经典论文复现 | 基于深度卷积网络的图像超分辨率算法

过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
作者丨张荣成
学校丨哈尔滨工业大学(深圳)
研究方向丨计算数学
笔者本次选择复现的是汤晓鸥教授和何恺明团队发表于 2015 年的经典论文——SRCNN。超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。在深度卷积网络的浪潮下,本文首次提出了基于深度卷积网络的端到端超分辨率算法。


论文复现代码:
http://aistudio.baidu.com/aistudio/#/projectdetail/24446
SRCNN流程
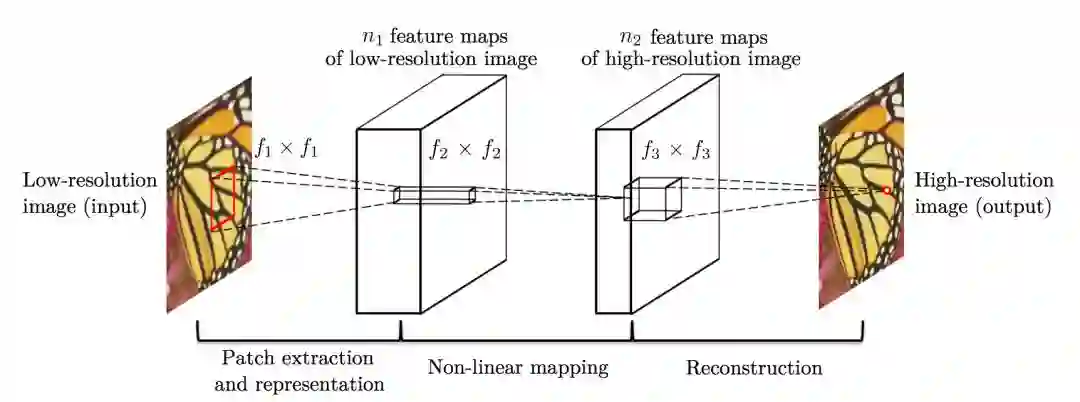
▲ SRCNN算法框架
SRCNN 将深度学习与传统稀疏编码之间的关系作为依据,将 3 层网络划分为图像块提取(Patch extraction and representation)、非线性映射(Non-linear mapping)以及最终的重建(Reconstruction)。
SRCNN 具体流程如下:
1. 先将低分辨率图像使用双三次差值放大至目标尺寸(如放大至 2 倍、3 倍、4 倍),此时仍然称放大至目标尺寸后的图像为低分辨率图像(Low-resolution image),即图中的输入(input);
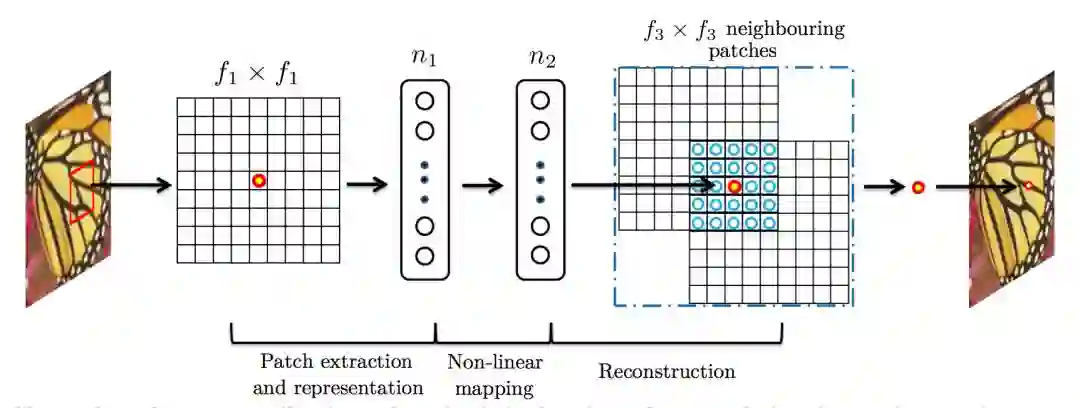
2. 将低分辨率图像输入三层卷积神经网络。举例:在论文其中一个实验相关设置,对 YCrCb 颜色空间中的 Y 通道进行重建,网络形式为 (conv1+relu1)—(conv2+relu2)—(conv3+relu3);第一层卷积:卷积核尺寸 9×9 (f1×f1),卷积核数目 64 (n1),输出 64 张特征图;第二层卷积:卷积核尺寸 1×1 (f2×f2),卷积核数目 32 (n2),输出 32 张特征图;第三层卷积:卷积核尺寸 5×5 (f3×f3),卷积核数目 1 (n3),输出 1 张特征图即为最终重建高分辨率图像。
训练
训练数据集
论文中某一实验采用 91 张自然图像作为训练数据集,对训练集中的图像先使用双三次差值缩小到低分辨率尺寸,再将其放大到目标放大尺寸,最后切割成诸多 33 × 33 图像块作为训练数据,作为标签数据的则为图像中心的 21 × 21 图像块(与卷积层细节设置相关)。
损失函数
采用 MSE 函数作为卷积神经网络损失函数。
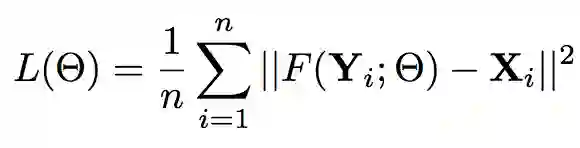
卷积层细节设置
第一层卷积核 9 × 9,得到特征图尺寸为 (33-9)/1+1=25,第二层卷积核 1 × 1,得到特征图尺寸不变,第三层卷积核 5 × 5,得到特征图尺寸为 (25-5)/1+1=21。训练时得到的尺寸为 21 × 21,因此图像中心的 21 × 21 图像块作为标签数据(卷积训练时不进行 padding)。
# 查看个人持久化工作区文件
!ls /home/aistudio/work/
# coding=utf-8
import os
import paddle.fluid as fluid
import paddle.v2 as paddle
from PIL import Image
import numpy as np
import scipy.misc
import scipy.ndimage
import h5py
import glob
FLAGS={"epoch": 10,"batch_size": 128,"image_size": 33,"label_size": 21,
"learning_rate": 1e-4,"c_dim": 1,"scale": 3,"stride": 14,
"checkpoint_dir": "checkpoint","sample_dir": "sample","is_train": True}
#utils
def read_data(path):
with h5py.File(path, 'r') as hf:
data = np.array(hf.get('data'))
label = np.array(hf.get('label'))
return data, label
def preprocess(path, scale=3):
image = imread(path, is_grayscale=True)
label_ = modcrop(image, scale)
label_ = label_ / 255.
input_ = scipy.ndimage.interpolation.zoom(label_, zoom=(1. / scale), prefilter=False) # 一次
input_ = scipy.ndimage.interpolation.zoom(input_, zoom=(scale / 1.), prefilter=False) # 二次,bicubic
return input_, label_
def prepare_data(dataset):
if FLAGS['is_train']:
data_dir = os.path.join(os.getcwd(), dataset)
data = glob.glob(os.path.join(data_dir, "*.bmp"))
else:
data_dir = os.path.join(os.sep, (os.path.join(os.getcwd(), dataset)), "Set5")
data = glob.glob(os.path.join(data_dir, "*.bmp"))
return data
def make_data(data, label):
if not os.path.exists('data/checkpoint'):
os.makedirs('data/checkpoint')
