当初人们应用AI技术的困难模式,百度让你不用再来一次。
今天,人工智能技术落地的速度有多快?五分钟。
这是上周日 WAVE SUMMIT+ 2021 峰会上,百度飞桨向我们展示的结果。
在一番现场实操之后,手势识别的模型让机器狗学会了看人指挥:只要有人向机器狗摆出手势,它就能听话地向左、向右挪步,或者趴下:
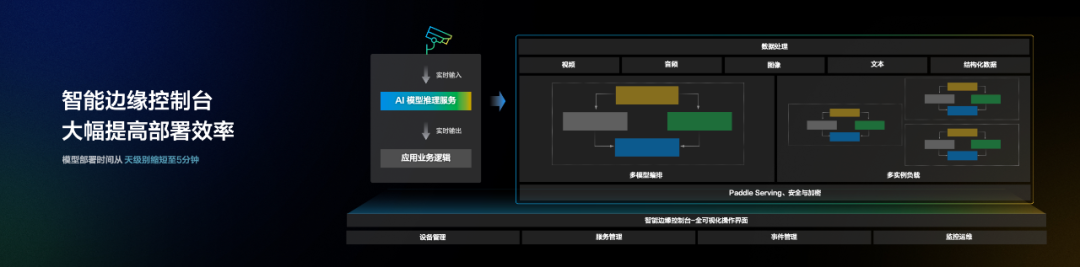
原来需要在实验室中做大量工作才能实现的事,现在变得如此简单。百度展示的工具名叫「智能边缘控制台」,它提供了全可视化操作界面,能让 AI 模型部署的时间从天级别缩短至 5 分钟,在这之后还能持续对服务运行监控运维。
![]()
这只是本次飞桨框架升级的一个功能。现在 AI 技术的发展有哪些趋势?看完飞桨的这次最新升级就知道了。
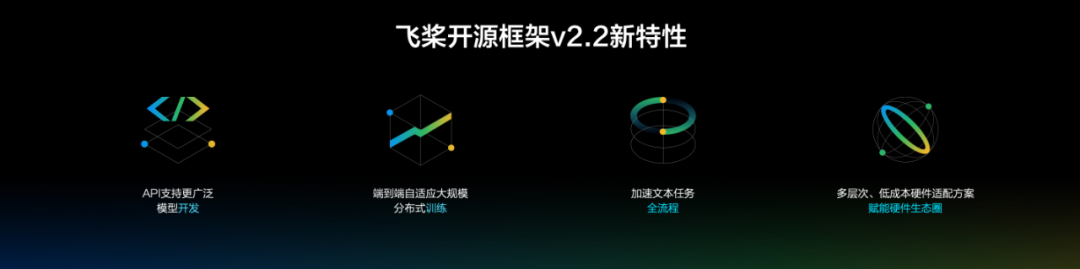
12 月 12 日,WAVE SUMMIT+ 2021 深度学习开发者峰会在上海举办。百度重磅发布了飞桨开源框架 v2.2,带来了四大新特性,涵盖开发、训练、文本任务全流程和硬件适配方案。
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰在峰会上表示,「目前,人工智能发展正呈现融合创新和降低门槛的特点:一方面,AI 技术及产业的融合创新越来越多;另一方面,虽然 AI 技术越来越复杂,但 AI 开发与应用的门槛却越来越低。」
![]()
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰
面向技术和产业发展需求,飞桨突破核心框架,实现 AI 模型的便捷开发、高效训练和多端多平台部署,另一方面又坚持开源开放,不断培养生态,实现了技术、产业、人才和生态的互相促进。
百度集团副总裁、深度学习技术及应用国家工程实验室副主任吴甜更是明确提出建设飞桨的三个关键点,「技术持续创新、功能体验以开发者的需求为首位,以及广泛地与生态共享、共创。」基于此,吴甜在峰会上率先发布了飞桨新版全景图—产业级模型库新增文心大模型、业界首个产业实践范例库和飞桨 “大航海”2.0 共创计划。
