经典论文复现 | 基于深度学习的图像超分辨率重建
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
来源:PaperWeekly
作者丨Molly
学校丨北京航天航空大学
研究方向丨计算机视觉
笔者本次选择复现的是汤晓鸥组 Chao Dong 的作品,这篇论文也是深度学习应用在超分辨率重构上的开山之作。

论文复现代码:
http://aistudio.baidu.com/#/projectdetail/23978
超分辨率重构
单图像超分辨率重构(SR)可以从一张较小的图像生成一张高分辨率的图像。显然,这种恢复的结果是不唯一的。可以这样直观地理解:远远看到一个模糊的身影,看不清脸,既可以认为对面走来的是个男生,也可以认为这是个女生。那么,当我想象对面人的长相时,会如何脑补呢?
这就依赖于我们的先验知识。假如我认为,一个穿着裙子的人肯定是个女生,而对面那个人穿着裙子,所以我认为那是个女生,脑补了一张女神脸。然而,如果我知道穿裙子的人不一定是女生,还可能是女装大佬。迎面走来那个人瘦瘦高高,所以我认为十有八九是个男孩子,就会脑补一个……
也就是说,不同的先验知识,会指向不同的结果。我们的任务,就是学习这些先验知识。目前效果最好的办法都是基于样本的(example-based)

▲ 超分辨率重构的结果。SRCNN所示为论文提出的模型的结果,可以看出,边缘更加清晰。
