百度开源深度学习平台飞桨的核心技术及应用

分享嘉宾:蓝翔 百度 资深研发工程师
编辑整理:张兰兰 人民银行
出品平台:DataFunTalk
导读:近期,DataFunSummit AI基础软件架构峰会以线上形式成功召开,其中深度学习框架论坛更是云集了各大著名科技企业的顶级专家。来自百度飞桨的资深研发工程师蓝翔老师在大会上为大家系统地介绍了源于产业实践的开源深度学习平台——飞桨,包括飞桨的核心技术,在各行各业中的广泛应用,以及飞桨在生态建设上的突出成绩。下面就为您带来此次演讲的实录。
从2010年开始,百度开始全面布局人工智能技术。2016年,百度正式将飞桨开源,把人工智能技术分享给了广大开发者。历经5年,飞桨已经发展成完整的全景图,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。
1. 飞桨全景图
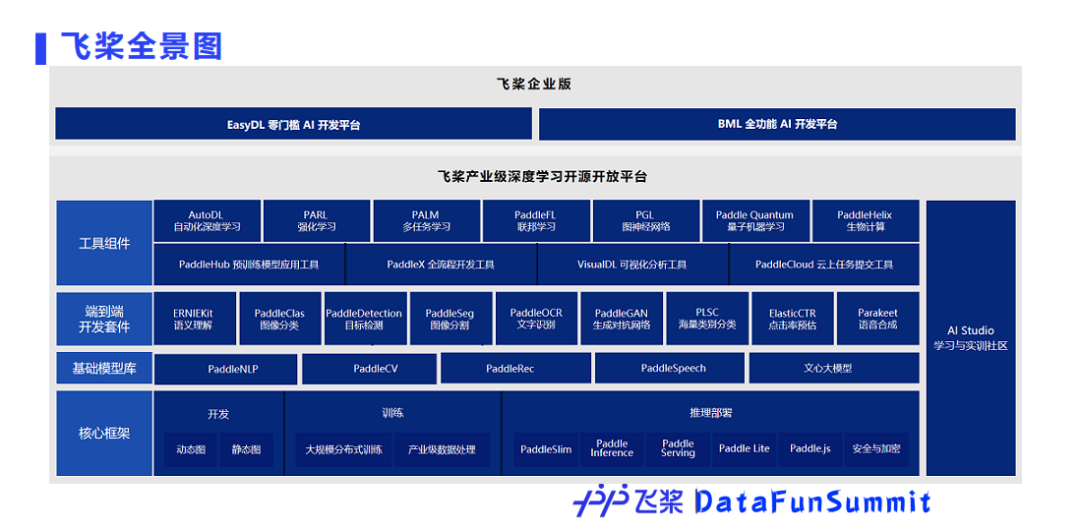
核心框架
在飞桨全景图中,最底部为飞桨核心框架,为开发者提供了动态图和静态图两种编程范式,训练方面包含了大规模的分布式训练和产业数据的处理能力,推理部署能力包括服务器端、移动端、网页前端等,同时通过模型压缩工具,可以帮助开发者获得更小体积的模型和更高的性能。
基础模型库
