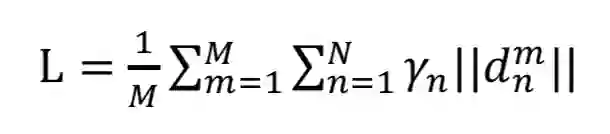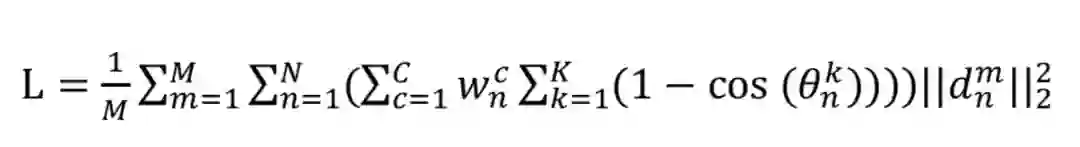![]()
前言:本文作者为深度学习领域资深专家言有三。作者近期发布新书《深度学习之人脸图像处理:核心技术与案例实践》,由浅入深、全面系统地介绍人脸图像的各个研究方向和应用场景,包括但不限于基于深度学习的各个方向的核心技术。本书理论体系完备,讲解时提供大量实例,可供读者实战演练。
今天,我们特邀作者送出5本新书作为极市粉丝福利,获取方式见文末。
本文内容节选自言有三新书《深度学习之人脸图像处理:核心技术与案例实践》,重点阐述
人脸关键点任务
,包括其关键点检测数据集的发展、核心算法以及未来展望。
1、什么是关键点检测?
人脸关键点检测是指给定人脸图像,定位出人脸面部的关键点,包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓区域的点,由于受到姿态和遮挡等因素的影响,人脸关键点检测是一个富有挑战性的任务。
人脸关键点是人脸各个部位的重要特征点,通常是轮廓点与角点,下图是使用OpenCV Dlib库对一张正脸图像的68个面部关键点检测结果。
其中点代表位置,数字代表序号。人脸关键点可以有以下主要应用:
(1) 人脸姿态对齐,人脸识别等算法都需要对人脸的姿态进行对齐从而提高模型的精度。
(2) 人脸美颜与编辑,基于关键点可以精确分析脸型、眼睛形状、鼻子形状等,从而对人脸的特定位置进行修饰加工,实现人脸的特效美颜,贴片等娱乐功能,也能辅助一些人脸编辑算法更好地发挥作用。
(3)人脸表情分析,基于关键点可以对人的面部表情进行分析,从而用于互动娱乐,行为预测等场景。
2、人脸关键点标注点数发展
关键点能够反映各个部位的脸部特征,随着技术的发展和对精度要求的增加,人脸关键点的数量经历了从最初的5个点到如今超过200个点的发展历程,在人脸等算法上拥有领先技术优势的商汤科技先后定出过106个关键点等行业标准。
人脸面部最关键的有5个点,分别为左右两个嘴角,两个眼的中心,鼻子,这5个关键点属于人脸内部关键点,根据它们就可以计算出人脸的姿态。当然早期也有标注4个点以及6个点的方案。
2005年发布的 FRGC-V2(Face Recognition Grand Challenge Version2.0)中标注了双眼、鼻子、嘴巴、下巴共5个关键点。
2007年发布的Caltech 10000 Web Faces数据集中标注了双眼、鼻子和嘴巴共4个关键点。
2013年的AFW数据集中标注了双眼、鼻子、嘴唇共6个关键点,其中嘴唇有3个点。
2014年发布的MTFL/MAFL数据集中标注了双眼、鼻子和2个嘴角共5个关键点。
