Local GAN
点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
扫码回复:LocalGAN,获取下载链接
概述
背景

Local GAN
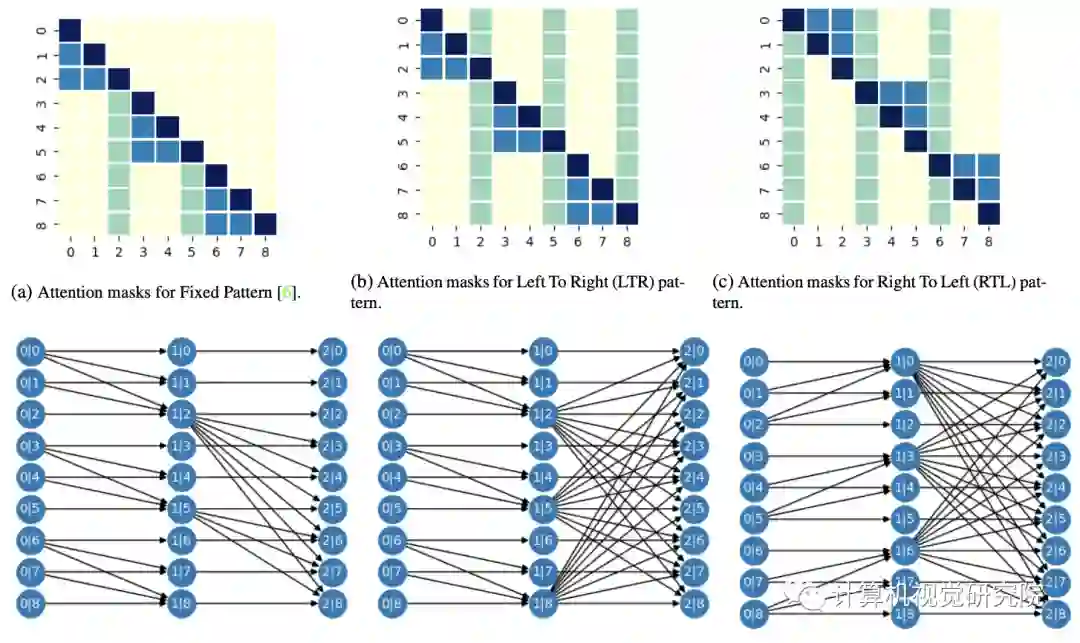
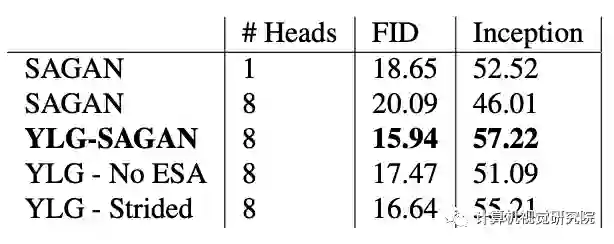
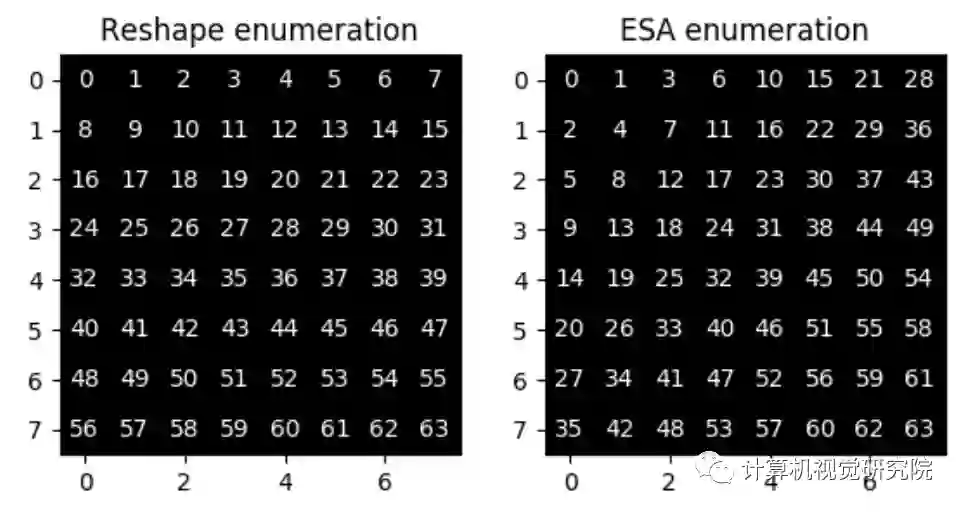
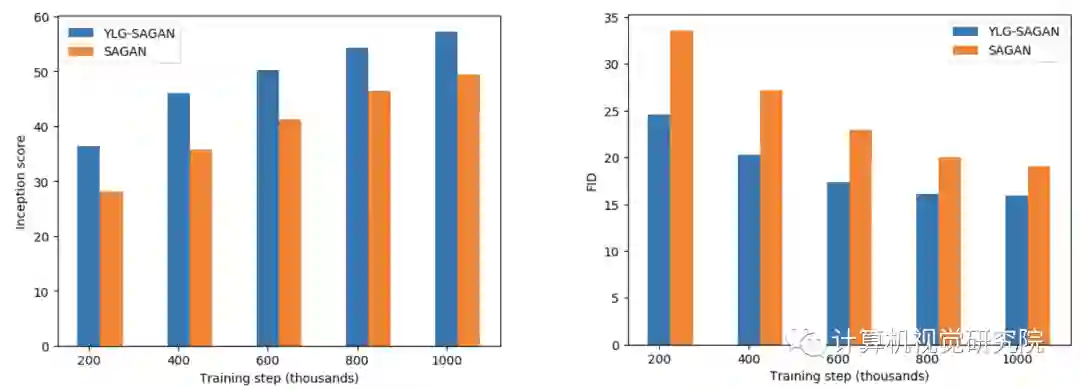
实验&验证


Inverting Generative Models with Attention
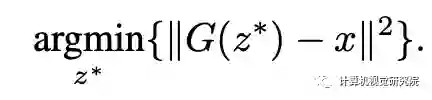
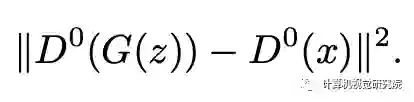
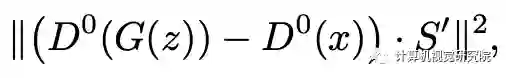



总结



扫码关注我们
公众号 : 计算机视觉战队
扫码回复:LocalGAN,获取下载链接
登录查看更多
相关内容

专知会员服务
37+阅读 · 2020年2月27日
专知会员服务
37+阅读 · 2020年1月12日




相关VIP内容
专知会员服务
37+阅读 · 2020年2月27日
专知会员服务
37+阅读 · 2020年1月12日
相关资讯
相关论文