基础模型库目前覆盖了主流的深度学习研究领域,如自然语言处理、计算机视觉、推荐、语音等,包含多类任务的SOTA模型。开发者可以直接使用,也可以做二次研发,从而满足用户不同需求。
端到端开发套件
在基础模型库的基础上,飞桨还封装了端到端的开发套件,以满足用户更高级的需求,通过开发套件,用户可以像搭积木一样更快更好地开发、训练和部署模型。
工具组件
为了进一步提升开发效率,针对企业的需求,如强化学习、联邦学习以及前沿技术,如量子机器学习、生物计算等领域的需求,飞桨团队还开发了相应的工具组件,以帮助开发者和企业快速落地AI应用。
飞桨企业版
针对企业实际应用需求,飞桨企业版以飞桨深度学习开源平台为基础,提供了EasyDL零门槛AI开发平台和BML全功能AI开发平台两个平台,旨在为企业提供更好的开发坏境,让企业更加聚焦于业务与创新。
2. 飞桨核心技术
下面我们来详细介绍下飞桨框架的核心技术。当前深度学习在大规模产业化方面面临诸多挑战。
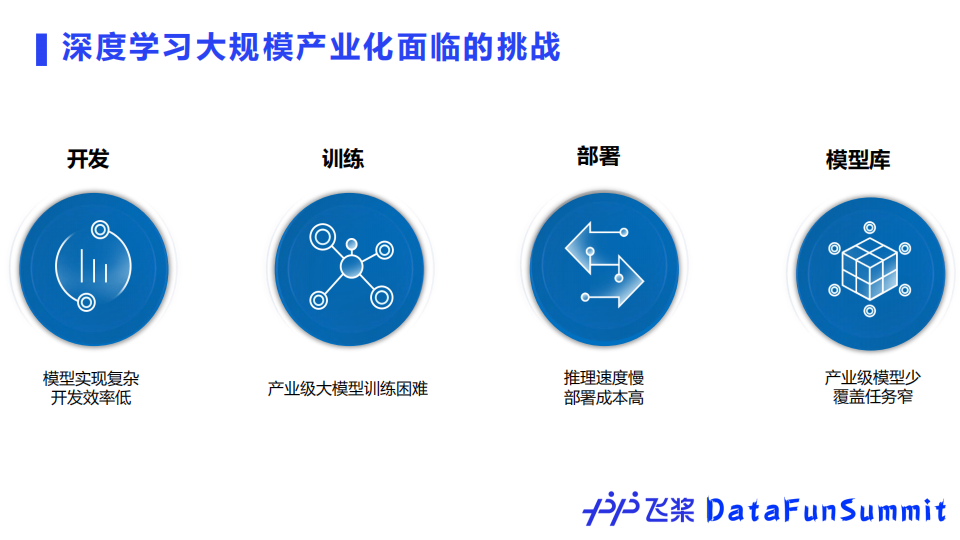
首先在开发阶段,模型实现复杂,开发效率较低;
在训练阶段,产业界的数据量大,训练时间长,反复训练困难;
在部署阶段,实际产业落地的要求很高,同时多硬件还会带来了很大的部署成本;
产业模型库包含的模型较少,无法满足开发者的应用诉求。