2011年发布的AFLW(Annotated Facial Landmarks in the wild)数据集是一个人脸关键点检测领域里非常重要的评测基准,它包含多姿态、多视角,有25993幅从Flickr网站采集的人脸图像,其中每个人脸标定21个关键点。
眼睛和眉毛相关的总共有12个点:左眉毛左角(Left Brow Left Corner)、左眉毛中心(Left Brow Center)、左眉毛右角(Left Brow Right Corner)、右眉毛左角(Right Brow Left Corner)、右眉毛中心(Right Brow Center)、右眉毛右角(Right Brow Right Corner)、左眼睛左角(Left Eye Left Corner)、左眼睛中心(Left Eye Center)、左眼睛右角(Left Eye Right Corner)、右眼睛左角(Right Eye Left Corner)、右眼睛中心(Right Eye Center)、右眼睛右角(Right Eye Right Corner)。
嘴唇相关的有3个,左嘴角(Mouth Left Corner)、右嘴角(Mouth Center)、嘴角中心(Mouth Right Corner)。
鼻子相关的有3个,左鼻角(Nose Left)、鼻尖中心(Nose Center)、右鼻角(Nose Right)。
耳朵相关的有3个,左边耳垂下方(Left Ear)、右边耳垂下方(Right Ear)。
从这个标注我们可以看出,相对于5点,分别增强了眼睛、鼻子、嘴巴的标注,将原来的只标注人脸内部拓展到了边界,同时增加了对耳朵,下巴的定位。如果某些点看不见,则不进行标注。
还有一些与AFLW标注点数和规则类似的数据集,简介如下:
1998年发布的AR Face数据集包含了130个人,13种不同表情的3000幅图像,标注了22个关键点,不同之处在于对耳朵,眉毛等处的标注。
2011年发布的LFPW人脸数据库有1132幅训练人脸图像和300幅测试人脸图像,大部分为正面人脸图像,每个人脸标定29个关键点。
对于左右眼睛,LFPW各自标注了5个关键点,此时区分了眼睑的上下位置,眼睛的定位更加的准确,因此眼睛共5×2=10个点。
对于眉毛,各自标注了4个关键点,分别是左右上下,所以眉毛的定位相对于21个点其实也更加准确,眉毛共4×2=8个点。
对于鼻子,标注了4个关键点,分别为左右上下,考虑了鼻尖和鼻底。
对于嘴巴,标注了6个关键点,分别是左右嘴角,以及上嘴唇的上下位置,下嘴唇的上下位置。
同时也标注了下巴关键点,如果再加上左右耳朵的上下中总共6个位置,就发展成了35个关键点。
COFW人脸数据库包含LFPW人脸数据库训练集中的845幅人脸图像以及其他500幅
遮挡人脸图像,而测试集为507幅严重遮挡(同时包含姿态和表情的变化)的人脸图像,每个人脸标定29 个关键点。
68点标注是现今最通用的一种标注方案,早期在1999年的Xm2vtsdb数据集中就被提出,300W数据集和XM2VTS等数据集也都采用了68个关键点的方案,被OpenCV中的Dlib算法中所采用。