除了飞桨开源框架 v2.2 之外,百度还升级了飞桨产业级开源模型库,发布并开源了 13 个结合场景应用深度优化过的 PP 系列模型,并对飞桨企业版模型部署能力进行了升级。
可以看出,「持续突破创新核心框架」正是飞桨框架升级到 2.2 版本的理念根源。
基于长久以来对 AI 技术和应用发展的观察和思考以及飞桨开源平台推出以来的种种实践,王海峰博士认为当前人工智能呈现两大特点,即「融合创新」和「降低门槛」。前者为后者的铺垫和根基,通过知识与深度学习融合、软硬一体融合以及技术与场景等多方面融合,逐步降低 AI 开发与应用的门槛。
此次,飞桨开源框架 2.2 版本的发布恰恰诠释和体现了这两大特点。依托深度学习开发与训练、文本任务极致优化、硬件高效适配以及低门槛推理部署等多方面的创新性技术,飞桨进一步赋能开发者,让开发更容易、训练更高效、硬件适配成本更低。在峰会上,百度深度学习技术平台部高级总监马艳军对飞桨开源框架 2.2 版本的四大新特性进行了详细解读。
![]()
升级后的飞桨框架新增了 100 多个 API,尤其是科学计算 API,支持了量子计算、生命科学、计算流体力学、分子动力学等应用。飞桨 API 种类丰富的同时,性能一并增强,进一步支持了高阶自动微分功能以及计算流体力学、分子动力学等场景。飞桨 API 还保持了对历史版本的兼容,一切都是为了让开发者更容易上手。
飞桨框架 2.2 版本在文本任务处理速度上也取得了新的技术进展。通过端到端文本处理、预训练任务加速和生成任务解码加速,框架最终针对预训练模型形成训推一体全流程开发体验,大幅节省文本处理代码,还能显著提升推理速度。「从实际的产业部署代码示例中,可以看到,文本处理算子化的训推一体开发体验可以让部署代码节省 94%。」马艳军给出了这样的实现效果。
不过,这次飞桨框架 2.2 版本的核心技术突破远不止此,接下来要讲的
端到端自适应大规模分布式训练技术和硬件适配统一方案是本次飞桨框架升级的重点
。
还记得前几天刚刚发布的全球首个知识增强千亿大模型鹏城 - 百度 · 文心吗?正是基于这种端到端自适应大规模分布式训练技术。
