并行计算,能让算力规模不再成为掣肘。
不过有一说一,算力这个东西,其实通过自行购买GPU搭建集群的方式便可以获取,而且此前行业内普遍的做法也是如此。
那么为什么诸多领域现在都开始时兴采用智算中心了呢?
这是因为近年来,不论是自动驾驶、元宇宙,亦或是生命科学天文学,各类科研和产业应用的发展,都越发具备数智驱动的趋势,这种情况下算的更快往往就是核心优势,算力成为了绝对的生产力。
基于如此现状,
智能计算可以提供更加多元化的算力服务
,逐渐成为了主流选择。
但智能计算不同于通用型计算,需要海量数据对AI模型进行训练,算力往往在模型参数更新、数据迁移等环节被消耗,千卡以上规模仅有40%的有效算力输出,甚至出现计算卡越多,总体性能越差的情况。
这便导致了规模化的算力的获取困难,不仅硬件成本昂贵,而且还需要专业的技术从系统架构、软件等方面进行深度重构和优化,自建智算中心,成本和时间便成为了最大的敌人。
以自动驾驶为例,复杂路况下的复杂决策能力,包括识别红绿灯、路口、行车车辆等等,其实已经进入L3-L4级范围。
按照如此迭代速度,未来3-5年,自动驾驶研发很快会进入较为成熟的L4级甚至是L5级,迭代所需算力规模也会快速上升到只有“智算中心”才能满足。
算力需求的指数级膨胀,造成目前自动驾驶玩家的“算力”焦虑越来越严重。
因此,当下自动驾驶对于智算中心的需求,其实是
为保持持续的技术领先优势做储备
。
而飞天智算中心便在拿下全球第一速度之外,还规避了诸多传统高性能计算固有的疑难杂症。
“全球最强”背后的一套功法
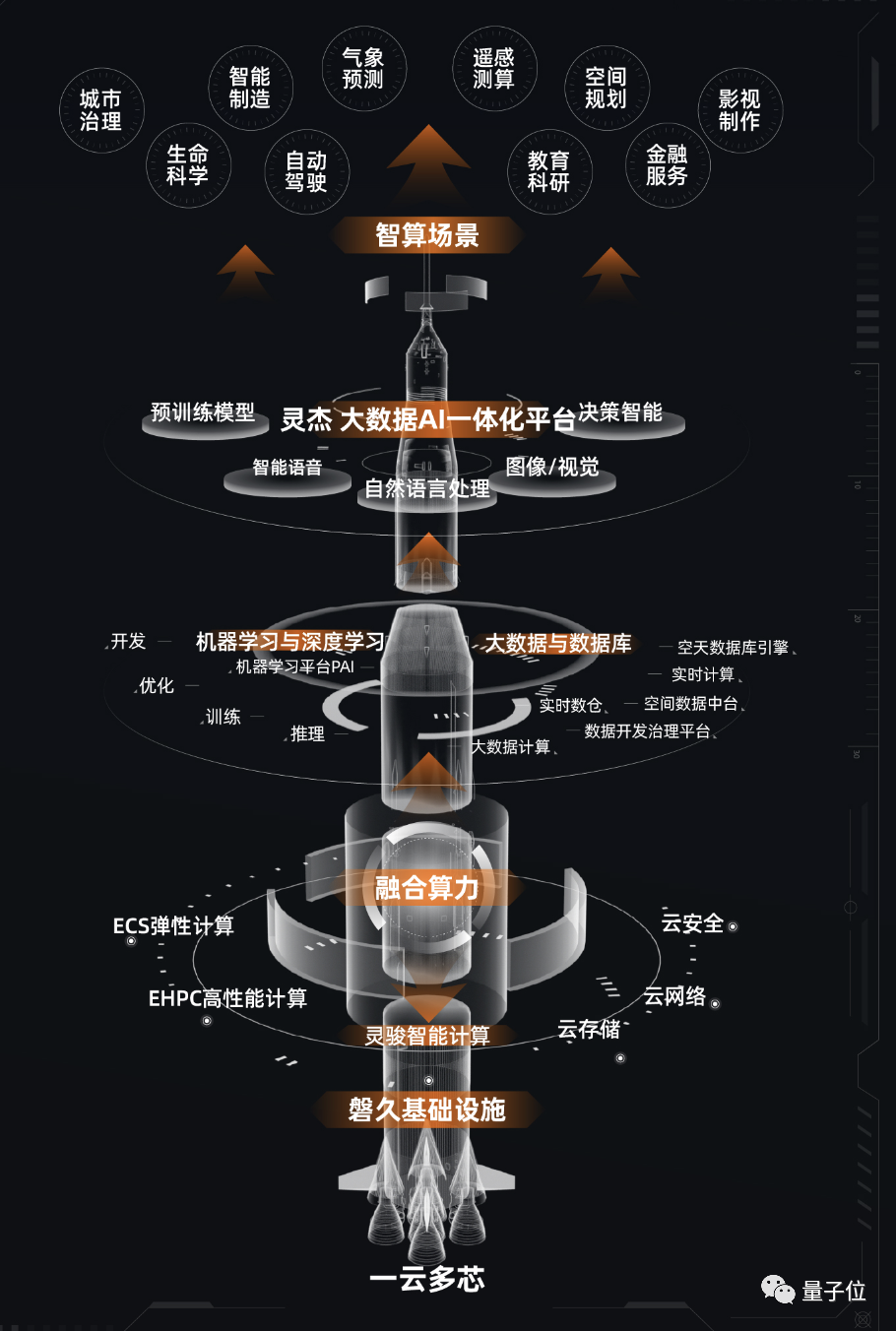
换句话说,做智算中心不能仅考虑基础设施和硬件,也要考虑其上运行的软件平台、算法和服务。
这其中最重要的是做到软硬一体,通过“打磨”让软件和硬件在一个平台中真正相互融合。
首先,要做到单集群12EFLOPS的算力峰值,仅靠单块芯片无法完成,就需要考虑并行效率的问题。
如果在一台普通电脑里装两张相同的游戏显卡,大概只能获得75%的性能,也就是花了两份钱只享受到一份半的效果。
类似的问题在智算中心也存在,而且更严重。因为要用到上千张GPU做并行计算,算力输出最低往往仅有
40%
左右。花一千份的钱,只享受四百份的效果,亏大了。
那么在飞天智算平台,千卡并行的效率可以做到多少呢?