68个关键点的标注也有一些不同的版本,这里我们介绍最通用的Dlib中的版本,它将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。
Dlib所采用的68个人脸关键点标注可以看上图,单边眉毛有5个关键点,从左边界到右边界均匀采样,共5×2=10个。
眼睛分为6个关键点,分别是左右边界,上下眼睑均匀采样,共6×2=12个。
嘴唇分为20个关键点,除了嘴角的2个,分为上下嘴唇。上下嘴唇的外边界,各自均匀采样5个点,上下嘴唇的内边界,各自均匀采样3个点,共20个。
鼻子的标注增加了鼻梁部分4个关键点,而鼻尖部分则均匀采集5个,共9个关键点。
如果把额头部分也加上去,就可以得到更多,比如81个关键点。
公开的数据集比较少超过68个关键点,其中比较有名的是Wider Facial Landmark in the Wild(WFLW),它提供了98个关键点。
WFLW 包含了 10000 张脸,其中 7500 用于训练,2500 张用于测试。除了关键点之外,还有遮挡、姿态、妆容、光照、模糊和表情等信息的标注。
106个关键点标注是商汤科技提出的在业内被广泛采用的方案,包括Face++等企业开放的API多采用这个标注方式,具体信息如下:
鼻子15个关键点,与Dlib相比增加了两侧鼻梁部位。
眼睛20个关键点,每只眼睛轮廓点共8个,眼球中心点2个。
后续又在106个关键点的基础上提出了更加稠密的186个关键点,如今各个开发团队使用的点数可能会有差异,比如百度使用过72和150个点的方案。
除了以上这些常用的方案,还有很多的数据集也有自己的标注标准,比如BioID Face Dataset包含20个关键点,BUHMAP-DB包含52个关键点,MUCT包含76个关键点,PUT大部分图像包含30个关键点,其中正面人脸包括了194个点。
前面介绍的关键点标注都是针对二维人脸图像,超过200个点的标注已经是非常的密集,而对于3D人脸图像,相关的开源三维人脸数据集以及Face++,美图等企业都使用了超过1000个以上的稠密关键点,相关内容在三维人脸重建章节会详细讲述。
3、深度学习关键点检测方法
2013年,基于CNN模型的深度学习方法被研究者首次应用到人脸关键点检测任务,从此深度学习算法在关键点检测上的性能远超传统算法。目前基于深度学习的人脸关键点检测算法有几个重要的思路。
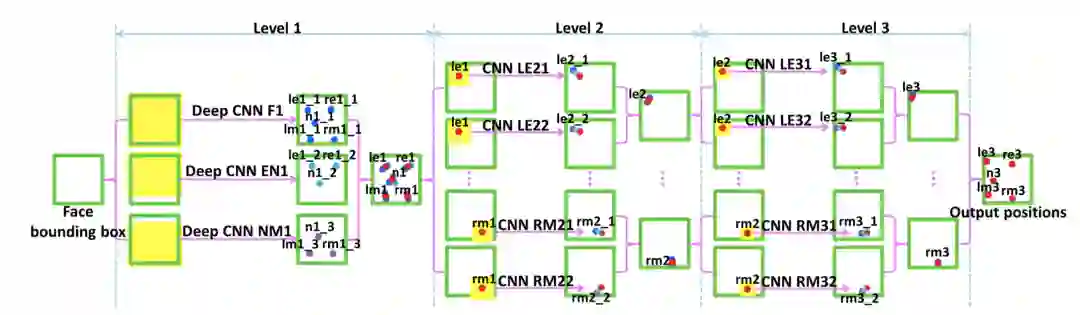
2013年,研究者首次将 CNN 应用到人脸关键点检测,提出了一种级联的框架。作者通过精心设计拥有三个层级的级联卷积神经网络,不仅改善了初始不当容易导致模型陷入局部最优的问题,而且借助于CNN强大的特征提取能力,获得了更为精准的关键点检测,框架流程如下图。
