经典论文复现 | 基于标注策略的实体和关系联合抽取

过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
作者丨戴一鸣
学校丨清华海峡研究院
研究方向丨自然语言处理
引言
笔者本次复现的是中科院自动化所发表于 ACL 2017 的经典文章——Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme。


对于实体和关系的联合抽取一直是信息抽取中重要的任务。为了解决这一问题,论文提出了一个新型的标注方式,可以解决联合信息抽取中的标注问题。随后,基于这一标注方法,论文研究了不同的端到端模型,在不需要分开识别实体和关系的同时,直接抽取实体和实体之间的关系。
论文在使用了远程监督制作的公开数据集上进行了实验,结果说明这一标注策略较现有的管道和联合学习方法。此外,论文所提出的端到端模型在公开数据集上取得了目前最好的效果。
论文复现代码:
http://aistudio.baidu.com/aistudio/#/projectdetail/26338
论文方法
论文提出了一个新型的标注方式,并设计了一个带有偏置(Bias)目标函数的端到端模型,去联合抽取实体和实体间的关系。
标注方式
图 1 是一个如何将原始标注数据(实体+实体关系)转换为论文中提到的新型标注方式的示例。在数据中,每一个词汇会被赋予一个实体标签,因此通过抽取和实体有关的词语,构成实体。
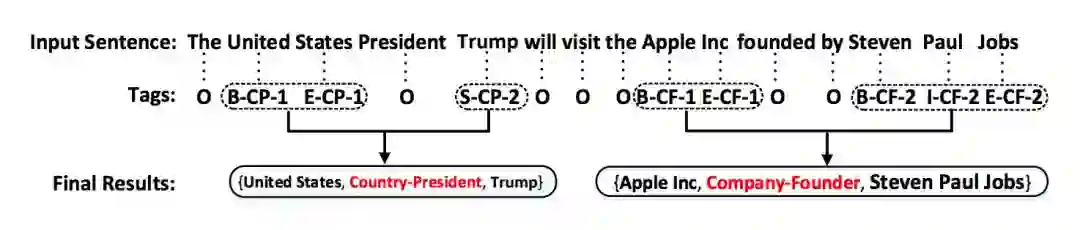
▲ 图1. 一个构成实体和关系的数据实例
第一个标签是“O”,表示这个词属于“Other”标签,词语不在被抽取结果中。除了标签“O”以外,其他标签都由三部分组成:1)词语在实体中的位置,2)实体关系类型,3)关系角色。
论文使用“BIES”规则(B:实体起始,I:实体内部,E:实体结束,S:单一实体)去标注词语在实体中的位置信息。对于实体关系类型,则通过预先定义的关系集合确定。对于关系角色,论文使用“1”和“2”确定。一个被抽取的实体关系结果由一个三元组表示(实体 1-关系类型-实体 2)。“1”表示这个词语属于第一个实体,“2”则表示这个词语属于第二个实体。因此,标签总数是:Nt = 2*4 *|R|+1。R 是预先定义好的关系类型的数量。
从图 1 可以看出,输入的句子包含两个三元组:
{United States, Country-President, Trump}
{Apple Inc, Company-Founder, Steven Paul Jobs}
预先定义的两组关系是:
Country-President: CP
Company-Founder:CF
由于“United”,“States”,“ Trump”,“Apple”,“Inc” ,“Steven”, “Paul”, “Jobs”构成了描述实体的词汇,因此这些词语都被赋予了特定的标记。
例如,“United”是实体“United States”的第一个词语,同时也和“Country-President”关联,因此“United”词语的标注是“B-CP-1”。“B”表示Begin,“CP”表示Country President,“1”表示“United”词语所在的实体“United States”是三元组中的第一个对象。
同理,因为“States”是“United States”实体的结尾词语,但依然属于“Country President”关系,同时也是三元组的第一个对象,因此“States”的标注是“E-CP-1”。