if FLAGS['is_train']:
savepath = os.path.join(os.getcwd(), 'data/checkpoint/train.h5')
# else:
# savepath = os.path.join(os.getcwd(), 'data/checkpoint/test.h5')
with h5py.File(savepath, 'w') as hf:
hf.create_dataset('data', data=data)
hf.create_dataset('label', data=label)
def imread(path, is_grayscale=True):
if is_grayscale:
return scipy.misc.imread(path, flatten=True, mode='YCbCr').astype(np.float) # 将图像转灰度
else:
return scipy.misc.imread(path, mode='YCbCr').astype(np.float) # 默认为false
def modcrop(image, scale=3):
if len(image.shape) == 3: # 彩色 800*600*3
h, w, _ = image.shape
h = h - np.mod(h, scale)
w = w - np.mod(w, scale)
image = image[0:h, 0:w, :]
else: # 灰度 800*600
h, w = image.shape
h = h - np.mod(h, scale)
w = w - np.mod(w, scale)
image = image[0:h, 0:w]
return image
def input_setup(config):
if config['is_train']:
data = prepare_data(dataset="data/data899/Train.zip_files/Train")
else:
data = prepare_data(dataset="Test")
sub_input_sequence = []
sub_label_sequence = []
padding = abs(config['image_size'] - config['label_size']) // 2 # 6 填充
if config['is_train']:
for i in range(len(data)):
input_, label_ = preprocess(data[i], config['scale']) # data[i]为数据目录
if len(input_.shape) == 3:
h, w, _ = input_.shape
else:
h, w = input_.shape
for x in range(0, h - config['image_size'] + 1, config['stride']):
for y in range(0, w - config['image_size'] + 1, config['stride']):
sub_input = input_[x:x + config['image_size'], y:y + config['image_size']] # [33 x 33]
sub_label = label_[x + padding:x + padding + config['label_size'],
y + padding:y + padding + config['label_size']] # [21 x 21]
# Make channel value,颜色通道1
sub_input = sub_input.reshape([config['image_size'], config['image_size'], 1])
sub_label = sub_label.reshape([config['label_size'], config['label_size'], 1])
sub_input_sequence.append(sub_input)
sub_label_sequence.append(sub_label)
arrdata = np.asarray(sub_input_sequence) # [?, 33, 33, 1]
arrlabel = np.asarray(sub_label_sequence) # [?, 21, 21, 1]
make_data(arrdata, arrlabel) # 把处理好的数据进行存储,路径为checkpoint/..
else:
input_, label_ = preprocess(data[4], config['scale'])
if len(input_.shape) == 3:
h, w, _ = input_.shape
else:
h, w = input_.shape
input = input_.reshape([h, w, 1])
label = label_[6:h - 6, 6:w - 6]
label = label.reshape([h - 12, w - 12, 1])
sub_input_sequence.append(input)
sub_label_sequence.append(label)
input1 = np.asarray(sub_input_sequence)
label1 = np.asarray(sub_label_sequence)
return input1, label1, h, w
def imsave(image, path):
return scipy.misc.imsave(path, image)
#train
def reader_creator_image_and_label():
input_setup(FLAGS)