DCNN由三个Level构成。Level-1由3个CNN 组成,Level-2由10个CNN组成(每个关键点采用两个CNN),Level-3同样由10个CNN组成。
Level-1包括3个CNN,分别是F1(Face 1)、EN1(Eye,Nose)、NM1(Nose,Mouth)。F1输入尺寸为39×39,输出5个关键点的坐标;EN1输入尺寸为39×31,输出3个关键点的坐标;NM1输入尺寸为39×31,输出3个关键点。Level-1的输出是由三个CNN输出取平均得到,可以看出EN1和NM1的输入大小不同,一个是取了人脸偏上的位置,一个是取了人脸偏下的位置。
Level-2由10个CNN构成,输入尺寸均为15×15,每两个组成一对,一对CNN对一个关键点进行预测,预测结果同样是采取平均。
Level-3与Level-2一样,由10个CNN构成,输入尺寸均为15×15,每两个组成一对。Level-2和Level-3是对Level-1得到的粗定位进行微调,得到精细的关键点定位。
Level-1之所以比Level-2和Level-3的输入要大,是因为作者认为,由于人脸检测器的原因,边界框的相对位置可能会在大范围内变化,再加上面部姿态的变化,最终导致输入图像的多样性,因此在Level-1应该需要有足够大的输入尺寸。
Level-1与Level-2和Level-3还有一点不同之处在于,Level-1采用的是局部权值共享(Lcally Sharing Weights),全局权值共享是考虑到某一特征可能在图像中任何位置出现,然而对于类似人脸这样具有固定空间结构的图像而言,全局权值共享并不有效,作者采用局部权值共享的实验证明了它可以给网络带来性能提升。
DCNN采用级联回归的思想,从粗到精地逐步得到了精确的关键点位置,最终的检测结果是三个网络的融合,第一个网络检测绝对值,后面两个网络预测偏移量。
DCNN不仅设计了三级级联的卷积神经网络,还引入局部权值共享机制,从而提升了网络的定位性能,最终在数据集BioID和LFPW上均获得当时最优结果。2013年Face++在DCNN模型上进行改进,实现了68个人脸关键点的高精度定位。
人脸关键点检测任务常与其他的任务进行联合,比如MTCNN框架就可以同时进行人脸检测和关键点检测,不过这里我们介绍专门用于人脸关键点检测的框架。
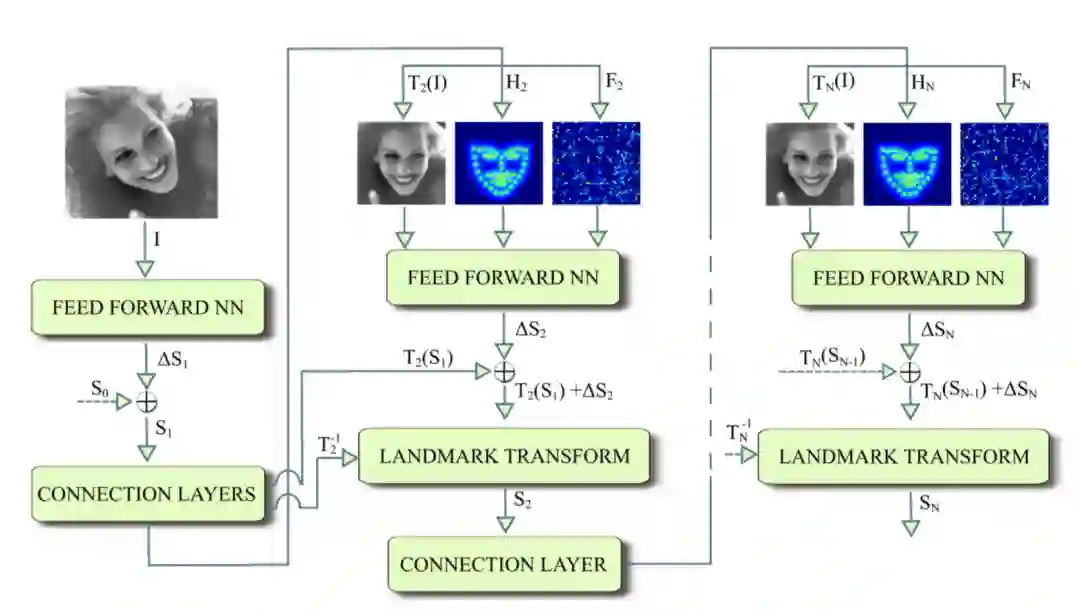
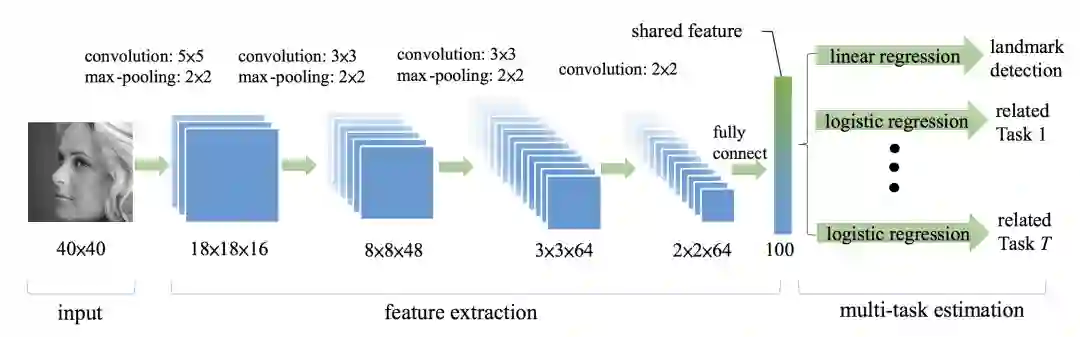
2014 年Zhang等人提出了TCDCN(Tasks-Constrained Deep Convolutional Network),作者认为在进行人脸关键点检测任务时,结合一些辅助信息可以帮助更好的定位关键点,这些信息包括性别,是否带眼镜,是否微笑和脸部的姿势,这些子任务结合起来构成了一个多任务学习框架,如下图所示。