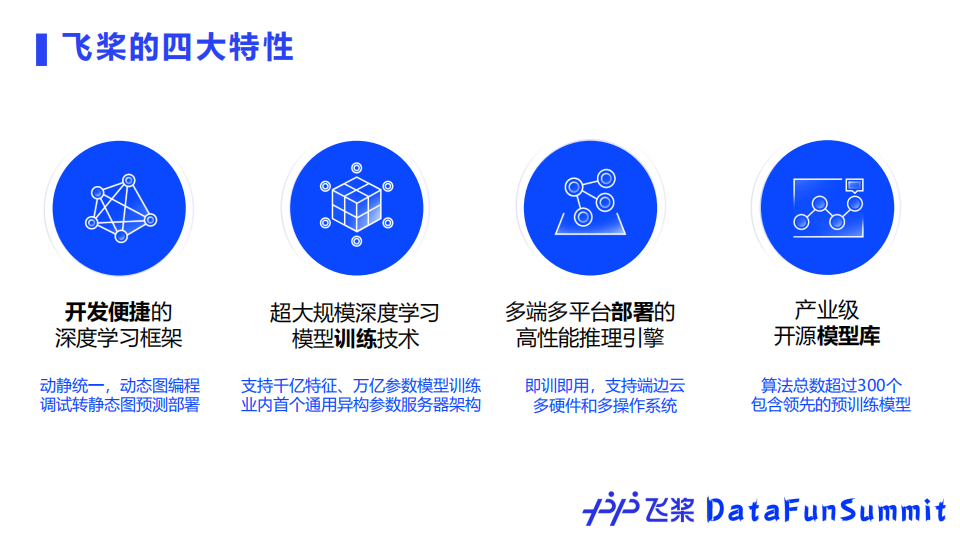
面对这些挑战,飞桨实现了四大特性,下面将分别详细介绍。
① 开发便捷的深度学习框架
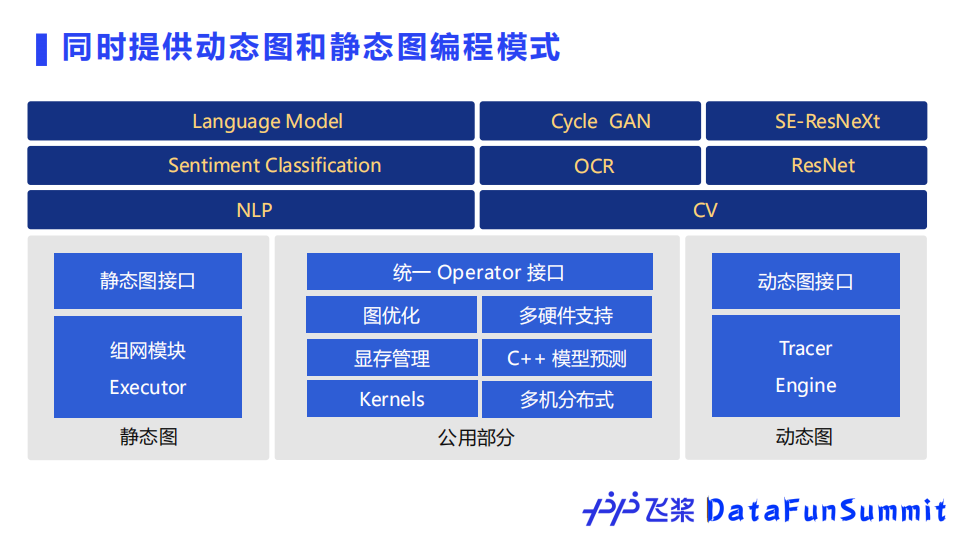
飞桨自然完备地兼容支持便于性能优化的静态图和易于调试的动态图两种编程范式,默认编程范式采用动态图,并完美地实现了动静统一。开发者使用飞桨可以便捷地获得动态图编程调试,一行代码转静态图训练部署的良好开发体验。
此外,飞桨还设计了具有独创性的中间表示——ProgramDesc,它区别于常用的图表达方式,使得表达简洁,更好承接上一层编程范式,以及兼顾性能。ProgramDesc还可以更加方便地无缝衔接分布式训练和推理。此外,在编译优化方面,ProgramDesc层之外还有图的表达方式,形成双层中间表示的结构。
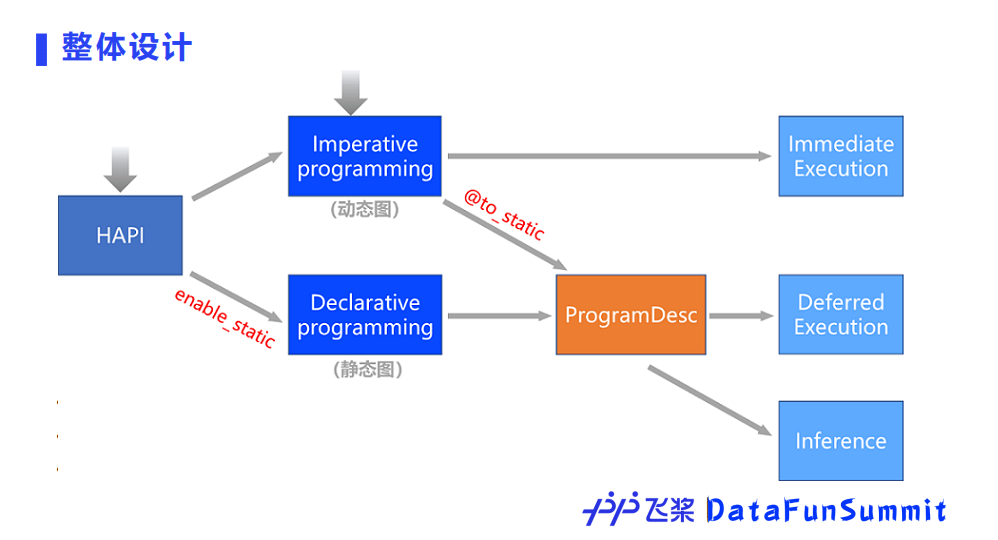
为了更高效地提供动态图和静态图两种编程范式,飞桨的底层设计把可以复用的模块形成公用部分,仅从接口和执行逻辑上来区分两种编程模式,这样设计可以实现两种范式的灵活转换。飞桨提供了全面完备的动转静支持,在Python语法支持覆盖度上达到领先水平。开发者在动态图编程调试的过程中,只需在动态图上添加一个装饰器,就可以无缝平滑地自动转化成静态图,代码改动量最小。