对于另一个词语“Trump”,它是构成“Trump”这一实体的唯一词语,因此使用“S”。同时,Trump 实体属于“Country President”关系,因此它具有CP标签,又同时这一实体在三元组中是第二个对象,因此它被标注“2”。综上,“Trump”这一词语的标注是:“S-CP-2”。除了这些和实体有关的词语外,无关词语被标注“O”。
当然,对于拥有两个和两个以上实体的句子,论文将每两个实体构成一个三元组,并使用最小距离原则(距离最近的两个实体构成一对关系)。在图 1 中,“United States”和“Trump”因为最小距离构成了一对实体。此外,论文只探讨一对一关系三元组。
端到端模型
双向长短时编码层(Bi-LSTM Encoder Layer)
在序列标注问题中,双向长短时编码器体现了对单个词语的语义信息的良好捕捉。这一编码器有一个前向和后向的长短时层,并在末尾将两层合并。词嵌入层则将词语的独热编码(1-hot representation)转换为词嵌入的向量。
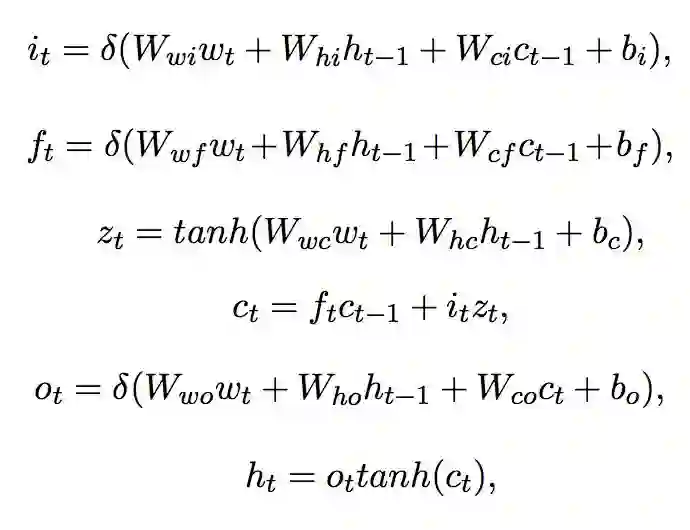
▲ 公式1. 双向长短时编码器
公式 1 中的 i,f 和 o 分别为 LSTM 模块在 t 时刻的输入门,遗忘门和输出门。c 为 LSTM 模块的输出,W 为权重。对于当前时刻,其隐层向量的结果取决于起义时刻的
,上一时刻的
,以及当前时刻的输入词语
。
对于一句话,表示为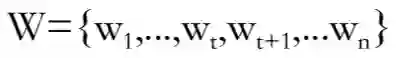
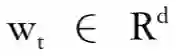
对于每一个词语向量(经过词嵌入后), 前向长短时神经网络层通过考虑语义信息,将
到
的信息全部编码,记为
。同样,后向长短时则为
。编码器最后将两个层的输入相接。
长短时解码器
论文同时使用了长短时解码器用于标注给定序列。解码器在当前时刻的输入为来自双向编码器的隐层向量,前一个预测的标签的嵌入
,前一个时刻的神经元输入
,以及前一时刻的隐层向量
。解码器根据双向长短时编码器的输出进行计算。解码器的内部公式类似于公式 1。
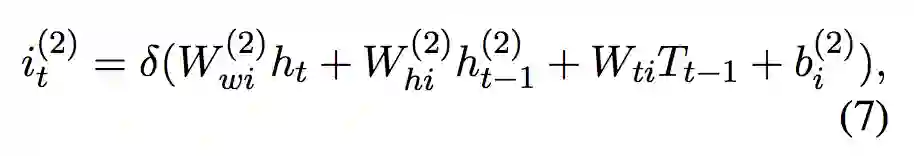
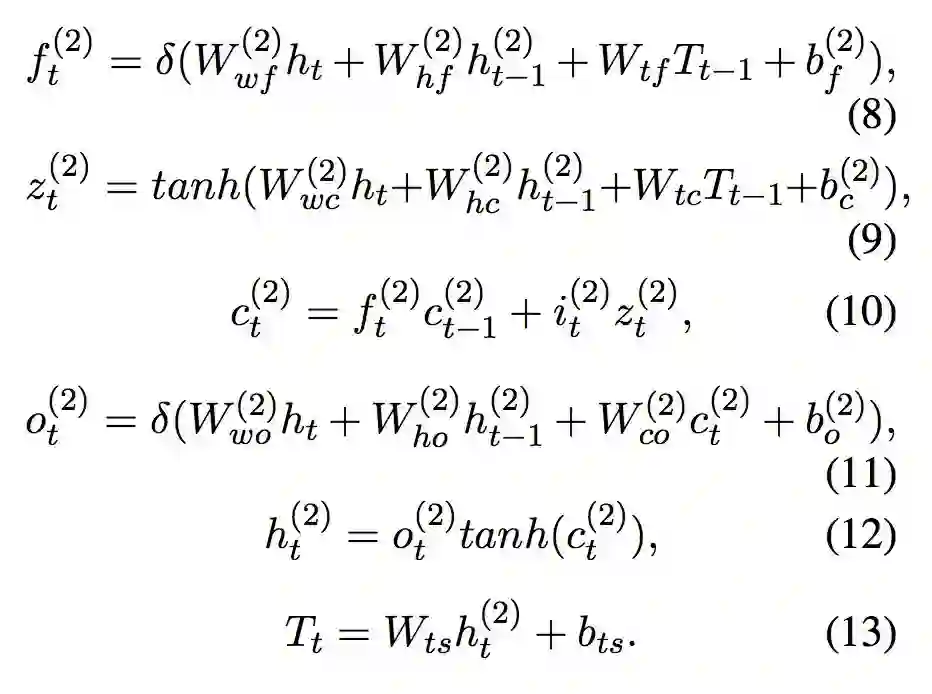
▲ 公式2. 长短时解码器
Softmax层
在解码器后加入 softmax 层,预测该词语的标签。解码器的内部结构类似于编码器。
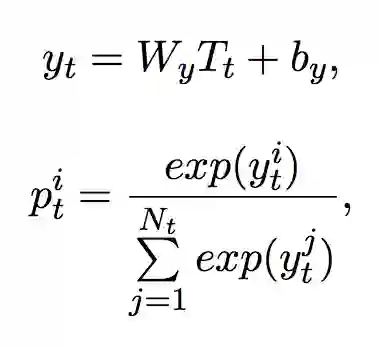
▲ 公式3. softmax层
为 softmax 矩阵,
为总标签数,
为预测标签的向量。
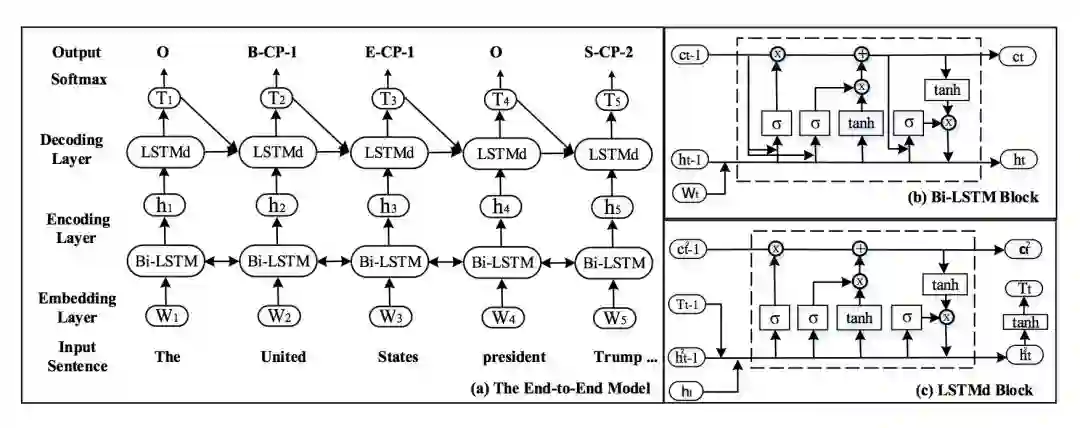
▲ 图2. 网络整体结构图
偏置目标函数(Bias Objective Function)
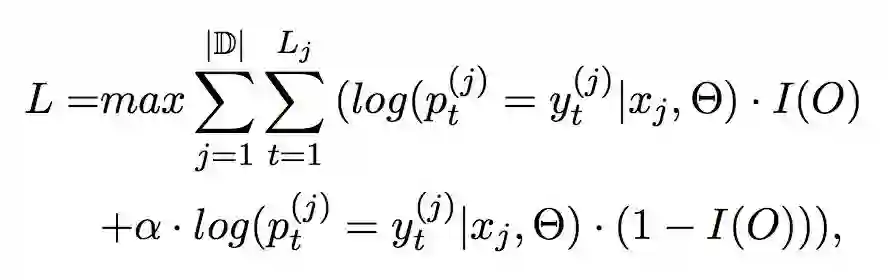
▲ 公式4. 训练中激活函数使用RMSprop
|D| 是训练集大小,是句子
的长度,
是词语 t 在
的标签,
是归一化的 tag 的概率。I(O) 是一个条件函数(switching function),用于区分 tag 为“O”和不为“O”的时候的损失。
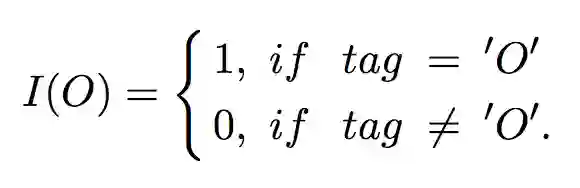
▲ 公式5. 条件函数
α 是偏置权重,该项越大,则带关系的标签对模型的影响越大。
import paddle.fluid as fluid
import paddle.v2 as paddle