今年以来,百度在预训练方面一直有新技术产出。年初推出的 4D 混合并行策略可以训练超大语言模型,飞桨框架 v2.0 更是 创新性地推出了业界首个通用异构参数服务器,让开发者使用 CPU 和 AI 专用芯片等不同硬件进行混合异构训练,实现对不同算力的芯片高效利用。
此次,飞桨框架 2.2 版本又再进一步,全新发布了端到端自适应大规模分布式训练技术。
![]()
当前,社区普遍使用分布式训练方法来训练具有海量数据的神经网络,但这种方法在面对不同神经网络模型、不同计算资源以及训练中出现的动态变化,往往表现得力不从心。飞桨创新性地以系统性端到端方式设计分布式训练框架,这样做提升了针对不同场景的内在自适应能力,进而既能满足多样性应用和差异化计算资源下的各种需求,性能表现与其他方法相比也颇具竞争力。
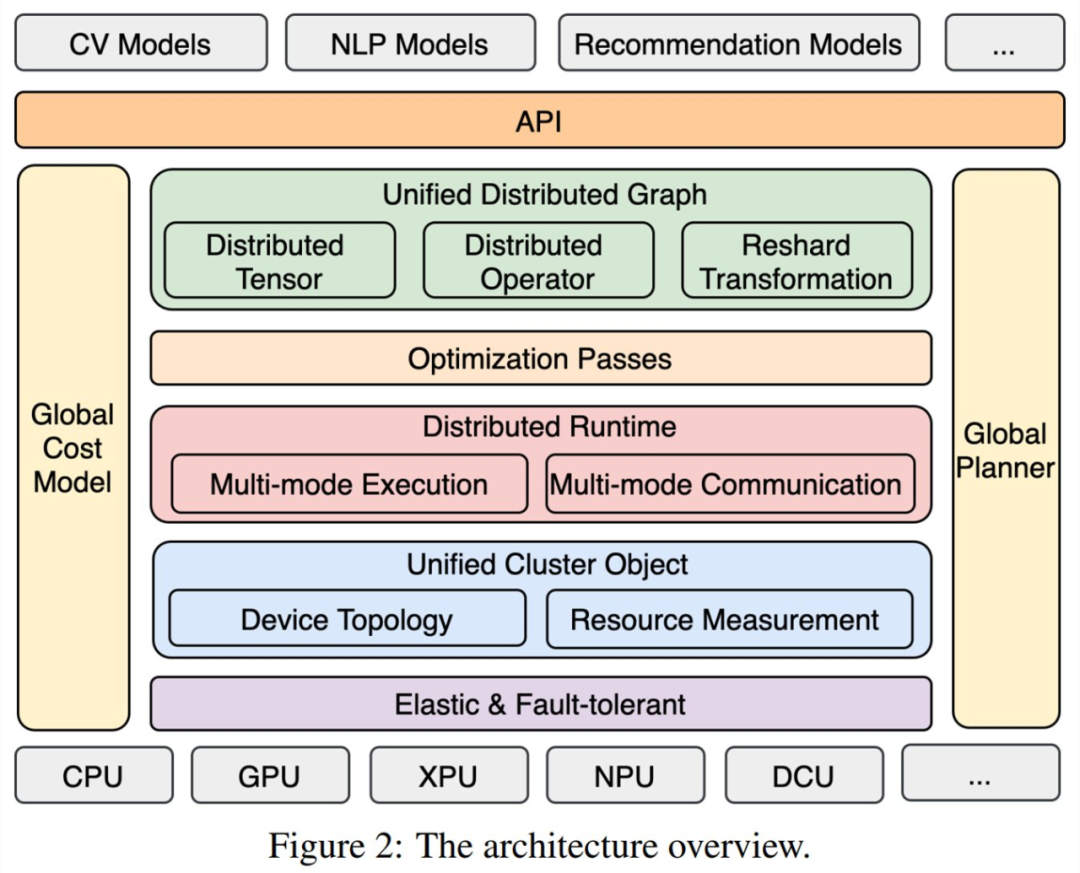
在 12 月 6 日百度提交的 arXiv 论文《End-to-end Adaptive Distributed Training on PaddlePaddle》中,我们可以更清楚地洞悉该技术的结构示意图。
![]()
论文地址:https://arxiv.org/abs/2112.02752
马艳军在会上介绍了这种端到端自适应大规模分布式训练的设计思路:
首先,针对不同的模型和硬件,抽象成统一的分布式计算视图和异构资源视图,并通过硬件感知切分和映射功能及端到端的代价模型,搜索出最优的模型切分和硬件放置组合策略,将模型参数、梯度和优化器状态按照最优策略分配到不同计算卡上,达到节省显存、负载均衡和提升训练性能的目的;
接着,采用异步流水运行机制,以高通信和高并发的方式高效训练;
最后,为了进一步提高训练的稳定性和资源利用率,飞桨提供弹性调度模块,感知硬件资源变化,自动重构资源视图,触发各个模块自动的发生变化,如重新构建资源视图、切分、硬件分配、流水运行。在不中断训练情况下,弹性调度集群可用机器来进一步提升训练的性能。
这一端到端自适应大规模分布式训练架构的效果如何呢?从飞桨已经做的几组实验结果来看,效果很不错。比如,在 512 卡 GPU 集群训练 GPT 模型,训练速度有显著优势;在鹏城云脑 II 集群上采用自适应优化,训练速度更是能够达到优化前的 2.1 倍。