论文提出一种有趣的视角:CNN 所构造的模型和稀疏编码方法(sparse coding based)是等价的。稀疏编码方法的流程如下:
1.从原始图片中切割出一个个小块,并进行预处理(归一化)。这种切割是密集的,也就是块与块之间有重叠;
2. 使用低维词典(low-resolution dictionary)编码,得到一个稀疏参数;
3. 使用高维词典(high-resolution dictionary)结合稀疏参数进行重建(换了个密码本);
4. 将多个小块拼接起来,重合部分使用加权和拼接。
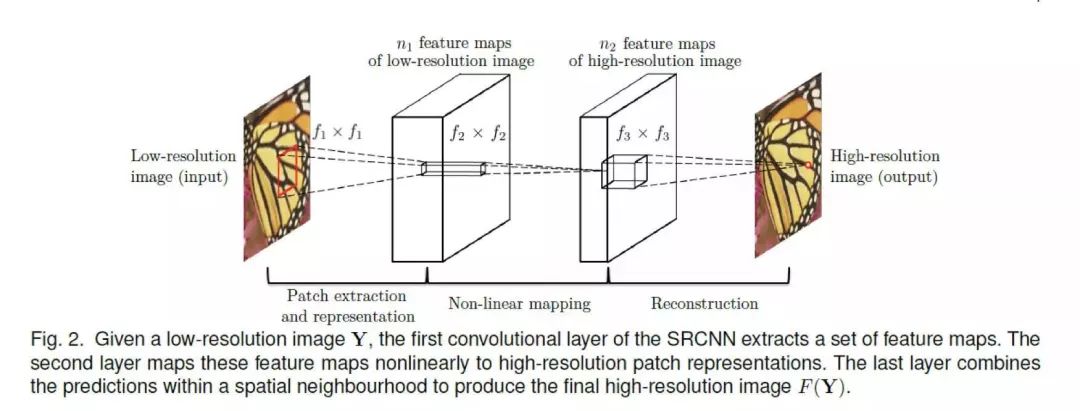
上图是卷积神经网络对应于稀疏编码的结构。对于一个低分辨率图像 Y,第一个卷积层提取 feature maps。第二个卷积层将 feature maps 进行非线性变换,变换为高分辨率图像的表示。最后一层恢复出高分辨率图像。
相比于稀疏编码,论文提出的模型是 end-to-end 的,便于优化。并且,不需要求最小二乘的解,运算速度更快。
模型构造和训练
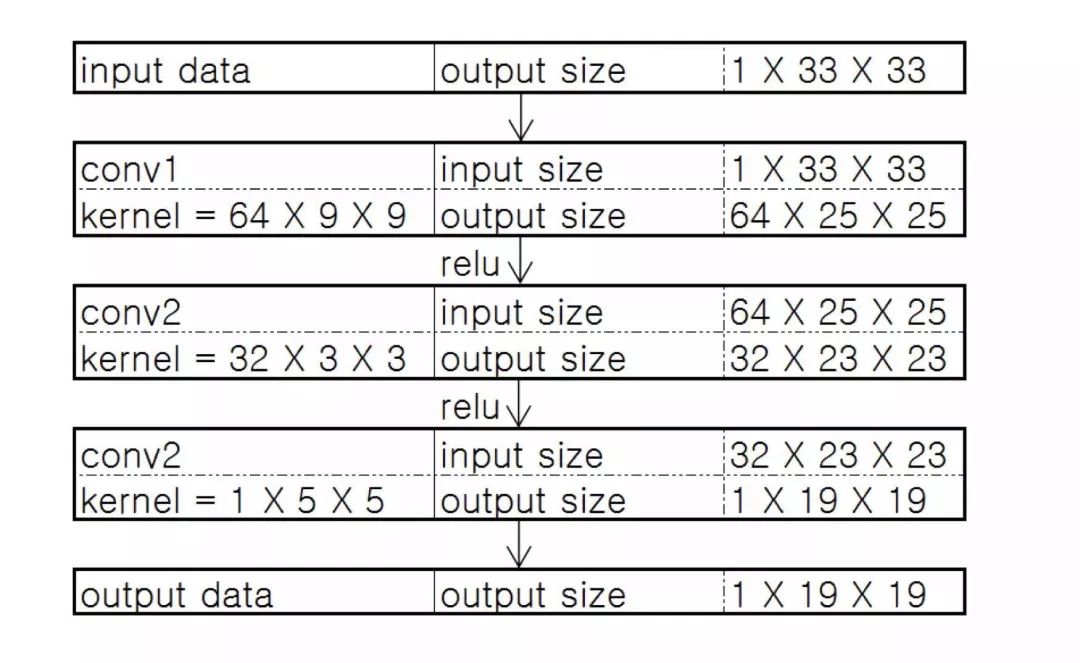
模型的结构
这是一个 base-line 模型。如下图,f1=9,f2=1,f3=5,n1=64,n2=32,前两层使用 relu 作为激活函数。输入为图像的 Y 通道。