此外,飞桨还做到了模型存储和加载的接口统一,保证动转静之后保存的模型文件能够被纯动态图加载和使用。
飞桨为了简化用户的开发成本,还设计了高层API。高层API同时支持动态图和静态图,所以使用高层API时不用考虑所使用的编程范式。高层API对数据预处理、数据加载、模型组网、模型训练、模型评估、模型保存等都进行了封装,每个步骤仅使用几行代码即可实现。同时高层API对计算机视觉、自然语言处理等领域API也做了封装,例如transformer中的encoder结构,这样的设计不仅简化了代码,还保证了模型效果和高性能。
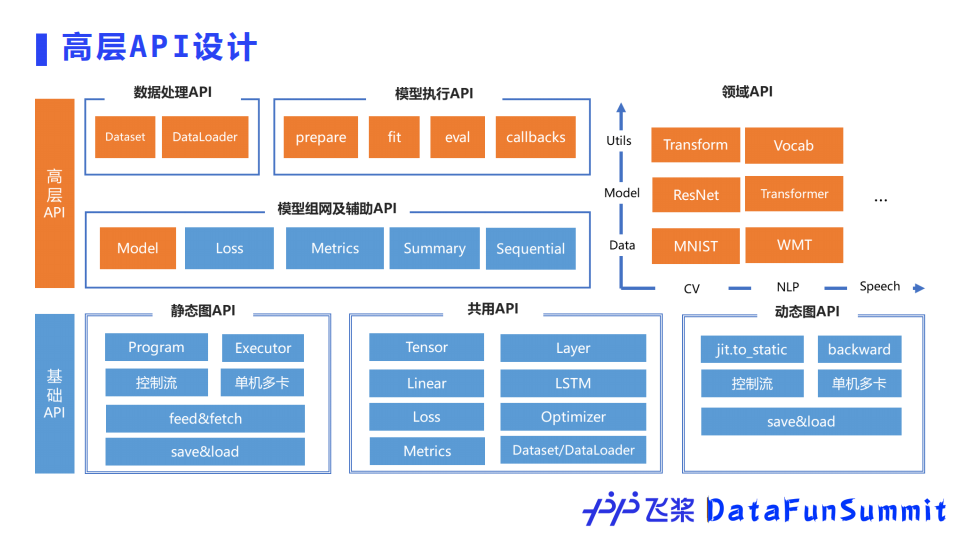
高层API的应用效果,对于新用户来说屏蔽了底层的具体细节,减少了学习成本、上手更快,代码量的减少使得开发效率可以提高50%。高层API和基础API采用一体化设计,两者可以互相配合使用,兼顾开发的便捷性和灵活性。
② 超大规模深度学习模型训练技术
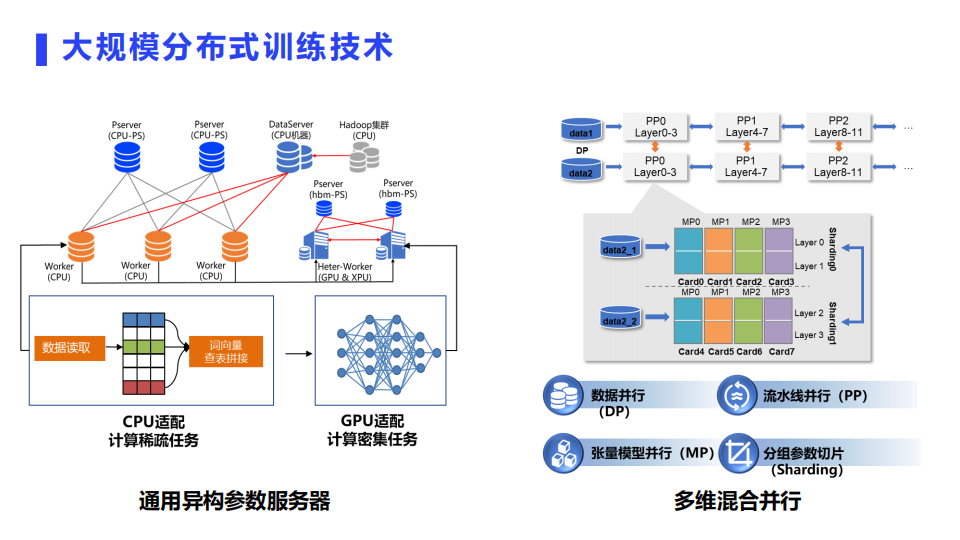
大规模分布式训练历来是飞桨非常有特色的一个功能,领先其它框架实现了千亿稀疏特征、万亿参数、数百节点并行训练技术。