from paddle.fluid.initializer import NormalInitializer
import re
import math
#coding='utf-8'
import json
import numpy as np
from paddle.v2.plot import Ploter
train_title = "Train cost"
test_title = "Test cost"
plot_cost = Ploter(train_title, test_title)
step = 0
#=============================================global parameters and hyperparameters==================================
EMBEDDING = 300
DROPOUT = 0.5
LSTM_ENCODE = 300
LSTM_DECODE = 600
BIAS_ALPHA = 10
VALIDATION_SIZE = 0.1
TRAIN_PATH = '/home/aistudio/data/data1272/train.json'
TEST_PATH = '/home/aistudio/data/data1272/test.json'
FILE_PATH = '/home/aistudio/data/'
X_TRAIN = '/home/aistudio/data/data1272/sentence_train.txt'
Y_TRAIN = '/home/aistudio/data/data1272/seq_train.txt'
X_TEST = '/home/aistudio/data/data1272/sentence_test.txt'
Y_TEST = '/home/aistudio/data/data1272/seq_test.txt'
WORD_DICT = '/home/aistudio/data/data1272/word_dict.txt'
TAG_DICT = '/home/aistudio/data/data1272/tag_dict.txt'
EPOCH_NUM = 1000
BATCH_SIZE = 128
#=============================================get data from the dataset==============================================
def get_data(train_path, test_path, train_valid_size):
'''
extracting data for json file
'''
train_file = open(train_path).readlines()
x_train = []
y_train = []
for i in train_file:
data = json.loads(i)
x_data, y_data = data_decoding(data)
'''
appending each single data into the x_train/y_train sets
'''
x_train += x_data
y_train += y_data
test_file = open(test_path).readlines()
x_test = []
y_test = []
for j in test_file:
