干货!一文读懂行人检测算法

1引言
行人检测可定义为判断输入图片或视频帧是否包含行人,如果有将其检测出来,并输出bounding box 级别的结果。由于行人兼具刚性和柔性物体的特性 ,外观易受穿着、尺度、遮挡、姿态和视角等影响,使得行人检测成为计算机视觉领域中一个既具有研究价值同时又极具挑战性的热门课题。
行人检测系统的研究起始于二十世纪九十年代中期,是目标检测的一种。从最开始到2002 年,研究者们借鉴、引入了一些图像处理、模式识别领域的成熟方法,侧重研究了行人的可用特征、简单分类算法。自2005 年以来,行人检测技术的训练库趋于大规模化、检测精度趋于实用化、检测速度趋于实时化。随着高校、研究所以及汽车厂商的研究持续深入,行人检测技术得到了飞速的发展。本文主要介绍行人检测的特征提取、分类器的发展历程以及行人检测的现状。
2特征提取
2.12001~2005 特征提取
在早期的 PDS 中,在早期的 PDS 中 ,大多数工作仅使用一种外观 特征或者一种运动特征,外观特征主要有原始灰度 和轮廓 ,也有少量工作使用了颜色. 由于每种特征的针对性不同 ,只使用一种特征的PDS 都难以获得较好的检测性能。
随着时间的发展,出现了俩种不同的研究趋势,一种是对人的外观特征和运动特性更具针对性。
(a)新的外观特征:
( Ⅰ) Amnon 等提出了基于人体的 9 个关键部位及其相对位置关系构成的 13 个关键特征 ;
(Ⅱ) Havasi 提出了基于人腿的三次对称性特征
(b) 新的运动特征: Ran 等提出了人腿形态周期性特征。
(c)新的抽象特征:Lowe 提出来SIFT 特(一种计算机视觉的算法,用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量),它具有尺度不变的良好特征;Amnon 也将在这一特征引入到起 PDS 用于形状特征的表示。
另一种是使用多种特征综合的表示方法.Viola在2003年提出综合使用外观和运动特征的特征联合表示方法,使用结合串联的组合分类机制。
此外,在一些工作中,也开始实行在全局特征中加入局部特征作为补充,此种方法可以提高检测率,降低误差率,部分解决障碍物的遮挡问题。
2.2 2005~2011 特征提取
2.2.1行人特征
随着行人特征提取类型 逐渐发展,提取类型不仅仅只是外观和运动特征,慢慢增加,可分为三类:底层特征,基于学习的特征,以及混合特征。
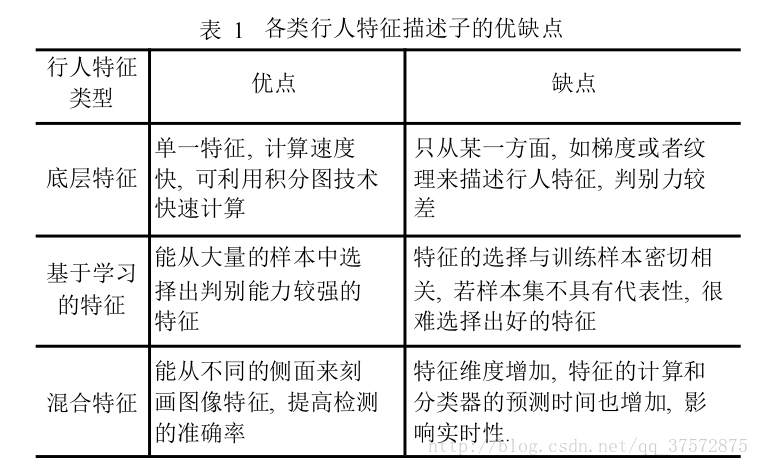
2.2.2底层特征 基于学习的特征 混合特征
注:0 底层特征 1 基于学习的特征 2 混合特征
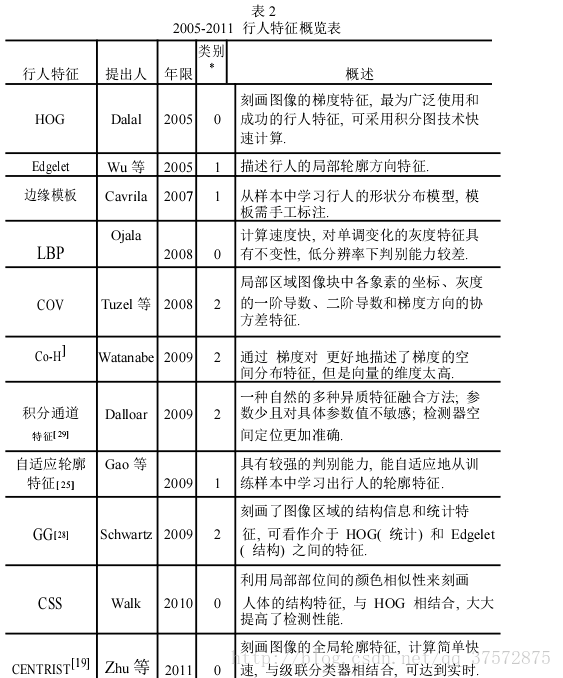
3行人检测的进程
3.1行人检测方法
(1)以Gavrila 为代表的全局模板方法:基于轮廓的分层匹配算法,构造了将近 2500 个轮廓模板对行人进行匹配, 从而识别出行人。为了解决模板数量众多而引起的速度下降问题,采用了由粗到细的分层搜索策略以加快搜索速度。另外,匹配的时候通过计算模板与待检测窗口的距离变换来度量两者之间的相似性。
(2)以Broggi 为代表的局部模板方法:利用不同大小的二值图像模板来对人头和肩部进行建模,通过将输入图像的边缘图像与该二值模板进行比较从而识别行人,该方法被用到意大利 Parma 大学开发的ARGO 智能车中。
(3)以Lipton 为代表的光流检测方法:计算运动区域内的残余光流;
(4)以Heisele 为代表的运动检测方法:提取行人腿部运动特征;
(5)以Wohler 为代表的神经网络方法:构建一个自适应时间延迟神经网络来判断是否是人体的运动图片序列;
以上方法,存在速度慢、检测率低、误报率高的特点。
3.2分类器
分类器的构造和实施大体会经过以下几个步骤:
选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分。
在训练样本上执行分类器算法,生成分类模型。
在测试样本上执行分类模型,生成预测结果。