此外,飞桨还覆盖支持包括模型并行、流水线并行在内的广泛并行模式和加速策略,率先推出业内首个通用异构参数服务器模式和4D混合并行策略,引领大规模分布式训练技术的发展趋势。
③ 多端多平台推理部署引擎
对于推理架构方面,飞桨设计了端边云全面支持的推理引擎架构,由于采用了和训练框架一体的内部表达和算子库,可以完美地实现即训即用,以及最全面的模型支持。除了最广泛的硬件和操作系统平台支持之外,我们也设计并开发了可灵活插拔的加速库,以契合不同场景下部署任务的特点。
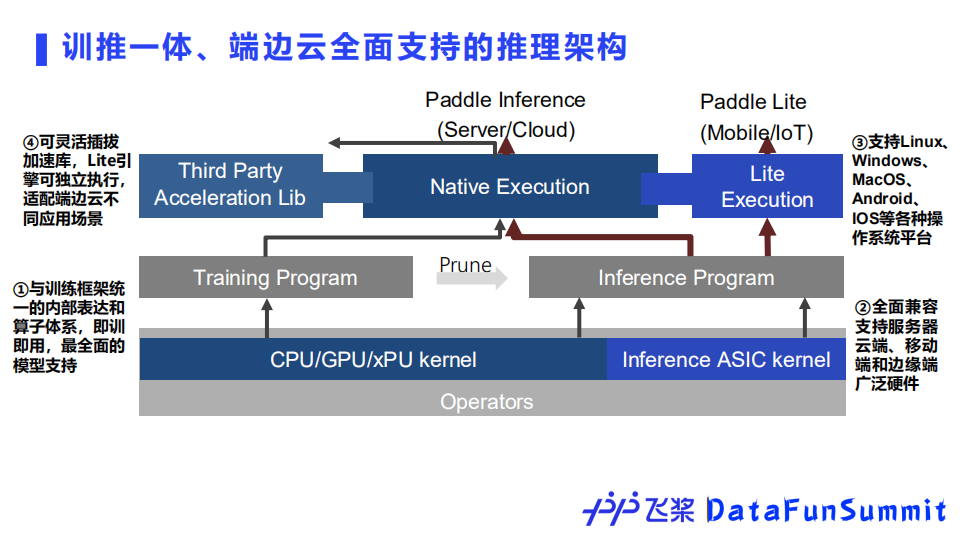
部署方面,飞桨还拥有全流程、全场景推理部署工具链。开发训练得到的模型可以通过飞桨模型压缩工具PaddleSlim的剪枝、量化或蒸馏技术来进一步优化,然后可以使用服务器、移动端/边缘端、网页端等不同硬件场景的推理引擎进行部署。从生态来看,飞桨还支持其它框架模型在飞桨平台部署,也支持将飞桨模型转换为ONNX格式部署。
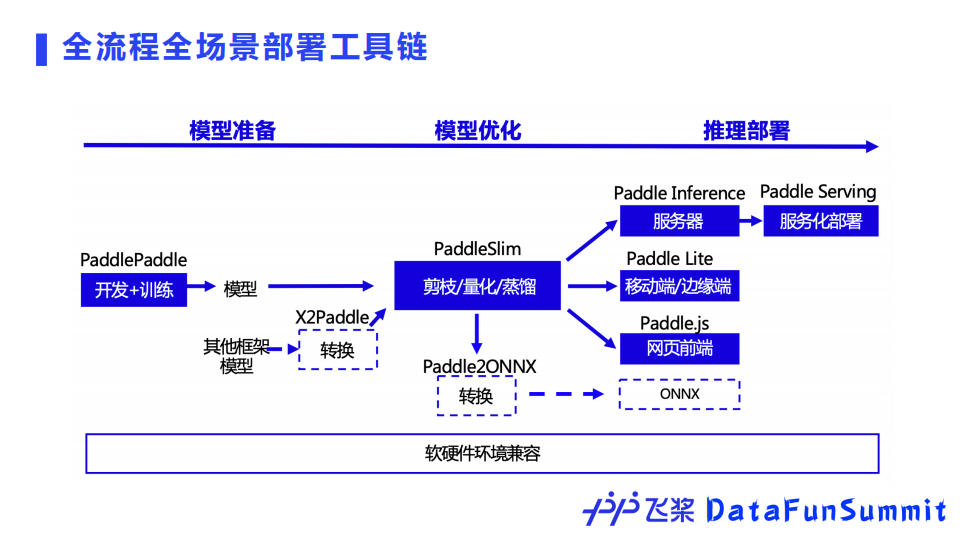
④ 产业级的开源模型库
当前官方模型库支持的算法数量超过400个,覆盖计算机视觉、自然语言处理、推荐、语音等多个领域,并包含经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型,助力快速产业应用。