data = json.loads(j)
x_data, y_data = data_decoding(data)
x_test += x_data
y_test += y_data
return x_train, y_train, x_test, y_test
def data_decoding(data):
'''
decode the json file
sentText is the sentence
each sentence may have multiple types of relations
for every single data, it contains: (sentence-splited, labels)
'''
sentence = data["sentText"]
relations = data["relationMentions"]
x_data = []
y_data = []
for i in relations:
entity_1 = i["em1Text"].split(" ")
entity_2 = i["em2Text"].split(" ")
relation = i["label"]
relation_label_1 = entity_label_construction(entity_1)
relation_label_2 = entity_label_construction(entity_2)
output_list = sentence_label_construction(sentence, relation_label_1, relation_label_2, relation)
x_data.append(sentence.split(" "))
y_data.append(output_list)
return x_data, y_data
def entity_label_construction(entity):
'''
give each word in an entity the label
for entity with multiple words, it should follow the BIES rule
'''
relation_label = {}
for i in range(len(entity)):
if i == 0 and len(entity) >= 1:
relation_label[entity[i]] = "B"
if i != 0 and len(entity) >= 1 and i != len(entity) -1:
relation_label[entity[i]] = "I"
if i== len(entity) -1 and len(entity) >= 1:
relation_label[entity[i]] = "E"
if i ==0 and len(entity) == 1:
relation_label[entity[i]] = "S"
return relation_label
def sentence_label_construction(sentence, relation_label_1, relation_label_2, relation):
'''
combine the label for each word in each entity with the relation
and then combine the relation-entity label with the position of the entity in the triplet