根据预测结果,计算必要的评估指标,评估分类模型的性能。
4行人检测的现状
4.1 基于背景建模
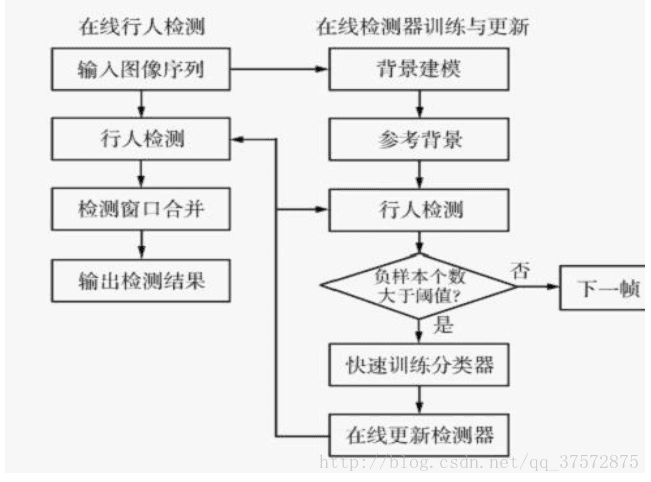
背景建模方法,提取出前景运动的目标,在目标区域内进行特征提取,然后利用分类器进行分类,判断是否包含行人; 背景建模目前主要存在的问题:必须适应环境的变化(比如光照的变化造成图像色度的变化),机抖动引起画面的抖动(比如手持相机拍照时候的移动),图像中密集出现的物体(比如树叶或树干等密集出现的物体,要正确的检测出来),必须能够正确的检测出背景物体的改变(比如新停下的车必须及时的归为背景物体,而有静止开始移动的物体也需要及时的检测出来),以及物体检测中往往会出现Ghost 区域。
4.2 基于统计学习的方法
这也是目前行人检测最常用的方法,根据大量的样本构建行人检测分类器。提取的特征主要有目标的灰度、边缘、纹理、颜色、梯度直方图等信息。分类器主要包括神经网络、SVM、adaboost 以及现在被计算机视觉视为宠儿的深度学习。
统计学习目前存在的难点:
(a)行人的姿态、服饰各不相同、复杂的背景、不同的行人尺度以及不同的关照环境。
(b)提取的特征在特征空间中的分布不够紧凑;
(c)分类器的性能受训练样本的影响较大;
(d)离线训练时的负样本无法涵盖所有真实应用场景的情况;目前的行人检测基本上都是基于法国研究人员 Dalal 在 2005 的
CVPR 发表的HOG+SVM 的行人检测算法。HOG+SVM 作为经典算法也别集成到OpenCV 里面去了,可以直接调用实现行人检测为了解决速度问题可以采用背景差分法的统计学习行人检测,前提是背景建模的方法足够有效(即效果好速度快),目前获得比较好的检测效果的方法通常采用多特征融合的方法以及级联分类器。(常用的特征有Harry-like、Hog 特征、LBP 特征、Edgelet 特征、CSS 特征、COV 特征、积分通道特征以及CENTRIST 特征。
图:基于场景模拟与统计学习的行人检测框架
5关于Faster R-CNN 的行人检测
5.1 Faster R-CNN 的缺点及处理方法
Faster R-CNN 在目标检测上准确,但在行人检测上效果一般, Faster R-CNN 用于行人检测效果不好的原因有两个:
(1)行人在图像中的尺寸较小,对于小物体, 提出的特征没有什么区分能力。
针对该情况,可以浅层池化,通过hole algorithm(“ a trous”or filter rarefaction )来增加特征图的尺寸。
(2)行人检测中的误检主要是背景的干扰,广义物体检测主要受多种类影响,存在大量困难负样本。 可以使用 cascaded Boosted Forest 来提取困难负样本,然后对样本进行赋予权重。直接训练 RPN 提出的深度卷积特征。
5.2 方法
通过RPN 生成卷积特征图和候选框,Faster R-CNN 的RPN 主要是用于在多类目标检测场景中解决多类推荐问题,因此可以简化 RPN 来进行单一问题检测。 通过Boosted Forest 作为分类器来提取卷积特征,从RPN 提取的区域,我们使用RoI 池化提取固定长度的特征。在此时要注意的是,不同于以前方法中会 fine-tune 膨胀之后的卷积核,只是来提取特征而不进行fine-tune(在这里有可能fine-tune之后RPN的整体效果下降了,但是可能提取高分辨特征的能力提升了),接下来实现细节。
6总结
本文通过从特征提取和分类器等来简单介绍行人检测的发展进程,同时也大致介绍了行人检测的现状以及较为详细的叙述了关于Faster R-cnn 的行人检测一些问题的处理方法和
原文链接:https://blog.csdn.net/qq_37572875/article/details/77915348?locationNum=11&fps=1
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习