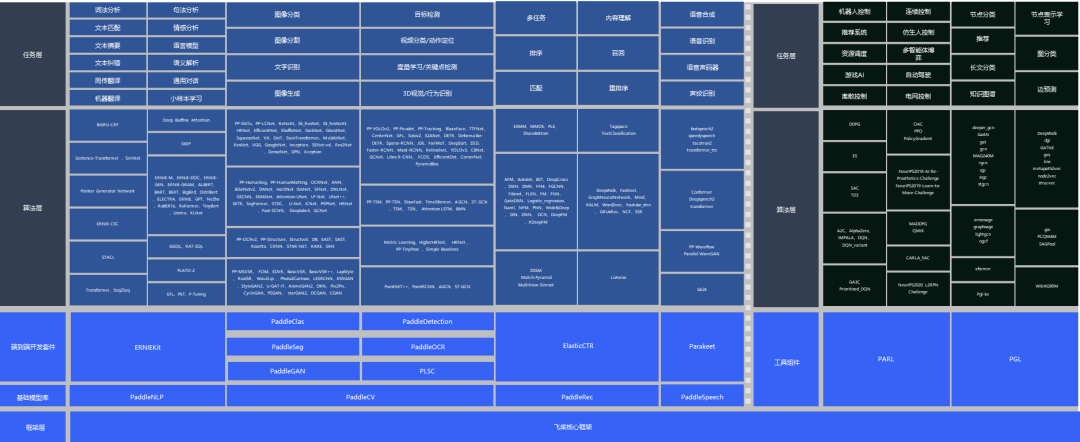
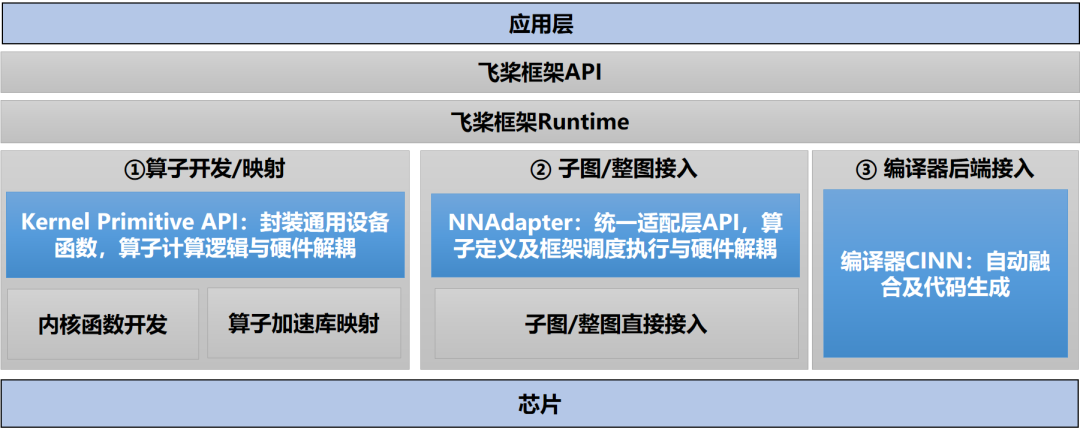
随着国产硬件的不断发展,训练和推理端新型AI芯片的适配面临着很大挑战。
为了对接愈加丰富的各类硬件,飞桨框架设计了适配统一方案,多层次、多维度降低软硬件适配和融合优化的成本。针对不同的硬件特性,分别提供了算子开发与映射、子图与整图接入以及编译器后端接入三类不同方案供厂商根据硬件特性灵活选择。飞桨自研了三个优化方案:高性能基础算子库(Kernel Primitive API)、NNAdapter、编译器CINN,分别对AI算子库、图、编译器后端进行软硬件结合的深度融合优化。目前飞桨可以说已经是硬件接入成本最低的框架。
基于成熟完备的硬件适配统一方案,飞桨硬件生态持续繁荣,包括英特尔、英伟达、ARM等诸多芯片厂商纷纷开展对飞桨的支持,并主动在开源社区为飞桨贡献代码。飞桨还跟飞腾、海光、鲲鹏、龙芯、申威等CPU进行深入融合适配,并结合麒麟、统信、普华操作系统,以及百度昆仑、海光DCU、寒武纪、比特大陆、瑞芯微、高通、英伟达等Al芯片深度融合,与浪潮、中科曙光等服务器厂商合作形成软硬一体的全栈Al基础设施。当前飞桨适配的芯片或IP超过30种,处于业界领先地位。