'''
element_list = sentence.split(" ")
dlist_1 = list(relation_label_1)
dlist_2 = list(relation_label_2)
output_list = []
for i in element_list:
if i in dlist_1:
output_list.append(relation + '-' + relation_label_1[i] + '-1' )
elif i in dlist_2:
output_list.append(relation + '-' + relation_label_2[i] + '-2')
else:
output_list.append('O')
return output_list
def format_control(string):
str1 = re.sub(r'\r','',string)
str2 = re.sub(r'\n','',str1)
str3 = re.sub(r'\s*','',str2)
return str3
def joint_extraction():
vocab_size = len(open(WORD_DICT,'r').readlines())
tag_num = len(open(TAG_DICT,'r').readlines())
def bilstm_lstm(word, target, vocab_size, tag_num):
x = fluid.layers.embedding(
input = word,
size = [vocab_size, EMBEDDING],
dtype = "float32",
is_sparse = True)
y = fluid.layers.embedding(
input = target,
size = [tag_num, tag_num],
dtype = "float32",
is_sparse = True)
fw, _ = fluid.layers.dynamic_lstm(
input = fluid.layers.fc(size = LSTM_ENCODE*4, input=x),
size = LSTM_ENCODE*4,
candidate_activation = "tanh",
gate_activation = "sigmoid",
cell_activation = "sigmoid",
bias_attr=fluid.ParamAttr(
initializer=NormalInitializer(loc=0.0, scale=1.0)),
is_reverse = False)
bw, _ = fluid.layers.dynamic_lstm(
input = fluid.layers.fc(size = LSTM_ENCODE*4, input=x),
size = LSTM_ENCODE*4,
candidate_activation = "tanh",
gate_activation = "sigmoid",
cell_activation = "sigmoid",
bias_attr=fluid.ParamAttr(
initializer=NormalInitializer(loc=0.0, scale=1.0)),
is_reverse = True)
combine = fluid.layers.concat([fw,bw], axis=1)