要做到这一点,最关键的就是减少非计算部分的开销——上图里的阿里云灵骏智能计算就是干这事的。
采用浸没式液冷的灵骏智能计算,Pue低至1.09
此外,还需要分布式并行计算框架、混合精度、数据通信的优化、I/O的优化等,都需要在业务实践中反复打磨、相互配合才能做到极致的优化。
除了GPU之外,构建如此大规模算力也少不了
异构计算
。
飞天智算平台适配多种芯片架构,支持X86、ARM、GPU、NPU等多种处理器混合部署和统一调度。
据灵骏产品研发负责人曹政透露,为了支持国产化芯片的生态发展,在云服务的领域他们甚至做到了比厂商更好的性能调优。
拿淘宝来说,商品搜索、智能客服、千人千面的个性化推荐等,平均每天需要处理10亿张图像、120万小时视频、55万小时语音和5000亿句自然语言。
每逢618、双11大促,更是要面对峰值负载的考验,多年来已沉淀出适应实际需求的技术体系和最佳工程实践。
在AI开发层,阿里云还有两个杀手锏:
PAI-EPL和PAI-Blade
。
前者能够支撑万亿级参数的大模型训练,提供了包括数据并行、模型并行、流水并行在内的丰富的分布式训练能力。
在内部测试中,PAI-EPL只用了512张 GPU就完成了M6万亿模型的训练,大幅降低了超大模型训练的成本,将训练效率提升了11倍以上。
PAI-Blade则为用户提供了一站式的通用推理优化工具,对算法模型进行量化、剪枝、稀疏化、蒸馏等操作,尽量避免用户改模型代码,可将推理效率提升
6倍
以上,极大地方便用户使用。
这些综合技术整合到一起,就成了飞天智算平台软硬一体能力的来源。
除了智算中心自身软硬件之外,其上运行的算法和智能服务也是飞天智算平台中的重要能力。
全链路AI开发工具与大数据服务,包括阿里云大数据+AI一体化产品体系,集合了机器学习平台PAI、大数据开发与治理平台DataWorks、MaxCompute、Hologres、Flink等计算引擎实现架构统一。
如此一来,可适用于多种AI场景的计算和开发需求,包括科学研究、精准医学、气象预报、数字孪生、自动驾驶等多种场景。最多可提升AI训练效率11倍,推理效率6倍。
另外说到智能算法也别忘了达摩院。据介绍,达摩院开源的M6大模型从诞生之初就与飞天智算平台一起生长,相互配合起来更能发挥出彼此的实力。
对于大型算力中心来说,衡量绿色化程度的一个重要指标是能源利用效率(PUE, Power Usage Effectiveness)。
根据《2021年中国数据中心市场报告》,2021年全国数据中心平均PUE为1.49,华北地区平均约为1.40。
这意味着IT设备每消耗1度电,就有额外的0.49或0.4度电用于散热、供配电系统本身的消耗、照明等其他用途。
而张北智算中心采用了行业独有的单相浸没式液冷解决方案,将服务器泡在特殊冷却液里,PUE最低可以达到1.09,行业领先。
图:阿里云浸没式液冷服务器
此外,
AI调温和模块化设计
等都起到了关键作用。
不仅如此,智算中心选址在张北还可以利用起当地充足的光伏和风电资源,做到
100%使用清洁能源
。
不过为了克服光伏和风力发电不稳定的问题,也需要更强大的供配电技术来保障。
如何评价全球智算王座易主?
两年前,阿里首次公开自研AI集群细节,那篇论文还被计算机体系结构顶级会议HPCA 2020收录。
不过在多年来一直参与平台建设的曹政看来,当年团队把注意力单纯的集中在了技术上。
如今升级扩展到智算平台,除了规模扩大,技术进化以外,还更看重产品、服务,看重智算平台能否真正顺滑的与生产流程相结合。
建设大规模智能算力有几类玩家,云计算公司、AI算法公司、硬件公司。
阿里在其中是一种比较特别的存在,既有自研云计算技术体系,又有内部AI业务的大量实践,最近又开始涉足自研芯片。
如此打造出来的智算平台高度自主可控,既能以此为蓝本不断复制出新的智算中心,又能在服务不同行业时低成本迁移。
如专为小鹏汽车定制打造的乌兰察布智算中心便是很好的例证。
如果把目光拉远,更大的图景在于
数字化升级、智能化转型
。
这些年来,智算中心的服务对象从大型技术公司、AI算法初创公司,逐渐扩展到自动驾驶、AI for Science等交叉行业。
随着智能化转型逐渐深入,不久的将来还要服务于农业、制造业、能源、物流这些离IT技术更远的行业,而越是这样的行业就越是需要端到端的解决方案。
从这一点来看,强调“
打磨
”、“顺滑”的飞天智算平台,再一次“幸运地”引领了时代趋势。



 。
。