硬件适配是开发者使用深度学习框架开发应用时可能会遇到的头疼问题之一。随着智能芯片种类的日益复杂,适配成本显然已经成为一个重大问题。
为了开发者适配硬件时有更多选择,飞桨一直在努力。在 WAVE SUMMIT 2020 峰会上公布了飞桨硬件生态伙伴圈,通过与全球芯片、整机等相关硬件领导厂商的密切合作,积极适配芯片或 IP。但应看到,基于技术创新降低已有硬件的接入成本同样重要。
因此,百度在峰会上正式推出了硬件适配统一方案,这是一种多层次、低成本的硬件适配方案,包括
飞桨三大自研优化方案:Kernel Primitive API、NNAdapter 和神经网络编译器 CINN(预发布版本)
,分别提供了算子开发与映射、子图与整图接入以及编译器后端接入三类互相关联的方案,灵活性十足。
![]()
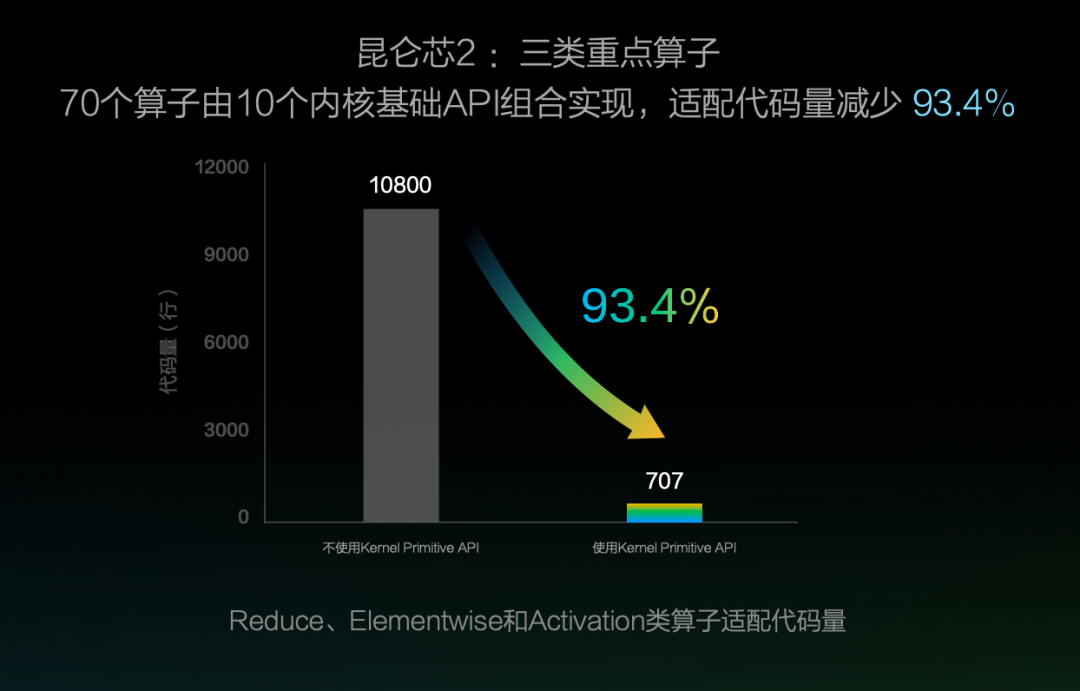
首先看 Kernel Primitive API。通过对算子 Kernel 实现中的底层代码进行抽象与封装,提供高性能的 Block 级 IO 和 Compute 运算,实现了算子计算与硬件解耦。这样一来,Kernel 开发可以更加专注计算逻辑的实现,在保证性能的同时大幅减少代码量,如 softmax 算子实现由 155 行减少为 30 行,逻辑更加清晰,可维护性更高。
该方案还能够大幅减少硬件适配时的算子开发成本,以昆仑芯 2 接入为例,通过 Kernel Primitive API 组合实现 Reduce、Elementwise 和 Activation 这三类算子,适配代码量减少 93.4%。使用 Kernel Primitive API 还实现了一处优化、多处收益的效果,仅对 IO 运算进行向量化访存优化,飞桨的 70 个算子性能就可以平均提升 12.8%。
![]()
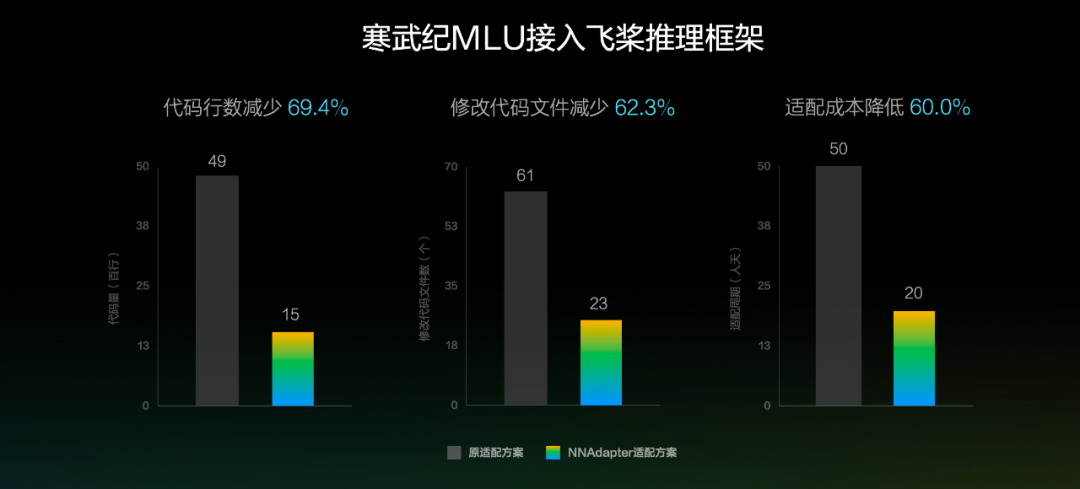
其次是 NNAdapter。我们知道,硬件厂商通过直接子图 / 整图接入时,需要理解框架的内部实现机制,门槛高且沟通成本大。飞桨在框架和硬件之间建立了 NNAdapter 统一适配层,向上通过 NNAdapter API 完成框架适配层的统一接口,向下通过 NNAdapter HAL 完成硬件抽象层 (HAL)的统一接口,实现了对硬件设备的抽象和封装,为 NNAdapter 在不同硬件设备提供统一的访问接口。