data_dir= os.path.join('./data/{}'.format(FLAGS['checkpoint_dir']), "train.h5")
images,labels=read_data(data_dir)
def reader():
for i in range(len(images)):
yield images, labels
return reader
def train(use_cuda, num_passes,BATCH_SIZE = 128, model_save_dir='../models'):
if FLAGS['is_train']:
images = fluid.layers.data(name='images', shape=[1, FLAGS['image_size'], FLAGS['image_size']], dtype='float32')
labels = fluid.layers.data(name='labels', shape=[1, FLAGS['label_size'], FLAGS['label_size']], dtype='float32')
else:
_,_,FLAGS['image_size'],FLAGS['label_size']=input_setup(FLAGS)
images = fluid.layers.data(name='images', shape=[1, FLAGS['image_size'], FLAGS['label_size']], dtype='float32')
labels = fluid.layers.data(name='labels', shape=[1, FLAGS['image_size']-12, FLAGS['label_size']-12], dtype='float32')
#feed_order=['images','labels']
# 获取神经网络的训练结果
predict = model(images)
# 获取损失函数
cost = fluid.layers.square_error_cost(input=predict, label=labels)
# 定义平均损失函数
avg_cost = fluid.layers.mean(cost)
# 定义优化方法
optimizer = fluid.optimizer.Momentum(learning_rate=1e-4,momentum=0.9)
opts =optimizer.minimize(avg_cost)
# 是否使用GPU
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 初始化执行器
exe=fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 获取训练数据
train_reader = paddle.batch(
reader_creator_image_and_label(), batch_size=BATCH_SIZE)
# 获取测试数据
# test_reader = paddle.batch(
# read_data(), batch_size=BATCH_SIZE)
#print(len(next(train_reader())))
feeder = fluid.DataFeeder(place=place, feed_list=[images, labels])
for pass_id in range(num_passes):
for batch_id, data in enumerate(train_reader()):
avg_cost_value = exe.run(fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost])
if batch_id%100 == 0:
print("loss="+avg_cost_value[0])
def model(images):
conv1=fluid.layers.conv2d(input=images, num_filters=64, filter_size=9, act='relu')
conv2=fluid.layers.conv2d(input=conv1, num_filters=32, filter_size=1,act='relu')
conv3=fluid.layers.conv2d(input=conv2, num_filters=1, filter_size=5)
return conv3
if __name__ == '__main__':
# 开始训练
train(use_cuda=False, num_passes=10)测试
全卷积网络
所用网络为全卷积网络,因此作为实际测试时,直接输入完整图像即可。
Padding
训练时得到的实际上是除去四周 (33-21)/2=6 像素外的图像,若直接采用训练时的设置(无 padding),得到的图像最后会减少四周各 6 像素(如插值放大后输入 512 × 512,输出 500 × 500)。
因此在测试时每一层卷积都进行了 padding(卷积核尺寸为 1 × 1的不需要进 行 padding),这样保证插值放大后输入与输出尺寸的一致性。
重建结果
客观评价指标 PSNR 与 SSIM:相比其他传统方法,SRCNN 取得更好的重建效果。

主观效果:相比其他传统方法,SRCNN 重建效果更具优势。

关于PaddlePaddle
PaddlePaddle 在我看来与 TensorFlow 有点类似,API 都非常好用,用户群体越来越大。不过有一点小建议,就是在我使用的时候,发现数据处理的方式比较麻烦(比较菜),比如 TensorFlow中有 TFRecords,同时有自带的数据集迭代器可以很方便的导入数据,所以希望出一个官方的数据转换格式,用来读取数据,并提供迭代器方法。

点击标题查看更多论文复现:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 收藏复现代码