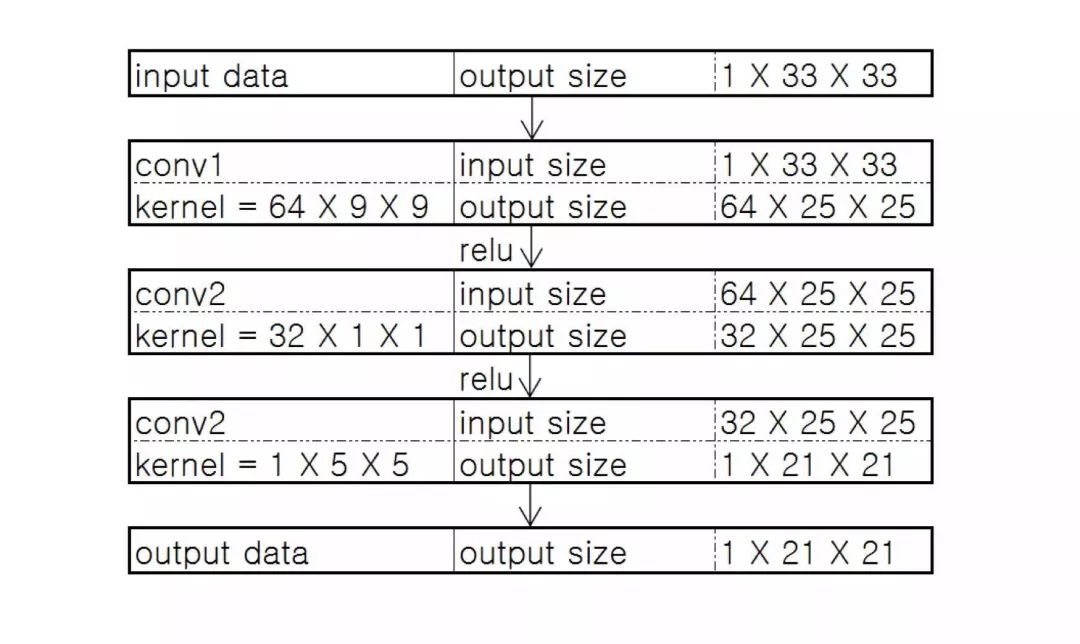
为了减轻边界带来的影响,论文使用 valid 方式处理卷积的边界。所以模型输出的结果是比输入要小一点点的。 显然,这是一个 FCN 的网络。我们使用图像的一个个 patch 进行训练,在测试时输入为一整张图片。由于没有全连接层,输入图像的大小可以是任意的。
训练数据
为了使模型更好地收敛,我们在原始的训练数据集上面切出一系列 33 X 33 大小的图像进行训练,切割的步长为 14。也就是说,我们使用的训练集图像,是有互相重合的部分的。
我们使用的是 timofte 数据集,共 91 张图片。论文中进行对比试验的时候,使用的都是 ImageNet 数据集。相比于 timofte,ImageNet 数据集可以提供更丰富的样本,得到更好的训练结果。但是 91 张图片给出的样本已经很丰富了,并且模型本身参数也不多,还不至于过拟合。所以使用 ImageNet 对结果的提升比较有限。
我们进行论文复现的时候,考虑到计算资源限制,使用 timofte 数据集,可以得到相似的结果。 我们使用 set5 作为验证集,使用 set14 可以得到类似的结论。

▲ 数据读取代码展示
损失函数和模型评估
我们使用 MSE 作为损失函数,即:
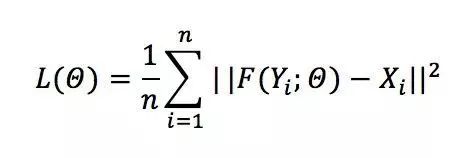