网络输入为40×40的灰度图,经过CNN最终得到2×2×64的特征图,再通过一层含100 个神经元的全连接层提取特征。该特征为所有任务共享,对于关键点检测问题,采用线性回归模型,对于分类问题,则采用逻辑回归模型。
在多任务学习中,往往不同任务的学习难易程度不同,若采用相同的损失权重,会导致学习任务难以收敛。因此在该多任务学习框架中,作者提出了带权值的目标函数,由于关键点检测是主任务,相应的权重更大。
针对多任务学习的另外一个问题,即各任务收敛速度不同,该框架中提出了简单的经验准则。当某个子任务达到最好表现以后,就停止该任务的训练。
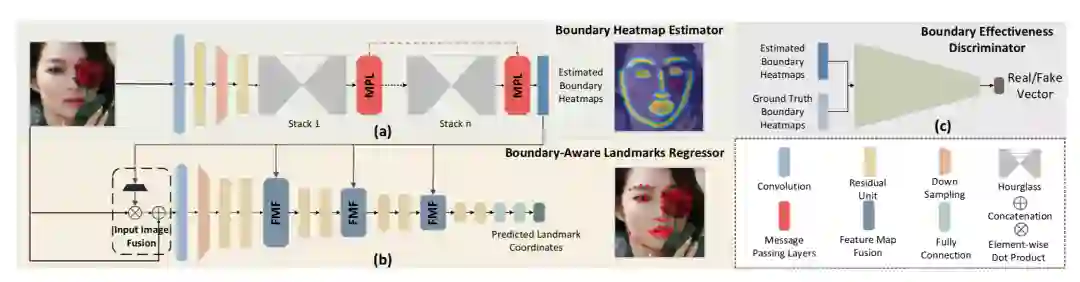
人脸的边缘信息和人脸关键点有很明显的关系,因此基于边缘感知的人脸关键点检测算法Boundary-Aware Face Alignment也被提出,它将13条人脸边缘线所描述的结构信息融入到关键点检测中,极大地提升了算法在大侧脸、夸张表情、遮挡、模糊等极端情况下的检测精度,其整个流程图如下。
Boundary-Aware Face Alignment的整体思想是使用hourglass网络初步估计经过人脸检测后的输入人脸边缘热图,然后使用一般级连回归模型进行关键点预测。
人脸轮廓线共包括13条:即外轮廓、左眉、右眉、鼻梁、鼻边界、左上眼皮、左下眼皮、右上眼皮、右下眼皮、上嘴唇上边、上嘴唇下边、下嘴唇上边、下嘴唇下边。基于轮廓线可以产生边缘热图,具体的方式就是首先对离散的关键点进行插值得到密集线条和对应的二进制边界特征图,然后计算周围像素到非零边界像素的高斯距离得到距离变换图,最后根据阈值得到边缘热图。
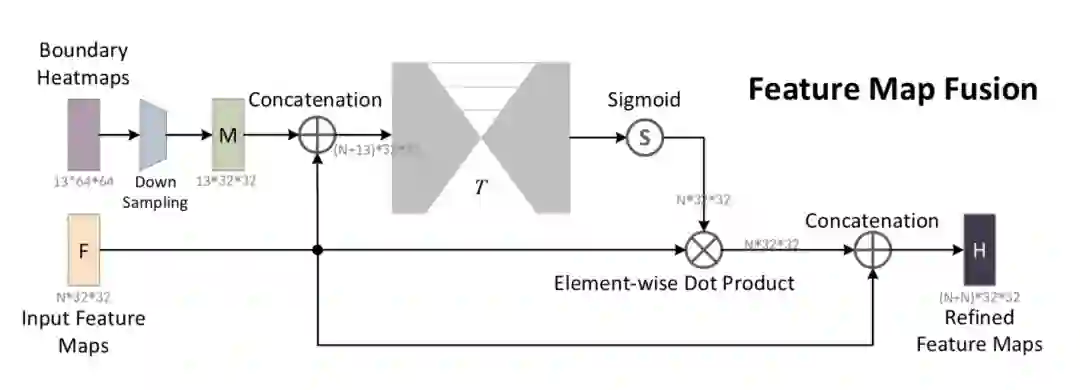
为了更好的利用边缘信息,在回归模型中分步多次将边缘热图添加到特征层进行特征融合,其融合模型(Feature Map Fusion)如下图:
可以看出首先将边界热图进行下采样,然后与特征图进行相加,经过一个hourglass子网络T将通道变换到特征图相同,然后经过Sigmoid函数归一化得到概率,对背景区域进行弱化。将概率图与输入特征逐个像素相乘后得到新的特征,最后与原输入特征进行通道拼接得到改进后的特征。
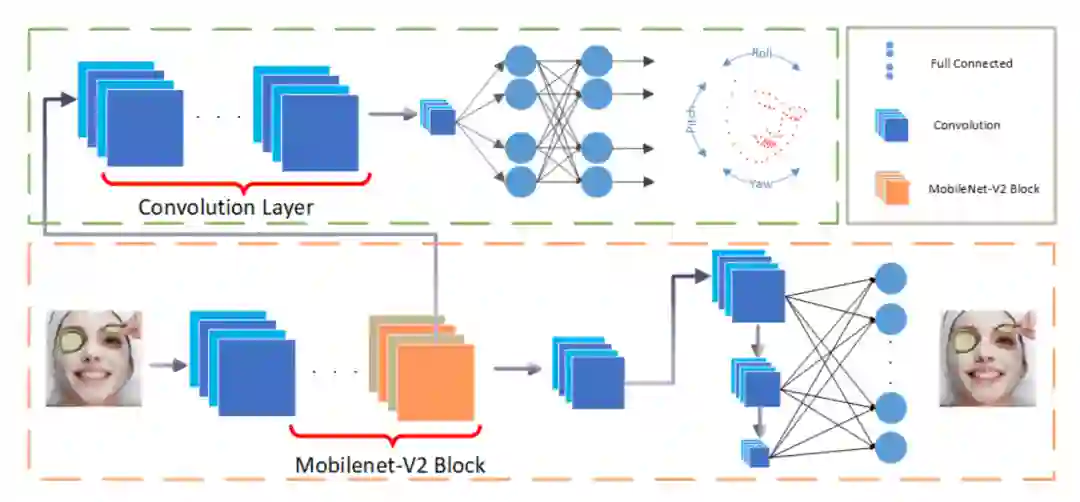
关键点检测任务和姿态估计问题是一脉相承的,因此姿态信息也常被用于辅助关键点检测。2019年腾讯AILab提出的PFLD框架使用了3维的位姿信息作为辅助,同时对样本不平衡进行了损失函数的优化,其框架示意图如下。
因为输入模型的人脸已经被中心化和归一化,所以只需要3个角度信息作为监督。关键点检测任务中一个典型能够处理不平衡样本的损失函数设计如下:
其中M表示人脸样本的数量,N表示每张人脸预设的需要检测的特征点数目,𝛾表示权重,d表示关键点的距离。