decode, _ = fluid.layers.dynamic_lstm(
input = fluid.layers.fc(size = LSTM_DECODE*4, input=combine),
size = LSTM_DECODE*4,
candidate_activation = "tanh",
gate_activation = "sigmoid",
cell_activation = "sigmoid",
bias_attr=fluid.ParamAttr(
initializer=NormalInitializer(loc=0.0, scale=1.0)),
is_reverse = False)
softmax_connect = fluid.layers.fc(input=decode, size=tag_num)
_cost = fluid.layers.softmax_with_cross_entropy(
logits=softmax_connect,
label = y,
soft_label = True)
_loss = fluid.layers.mean(x=_cost)
return _loss, softmax_connect
source = fluid.layers.data(name="source", shape=[1], dtype="int64", lod_level=1)
target = fluid.layers.data(name="target", shape=[1], dtype="int64", lod_level=1)
loss, softmax_connect = bilstm_lstm(source, target, vocab_size, tag_num)
return loss
def get_index(word_dict, tag_dict, x_data, y_data):
x_out = [word_dict[str(k)] for k in x_data]
y_out = [tag_dict[str(l)] for l in y_data]
return [x_out, y_out]
def data2index(WORD_DICT, TAG_DICT, x_train, y_train):
def _out_dict(word_dict_path, tag_dict_path):
word_dict = {}
f = open(word_dict_path,'r').readlines()
for i, j in enumerate(f):
word = re.sub(r'\n','',str(j))
# word = re.sub(r'\r','',str(j))
# word = re.sub(r'\s*','',str(j))
word_dict[word] = i + 1
tag_dict = {}
f = open(tag_dict_path,'r').readlines()
for m,n in enumerate(f):
tag = re.sub(r'\n','',str(n))
tag_dict[tag] = m+1
return word_dict, tag_dict
def _out_data():
word_dict, tag_dict = _out_dict(WORD_DICT, TAG_DICT)
for data in list(zip(x_train, y_train)):
