【KDD2020】图神经网络的无冗余计算

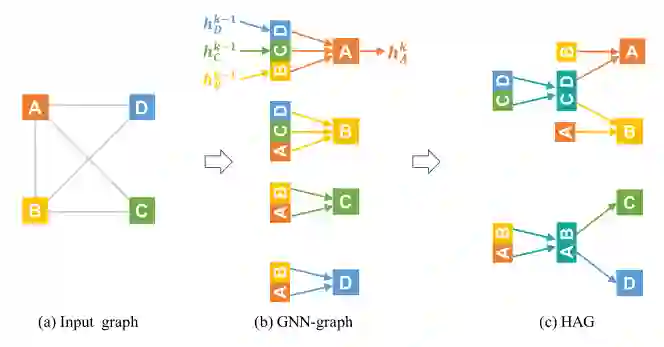
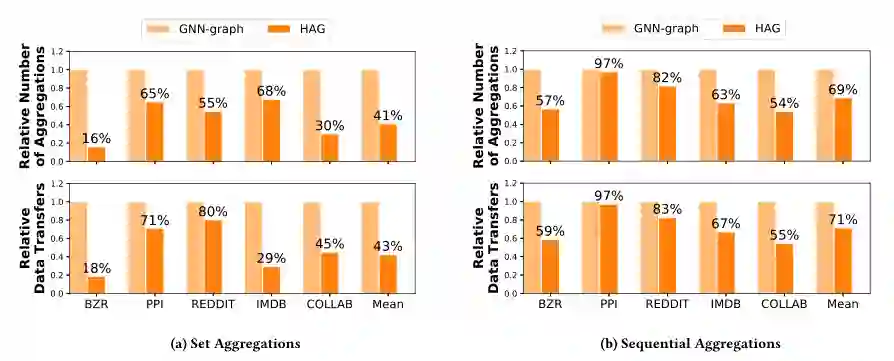
Set Aggregate: 大部分GNN都会假设节点的邻居是无序的,并且聚合是关联和交换的操作,这些操作和聚合的执行顺序是没有关系的。在表一的示例中有表示summation aggregation的GCN和element-wise aggregation的GraphSAGE-P。注意,GNN中的set aggregation的过程顺序是不会发生变化的,因此是可以按照HAG对其进行分层聚合。
Sequential Aggregate:另一类GNN需要对节点的邻居进行特定的排序,并且对应的聚合顺序是不可以交换的。例如表一中N-ary Tree-LSTM和GraphSAGE中的LSTM变体。HAG可以通过识别相同的节点序列集合,聚合这些节点。

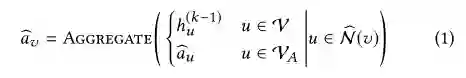
使用了HAG的GNN和传统GNN的唯一区别在于如何计算每一个GNN的领域聚合的过程(即 ),在聚合过程中,该文章增加了一个步骤用来存储常用的中间聚合的结果,用以减少冗余的计算,即为algorithm1的第3~4行。
同时,该文证明了使用HAG进行中间聚合的GNN和原始GNN会有完全相同的输出和梯度。当GNN模型在每层的输出相同的激活表示 且在GNN进行反向传播的过程当中所有的训练参数都保证了相同的计算梯度,那么与原始GNN和GNN with HAG二者就是等价的。
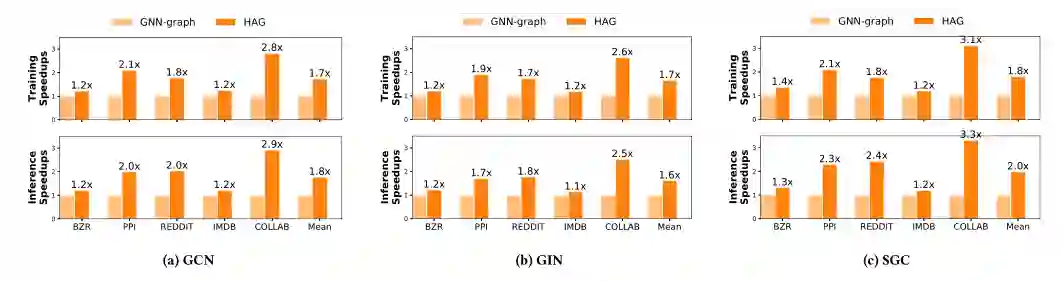
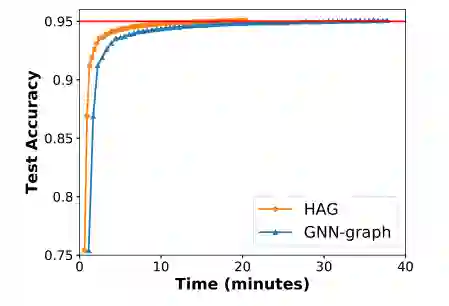
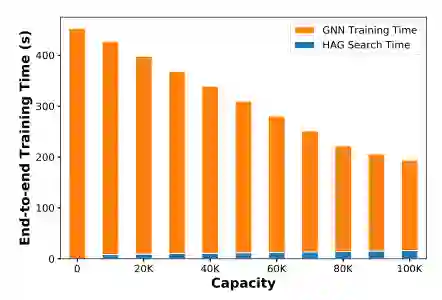
尽管在训练过程中,加入了新的中间节点 ,这个内存的开销也近乎可以不用考虑,实验证明这部分开销仅占原始的开销的0.1%,同时能够将训练的速度提高2.8倍。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GNNC” 就可以获取《【KDD2020】图神经网络的无冗余计算》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文