其中,是模型中的所有参数。 如上文所述,我们使用 valid 方式处理边界,所以输出的图像比输入图像略小。计算损失值时,只使用输入图像中间和输出图像对应位置的部分进行计算。
由于超分辨率重建的结果是不唯一的,所以其结果的评估往往比较困难。论文使用峰值信噪比(PSNR)作为模型的评价指标。它和人眼的感受并不完全一致。可能会出现指标很高,但是人眼感受不太好的情况。但是,它仍然是广为接受的指标。 PSNR 的计算公式如下:
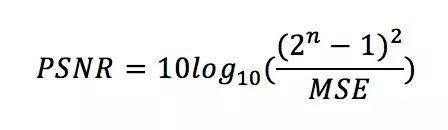
其中,n 为每像素的比特数,一般取 8。
模型训练结果
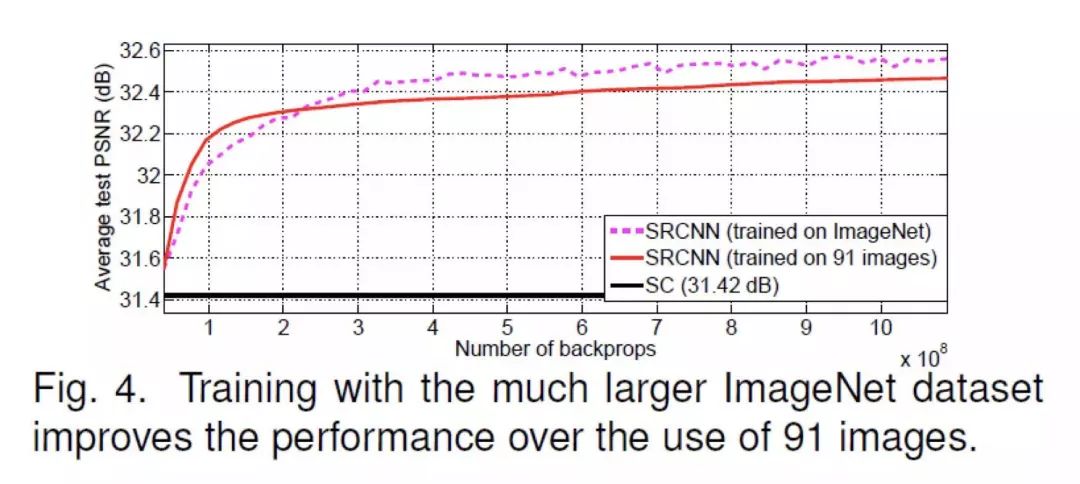
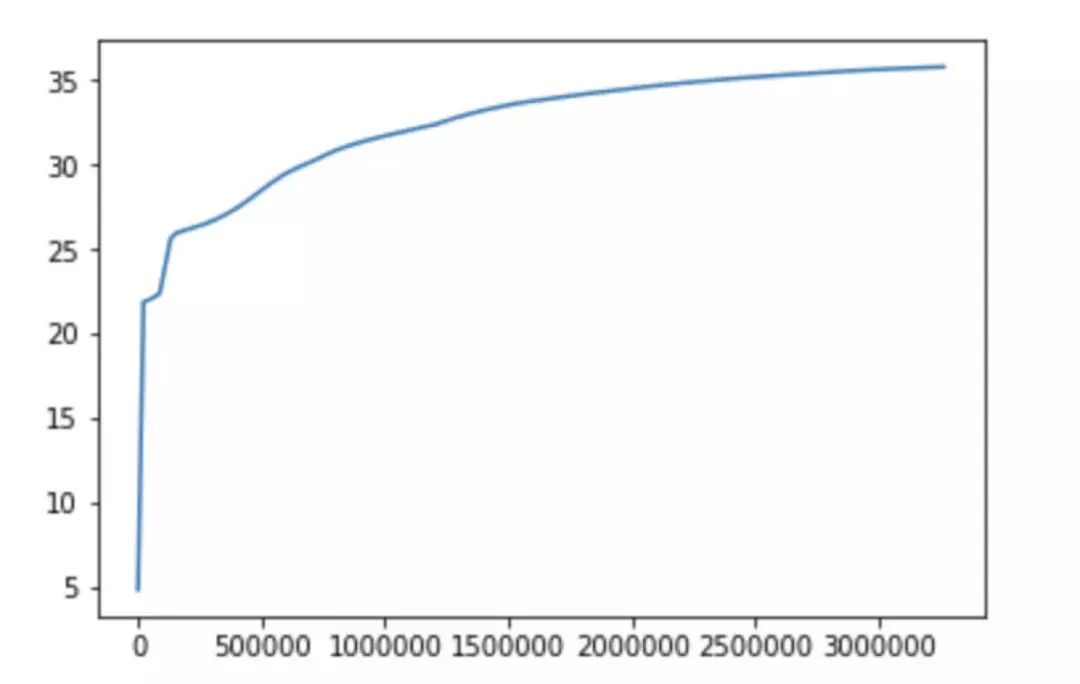
当训练的 backprops 数达到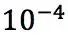
这里有一个 trick,就是最后一层的学习率和前两层不同。这个设置是非常重要的,在实际测试中发现,使用这样的设置,模型收敛更加稳定。而所有层使用相同的学习率时,很容易出现 model collapse。
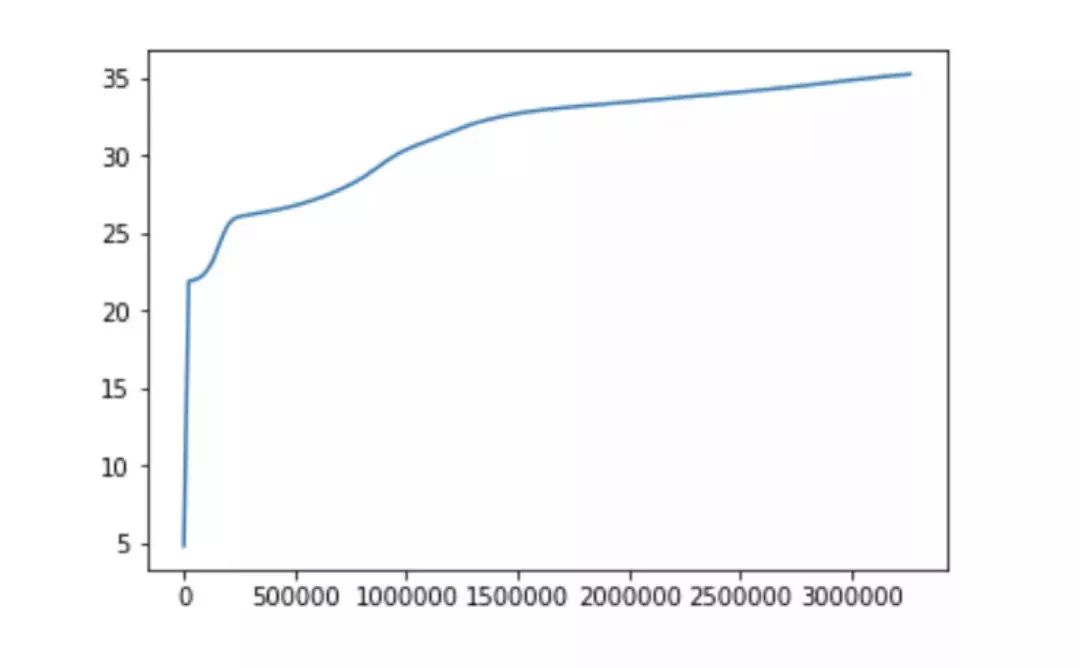