x_out, y_out = get_index(word_dict, tag_dict, data[0], data[1])
yield x_out, y_out
return _out_data
def optimizer_program():
return fluid.optimizer.Adam()
if __name__ == "__main__":
sentence_train, seq_train, sentence_test, seq_test = get_data(TRAIN_PATH,TEST_PATH,VALIDATION_SIZE)
train_reader = paddle.batch(
paddle.reader.shuffle(
data2index(WORD_DICT, TAG_DICT, sentence_train, seq_train),
buf_size=500),
batch_size=128)
test_reader = paddle.batch(
paddle.reader.shuffle(
data2index(WORD_DICT, TAG_DICT, sentence_test, seq_test),
buf_size=500),
batch_size=128)
place = fluid.CPUPlace()
feed_order=['source', 'target']
trainer = fluid.Trainer(
train_func=joint_extraction,
place=place,
optimizer_func = optimizer_program)
trainer.train(
reader=train_reader,
num_epochs=100,
event_handler=event_handler_plot,
feed_order=feed_order)
▲ 模型和运行函数train代码展示
实验
实验设置
数据集
使用 NYT 公开数据集。大量数据通过远程监督的方式提取。测试集则使用了人工标注的方式。训练集总共有 353k 的三元组,测试集有 3880 个。此外,预定义的关系数量为 24 个。
评价方式
采用标准的精确率(Precision)和召回率(Recall)以及 F1 分数对结果进行评价。当三元组中的实体 1,实体 2,以及关系的抽取均正确才可记为 True。10% 的数据用于验证集,且实验进行了 10 次,结果取平均值和标准差。
超参数
词嵌入使用 word2vec,词嵌入向量是 300 维。论文对嵌入层进行了正则化,其 dropout 概率为 0.5。长短时编码器的长短时神经元数量为 300,解码器为 600。偏置函数的权重 α 为 10。
论文和其他三元组抽取方法进行了对比,包括多项管道方法,联合抽取方法等。
实验结果
表 1 为实体和实体关系抽取的表现结果,本论文正式方法名称为“LSTM-LSTM-Bias”。表格前三项为管道方法,中间三项为联合抽取方法。
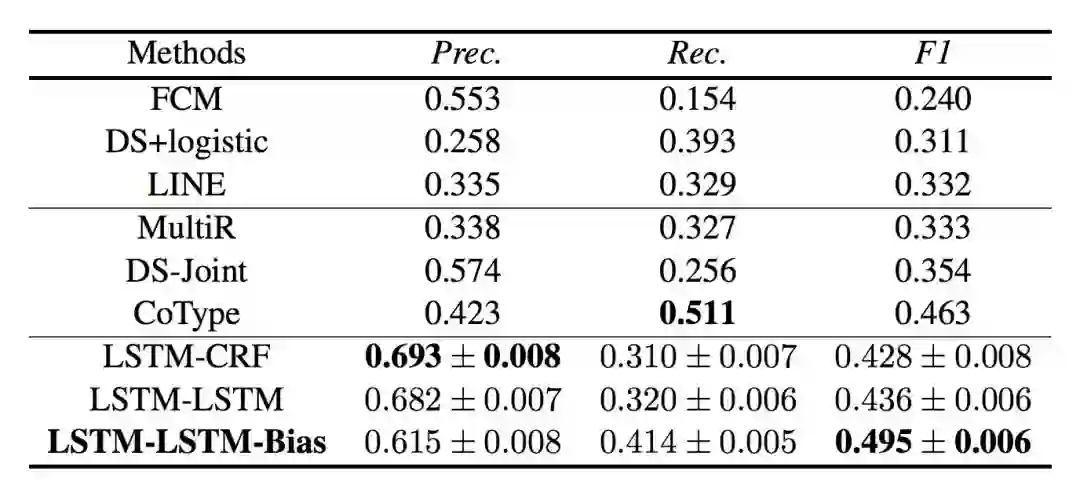
▲ 表1. 实体和实体关系抽取结果
从实验结果看出,论文提到的方法普遍优于管道方法和绝大多数联合抽取方法。本论文另一个值得注意的地方是,论文提出的方法较好地平衡了精确率和召回率的关系,尽管在精确率指标上略低于 LSTM-CRF。
表 1 也说明深度学习方法对三元组结果的抽取基本上好于传统方法。作者认为,这是因为深度学习方法在信息抽取中普遍使用双向长短时编码器,可以较好地编码语义信息。