PFLD框架综合了几何约束和数据不平衡问题后提出了如下的损失函数:
这里的c表示不同类别的人脸: 包括正脸、侧脸、抬头、低头、表情以及遮挡等类,采用分类的倒数𝑤cn作为权重。𝜃表示yaw、pitch、roll 三种角度之间的偏差,角度越大其 cos值越小,权重则越大,说明要给大姿态的人脸更多的权重。
4、小结
深度学习技术的出现使得人脸关键点算法性能不断提升,但是还存在一些难点,其中最经典的就是人脸姿态和遮挡。虽然近年来出现了一些处理该问题的方法,但目前在实际应用中,尤其在实时低图像质量条件下,当姿态发生剧烈改变,以及遮挡比例较大时,现有方法的精度距离实际应用还有较大差距,需要进一步研究和提升。
另外,光照、表情、妆造也会对人脸关键点定位精度造成一定的影响,当前除了丰富数据集中各类样本外,也有使用生成对抗网络模型来增强模型泛化能力的一些研究思路。
人脸关键点检测是很多人脸任务的基础,在工业应用中往往还需要进行跟踪以提升关键点的稳定性,目前对人脸关键点进行跟踪有两个主要的思路。第一个就是基于一些传统的跟踪算法,如卡尔曼滤波等进行平滑跟踪,第二个就是基于深度学习模型直接预测视频人脸关键点,相关的技术就留待读者去自行拓展学习。
本次我们给大家介绍了
基于3DMM模型的三维人脸重建相关核心技术
,人脸图像属于最早被研究的一类图像,也是计算机视觉领域中应用最广泛的一类图像,其中需要使用到几乎所有计算机视觉领域的算法,可以说掌握好人脸领域的各种算法,基本就玩转了计算机视觉领域。
本书由浅入深、全面系统地介绍人脸图像的各个研究方向和应用场景,包括但不限于基于深度学习的各个方向的核心技术。本书理论体系完备,讲解时提供大量实例,可供读者实战演练。本书涵盖的内容非常广泛,从基本的人脸数据集发展历史和人脸检测开始,分别讲述在此基础上进行的人脸图像处理的相关技术与应用,涉及身份识别、安全认证、人机交互和娱乐社交等领域。本书共11章,涵盖的主要内容有人脸图像与特征基础、深度学习基础、人脸数据集、人脸检测、人脸关键点检测、人脸识别、人脸属性识别、人脸属性分割、人脸美颜与美妆、人脸三维重建及人脸属性编辑。本书适合计算机视觉领域的初学者及所有在人脸图像算法领域想要有所提高的工程技术人员、学生和教职工阅读。读者既可以将本书作为核心算法书籍学习理论知识,也可以将本书作为工程参考手册查阅相关技术。
领取方式
点击右下角“在看”,并关注极市平台公众号,回复“赠书”,即可获取抽奖二维码。8月12日上午10点,极市将准时开奖。没有被抽到的开发者可以通过扫描下方二维码进行购买。
![]()
![]()
添加极市小助手微信(ID : cv-mart),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR等技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
觉得有用麻烦给个在看啦~
![]()