这一方案实现了算子定义及框架调度执行与硬件的解耦,降低了门槛,减少了成本。以寒武纪 MLU 适配为例,NNAdapter 方案相比原直接子图接入方案,代码行数减少 69.4%,修改的代码文件减少 62.3%,人力投入成本降低 60%。
![]()
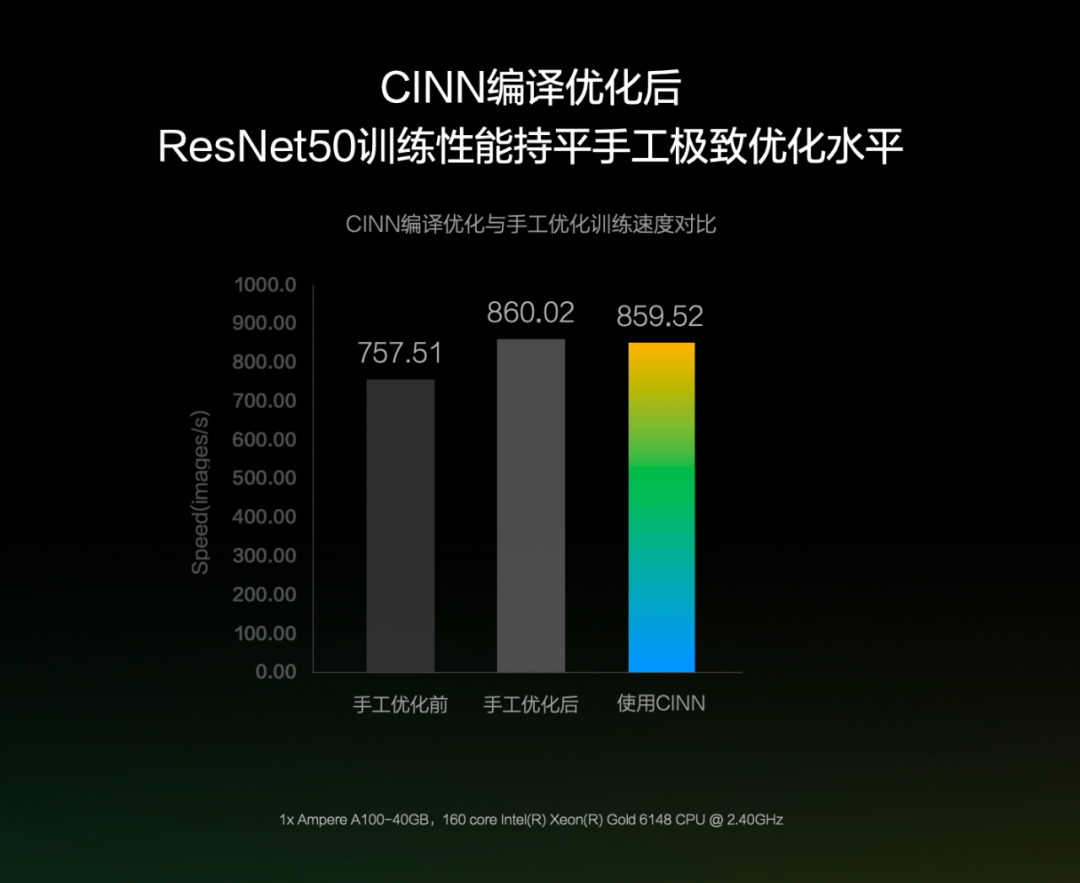
最后是预发布版本的神经网络编译器 CINN。CINN 全称为 Compiler Infrastructure for Neural Networks,面向飞桨框架深度优化,同时支持训练和推理。
![]()
在硬件适配时,大量复杂算子需要利用硬件提供的特定基础计算库实现,这些复杂算子与硬件的基础计算库差别较大,导致了适配成本很高。
CINN 将复杂算子拆分成基础算子组合实现,使得适配时只需实现少量基础算子即可完成对各种复杂算子的支持,并且这些基础算子与硬件计算库更接近,因此实现成本更低。然后,再通过自动融合及自动代码生成技术,解决 kernel 增多带来的调度和访存开销,提升性能。
CINN 编译器方案能带来多大的提升呢?马艳军举例表示,「在这次预发布的 CINN 版本中,ResNet50 模型的训练性能已持平手工极致优化水平。」
![]()
产业级开源模型库的「全与专」,真正满足业务场景需求
开发模型的能力继续增强,对于工业领域内数量更多的非 AI 专业人士来说,这个门槛还能再降低。
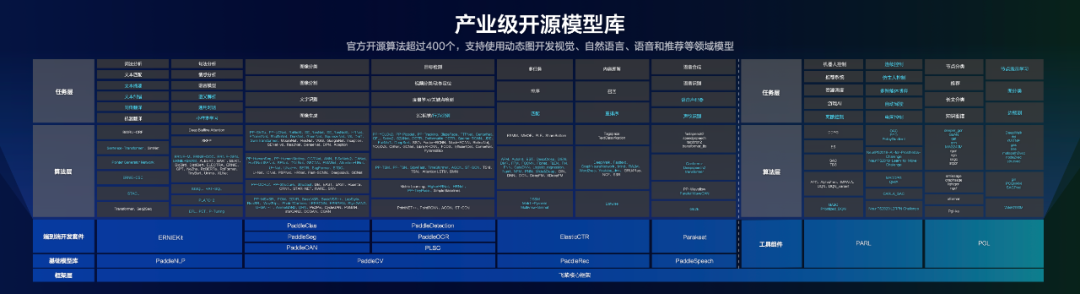
产业级开源模型库是飞桨四大领先技术优势之一,包含大量经过产业实践长期验证的主流模型,并提供面向语义理解、图像分类、目标检测等不同场景的端到端开发套件,满足了企业用户低成本开发和快速集成的需求。目前,飞桨官方支持的产业级开源算法超过 400 个,支持使用动态图开发视觉、自然语言、语音和推荐等领域的众多模型。
会上,马艳军表示,针对产业实践中的更多真实需求,飞桨产业级开源模型库又新增了一些深受企业开发者喜爱的前沿算法。
![]()