图中横轴是反向传播次数(batchsize * batchnum)。纵轴是 PSNR 值(dB)。可见,收敛速度比论文中快了很多,效果也更好。经过 150 个 epoch 的迭代,最终在 set5 测试集上 PSNR 达到了 35.25dB。 看一下恢复出来的图片是什么样的。Y 通道使用 SRCNN 恢复,Cr,Cb 通道使用 bicubic 插值。




另一张图片:


对比一下高频细节,可见重构的效果还是不错的:上图为输入,下图为输出。


构造更深的网络模型
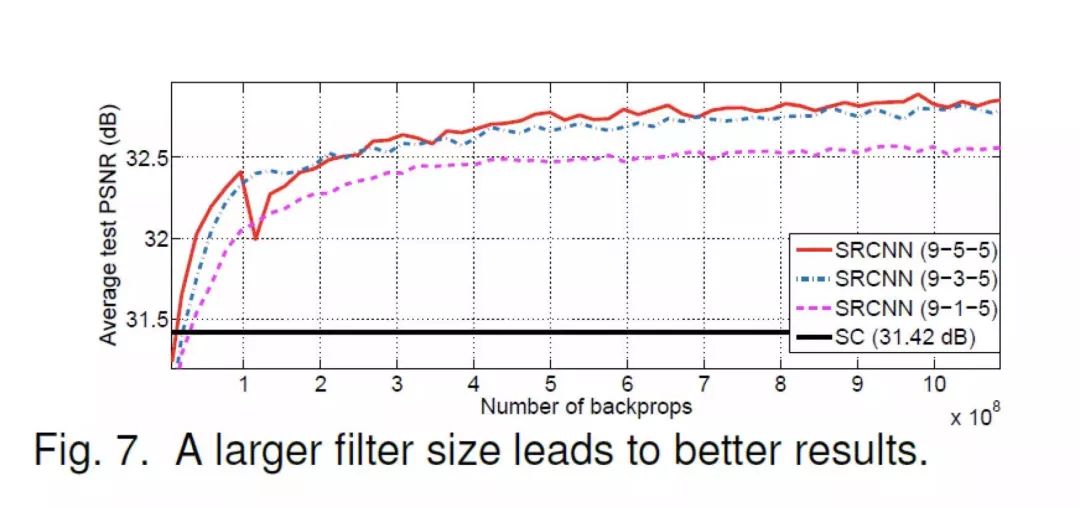
论文给出来的结果大同小异,结论是类似的。我们这里复现 filter size 改变的结果。
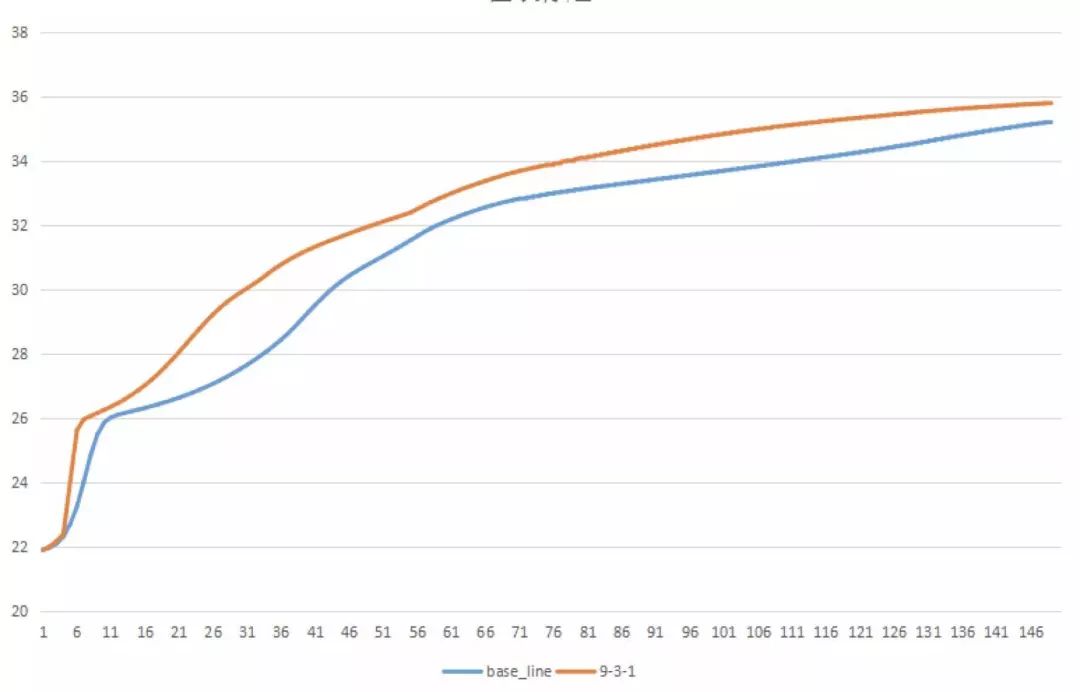
PSNR 曲线为:
使用 9-3-1 的模型结构,150 个 epoch 之后的 PSNR 值为 35.82。我们做一个对比图片,可以看出,虽然收敛速度、最终收敛结果不同(因为用的是不同的 Optimizor),但是得到的结论是一致的。
论文中的结果为:
三通道 RGB 训练结果
输入图像为 RGB 三个通道。
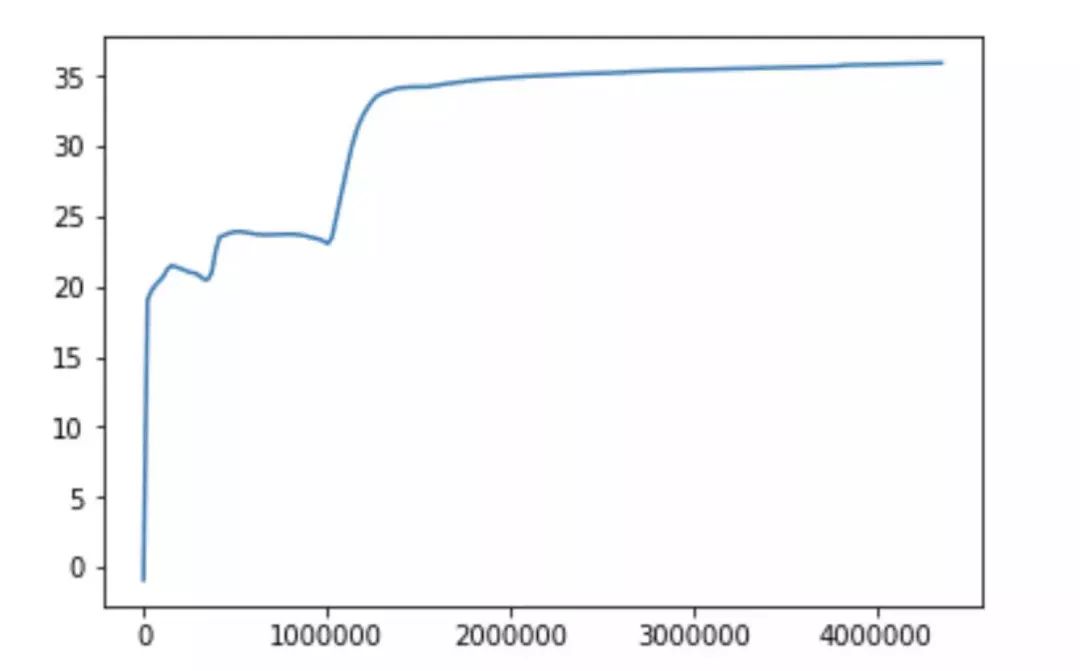
模型训练比较困难,很容易出现 model collapse 。使用单通道的参数作为预训练参数,再此基础上进行训练。经过更长的迭代次数(200 个 epoch),PSNR 达到了 35.92。
看一下 3 个通道训练结果:



对比一下高频细节,左图是输入,右图是输出:

总结
SRCNN 网络是 CNN 应用在超分辨率重建领域的开山之作。虽然论文尝试了更深的网络,但是相比于后来的神经网络,如 DRCN 中的网络,算是很小的模型了。受限于模型的表达能力,最终训练的结果还有很大的提升空间。
另外,虽然相比于 sparse coding 方法,SRCNN 可以算是 end to end 方法了。但是仍然需要将图片进行 bicubic 差值到同样大小。此后的 ESPCN 使用 sub-pixel convolutional layer,减少了卷积的运算量,大大提高了超分辨率重建的速度。
在复现的过程中,笔者发现 SGD 收敛速度相当慢,论文中曲线横轴都是数量级。使用 Adam 优化器,收敛速度更快,并且几个模型的 PSNR 值更高。说明使用 SGD 训练时候,很容易陷入局部最优了。
(End)
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
*推荐文章*
Machine Learning Yearning book draft - 读记(前14章)
资料|Andrew Ng机器学习新书下载
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~