在不同深度学习的表现对比中,作者发现,LSTM-LSTM 方法好于 LSTM-CRF。论文认为,这可能是因为 LSTM 较 CRF 更好地捕捉了文本中实体的较长依赖关系。
分析和讨论
错误分析
表 2 为深度学习方法对三元组各个元素的抽取效果对比,E1 表示实体 1 的抽取结果,E2 表示实体 2 的抽取结果,(E1,E2)表示实体的关系的抽取结果。

▲ 表2. 深度学习方法对三元组各元素抽取效果
表 2 说明,在对三元组实体的抽取中,对关系的抽取较三元组各个实体的抽取的精确率更好,但召回率更低。论文认为,这是由于有大量的实体抽取后未能组成合适的实体关系对。模型仅抽取了第一个实体 1,但未能找到合适的对应实体 2,或者仅有实体 2 被正确抽取出来。
此外,作者发现,表 2 的关系抽取结果比表 1 的结果提高了约 3%。作者认为,这是由于 3% 的结果预测错误是因为关系预测错误,而非实体预测错误导致的。
偏置损失分析
作者同时将论文方法和其他深度学习方法在识别单个实体(实体 1,实体 2)上的表现进行了对比。作者认为,虽然论文方法在识别单个实体上的表现低于其他方法,但能够更好地识别关系。
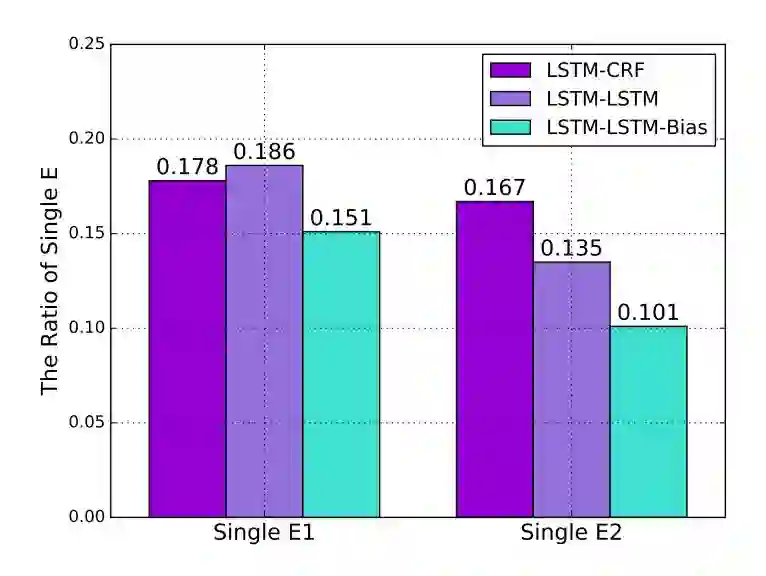
▲ 表3. 单个实体识别结果
作者对比发现,当偏置项等于 10 时,F1 数值最高。因此建议偏置项设为 10。
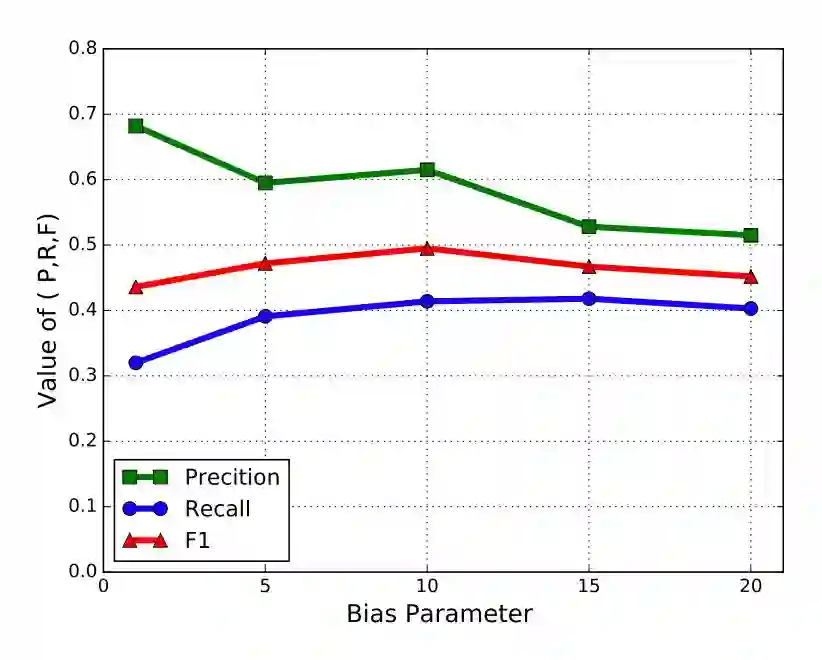
▲ 表4. 偏置项(α)数值和各项表现指标的关系
结论
本文提出一种新型的标注方式,将传统的命名实体识别和关系抽取任务联合起来,使用端到端模型进行直接联合信息抽取。在和传统方法以及深度学习方法的对比中均取得了满意的成果。
考虑到目前论文设计的实体关系抽取仅限于单个的关系,无法对一句话中重合的多个实体关系进行抽取,论文作者考虑使用多分类器替换 softmax 层,以便对词语进行多分类标注。
关于PaddlePaddle
使用 PaddlePaddle 进行工作大体上感觉不错,优点主要有:
1. 构建模型的过程较为顺利
PaddlePaddle 的官方文档较为清楚,大量的函数和 TensorFlow 主流框架对应,因此在寻找组件的时候可以找到。
2. 运行速度快
据了解,PaddlePaddle 底层优化较好,速度比 TensorFlow 快很多。
3. 对 GPU 的支持
主流框架目前都支持了 GPU,PaddlePaddle 也同样具有这一特性。
4. 动态图架构
在数据更加复杂的情况下,动态图的构建优势比静态图更为明显。PaddlePaddle 框架下的 fluid 版本甚至比 TensorFlow 的动态图支持更领先。
当然,考虑到 PaddlePaddle 依然年轻,仍有不少问题需要进一步优化:
1. 在笔者使用的时候,仍然不支持 Python 3.x(2018 年 9 月)。据说在 11 月份会开始支持 Python 3.x,正在期待中。
2. Debug 仍然困难。可能一方面是因为笔者使用了 AI studio 而非传统的 IDE 进行项目,另一方面是 PaddlePaddle 内部的优化问题,代码出错的时候,很难找到问题原因。这一点和 TensorFlow 有点像——各种各样的报错。
接下来期待 PaddlePaddle 更加支持 TPU 和 NPU,并更好地增加对小型移动设备和物联网系统的支持,使模型可以无障碍部署。

点击标题查看更多论文解读:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 收藏复现代码