针对企业用户最高频使用的一部分模型,百度在结合产业实践中痛点问题的基础上进行了从框架到模型的全栈优化,发布并开源了 13 个产业级 PP 系列特色模型。至此,
飞桨产业级模型库不仅做到了覆盖面全,还要有的放矢,解决企业用户最迫切的业务场景需求
。
![]()
马艳军指出,「PP 系列模型能够很好地实现精度和性能的平衡。」比如 PP-YOLOv2,在数据增强、骨干网络、损失函数等方面提出了 13 项优化策略,非常好地满足了企业开发者实际业务场景的需求,有效帮助开发者加速业务落地。
模型部署是 AI 产业实践中的难题,推理部署工具链条是否通畅,一定程度上决定 AI 应用最后一公里路走得好不好。飞桨企业版一直致力于让模型快速高效地部署到多样化的软硬件环境,实现最优推理效果。
此前进行「一核两翼」AI 开发双平台全新升级,一核指的是一个专为 AI 平台开发者打造的、易被集成的云原生机器学习核心系统 PaddleFlow。两翼分别指的是面向 AI 应用开发者的零门槛 AI 开发平台 EasyDL 和面向 AI 算法开发者的全功能 AI 开发平台 BML。两个平台共享了一些核心的功能和模块,包括资源管理、数据管理、模型训练等。
「过去几年,EasyDL 和 BML 两个平台上的模型训练任务量在加速增长,行业分布也非常广,包括互联网、工业、零售等 20 个行业。EasyDL 和 BML 已成为应用和落地最广泛的 AI 开发平台。」百度 AI 产品研发部总监忻舟在会上介绍道。
虽然应用和落地已经很广泛,但飞桨企业版在模型部署中依然面临一些技术难题,比如推理硬件适配繁琐、模型压缩优化难以及部署集成周期长等。
为了进一步降低企业开发者的应用门槛,飞桨企业版在模型部署方面也迎来了全新升级,让 AI 应用的最后一公里高效便捷。据忻舟介绍,此次飞桨企业版模型部署的全新升级基于飞桨推理部署工具链,与平台深度融合,打造自动高效的企业级部署功能。
![]()
飞桨企业版模型部署升级显著提升了推理性能,还能广泛适配推理芯片,大幅提高部署效率。如何做到的呢?要从以下三个方面说起。
模型压缩上,基于 PaddleSlim 工具,结合一些前沿的压缩算法,根据不同模型和硬件的特点和压缩级别的要求,设计了多条全自动组合压缩流水线,自动选择最佳压缩路径。对常见的模型,平均精度损失控制在 1% 内,加速比能达到 3-5 倍。