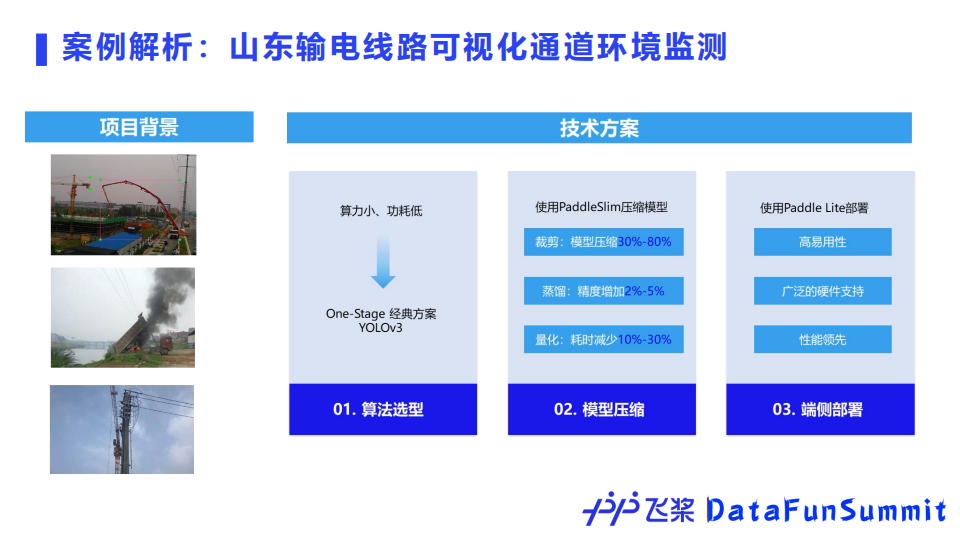
飞桨拥有丰富的产业实践案例,以山东国家电网输电线路可视化通道环境监测为例。
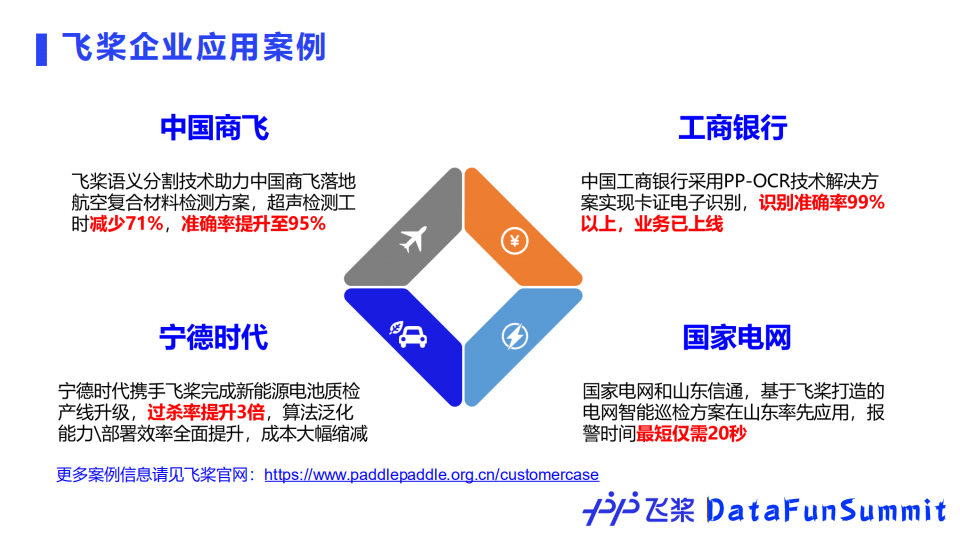
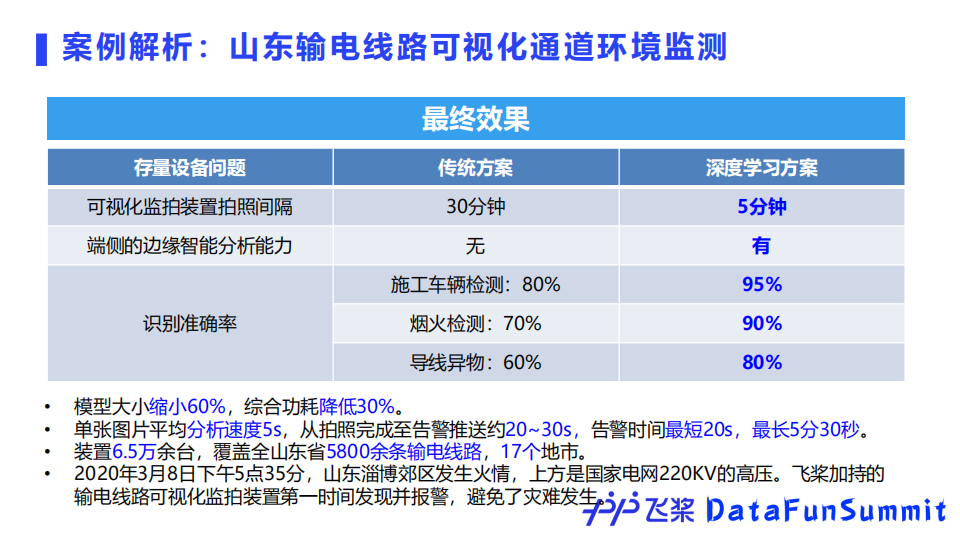
该项目需要对近景和远景中的输电线路进行检测,并且需要在原有数万存量监控设备基础上进行优化。存量的监控设备算力小、功耗低,为此飞桨团队选择了YOLOv3模型。
首先该模型可以满足精度上的要求,然后通过飞桨模型压缩工具PaddleSlim进行剪裁、蒸馏、量化,使之可以部署到内存有限的存量设备上;最后通过飞桨轻量化推理引擎Paddle Lite成功部署上线,实现了输电通道的可视化巡检、重大火情极速预警。
良好的生态有助于用户更便捷地使用开源产品。当前飞桨开源社区累计提交commits超过50万次,以PR或ISSUE提交形式的开源贡献者超过了15000人。
飞桨会定期组织各种分享活动,将来自各地的开发爱好者集中在一起相互交流,并通过AI Studio学习与实训社区,为广大开发者免费提供丰富的教程、视频课程以及算力。
在企业方向,飞桨还会举办AI快车道、AICA首席AI架构师培养计划等培训活动,为产业界培养更多的人才,不断提升飞桨的影响力。
Q1:Paddle Lite和TensorFlow Lite区别?
A:Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及服务器端在内的多硬件平台,因此在硬件支持方面,Paddle Lite对硬件支持更加完善,尤其是对国产AI硬件的支持,比如百度XPU、华为麒麟NPU、华为昇腾 NPU、联发科APU等其他硬件,同时也支持更多的操作系统,比如Windows、MacOS等。另一方面,根据内部测试结果,Paddle Lite在部分主流推理模型上,以及部分主流硬件上也有更加优异的性能表现。
Q2:对于动态图和静态图,支持动静结合模型的决策在什么阶段、有什么样的动力推动了整个设计?
A:自2016年飞桨开源后,整个团队就一直非常关注外部开发者的反馈。通过调研,很多开发者对动态图的需求非常强烈。针对企业上线场景需求,推理部署的对接必须要有动态图到静态图转换的功能。2018年飞桨开始动态图的开发,同时也筹备并实现了动静转换的功能。
今天的分享就到这里,谢谢大家。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“深度学习” 就可以获取《深度学习专知资料合集》专知下载链接