推理和硬件适配上,采用飞桨推理部署工具链中的飞桨推理引擎,如 Paddle Inference、Paddle Lite 和 Paddle.js,适配了超过 30 多款芯片。推理性能也十分出色,在端和边缘设备的 Arm 芯片上尤为突出。此平台更是为开发者测试并验证了 9345 种模型芯片的组合,覆盖 95% 的适配需求。通过平台提供的推理能力,开发者能够节省 97% 的自行适配开发时间;
最后是文章开头百度展示的模型服务化与智能边缘控制台,能够大幅提高部署效率。
对了,还有最后的彩蛋,那就是全新发布的飞桨 EasyDL 桌面版。
![]()
有了它,开发者不必繁琐地配置各种套件,在桌面一键极速安装即可实现本地高效建模,1 分钟安装完成,15 分钟即可完成模型开发。本地实现数据管理、算力调度、网络应用,让 AI「触手可得」。
WAVE SUMMIT+ 2021 上飞桨发布的新技术,无不紧跟当前 AI 研究前沿,提升 AI 模型开发、训练与部署的整合的速度,降低了应用门槛。飞桨这些年,沿着这条道路越走越宽,开发者已经达到了 406 万,人们在飞桨平台中构建了 47.6 万个模型,飞桨提供的服务也已覆盖了 15.7 万家企事业单位。
这样的成绩,让百度飞桨在中国深度学习平台综合市场份额排名第一。
![]()
深度学习框架下接芯片,上承各种应用,堪称「智能时代的操作系统」,作为国内首个自主研发、开源开放的产业级深度学习平台,飞桨是越来越多 AI 开发者的首选,承载了无数工业级应用。
正如王海峰博士所言,「飞桨一直秉承技术创新、开源开放的初心,敏锐判断技术和产业发展趋势,在核心技术的积累和突破上下功夫。」未来,飞桨的升级换代也不会止步。
https://juejin.cn/post/7013383351864131615
https://www.jiqizhixin.com/articles/2021-01-21-13
https://posts.careerengine.us/p/604ee74989e258381f45ed06
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com