人脸专集4 | 遮挡、光照等因素的人脸关键点检测

人脸关键点检测今天正式告一段落,接下来我们会应关注同学的要求,分享一期人脸图像质量评估,有兴趣的可以一起来!
注:如果您有啥需求,可以通过平台给我们留言,我们一定会满足大家需求,一起学习,共同进步!


显着的头部姿态(例如轮廓面)是人脸关键点检测算法失败的主要原因之一(下图),还是有一些困难。
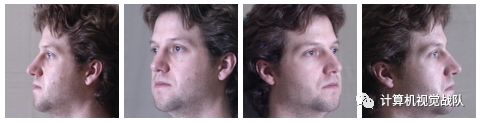
首先,三维刚性头部运动会影响二维人脸的外观和形状。不同的头部姿势会造成显着的面部外观和形状变化。传统的形状模型,如AAM和ASM中使用的基于PCA的形状模型,由于其本质上是线性的,而大部分的人脸姿态变化是非线性的,因此不能再对人脸形状变化进行建模。
第二,大部分的头部姿势可能导致自我遮挡,由于人脸关键点的缺失,一些人脸关键点检测算法可能无法直接应用。
第三,头部姿势训练数据有限,可能需要额外的努力来标注头部姿态标签来训练。
?怎么解决?
为了处理大头部姿态,一个方向是训练姿态依赖模型,这些方法在检测过程中有所不同。
Dantone, M., Gall, J., Fanelli, G., Gool, L.V.: Realtime facial feature detection using conditional regression forests. In: IEEE Conference on Computer Vision and Pattern Recognition (2012)
Zhu, X., Ramanan, D.: Face detection, pose estimation, and landmark localization in the wild. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2879–2886 (2012)
他们要么选择最好的模型,要么从所有模型中合并结果。选择模型有两种方法。第一种方法是利用现有的头部姿态估计方法对头部姿态进行估计。例如,在早期的工作中,在训练中建立了多姿态相关的AAM模型,并在测试过程中从多视角人脸检测器中选择该模型。
Yu, X., Huang, J., Zhang, S., Yan, W., Metaxas, D.: Pose free facial landmark fitting via optimized part mixtures and cascaded deformable shape model. In: IEEE International Conference on Computer Vision (2013)
首先根据几个面部关键点的检测来估计头部姿态。然后,应用头部姿态相关拟合算法,利用所选择的姿态模型进一步细化关键点检测结果。根据不同姿态相关模型的置信度,可以选择头部姿态。例如,在早期的工作中,三个AAM模型是建立在训练期间不同的头部姿势(如左轮廓,正面和右轮廓)。在检测过程中,将拟合误差最小的结果作为最终输出。其中,为每个离散的头部姿态建立了多个模型,并输出测试过程中的最佳匹配值作为最终结果。
如果模型没有正确选择,那么选择最佳头部姿态相关模型的算法就会失败。因此,可以更好地将不同姿态依赖模型的结果合并起来。最近,有一些算法可以建立一个统一的模型来处理所有的头部姿势。
总之,处理头部姿态的方法包括姿态相关模型、统一姿态模型和姿态不变特征。他们都有自己的长处和弱点。这取决于应用程序选择后续的应用程序。另外,对于某些应用程序,最好将不同类型的方法组合在一起。
人脸遮挡是人脸关键点检测算法失败的另一个原因。面部遮挡可能是由物体引起的,也可能是由于头部姿势过大而造成的。下图显示了具有对象遮挡的面部图像。

图中的一些图像就包含了面部遮挡。有一些困难以处理面部遮挡的。
首先,算法应该更多地依赖于没有遮挡的面部部位,而不是有遮挡的部分。然而,很难预测哪个面部部位或哪个面部关键点被遮挡。第二,由于任意面部部分可能被任意形状和形状的物体所遮挡,面部关键点检测算法应具有足够的灵活性来处理不同的情况(例如,口罩遮住嘴巴,或者手遮住了鼻子等)。第三,遮挡区域通常是局部一致的(例如,其他每个点都不可能被遮挡),但是很难将这一特性作为遮挡预测和里程碑检测的约束。
?怎么解决?
由于这些困难,可以处理遮挡的工作有限。现有的算法大多通过假设人脸的某些部分被遮挡而建立遮挡相关模型,并将这些模型合并起来进行检测。例如,人脸被分成九个部分,并且假定只有一个部分不被遮挡。因此,利用来自某一特定部分的面部外观信息来预测面部关键点位置和所有面部遮挡的部位。根据预测的面部遮挡概率,将所有九个部分的预测合并在一起。
上述的遮挡相关模型可能是次优的,因为它们假设少数预定义的区域被遮挡,而面部遮挡可能是任意的。因此,这些算法可能不适用于现实场景中的所有丰富和复杂的遮挡情况。
具体的操作,我们会在“计算机视觉协会”知识星球详细为大家讲解!
Facial expression
面部表情会导致非刚性的面部运动,影响面部关键点的检测和跟踪。

例如,上图所示,六种基本的面部表情,包括高兴、惊讶、悲伤、愤怒、恐惧和厌恶,都会导致面部外观和形状的变化。在更自然的情况下,除了六种基本表情外,面部图像还会经历更多自发的面部表情。一般来说,现有的人脸关键点检测算法能够在一定程度上处理人脸表情。

尽管大多数算法都是隐式地处理面部表情,但也有一些算法被明确地设计来处理重要的面部表情变化。例如,(Tong, Y., Wang, Y., Zhu, Z., Ji, Q.: Robust facial feature
tracking under varying face pose and facial expression. Pattern Recogn 40(11), 3195–3208 (2007))中,提出了一种分层动态概率模型,该模型能在不同表情引起的面部成分的特定状态之间自动切换。由于人脸表情和面部形状之间的相关性,一些算法还进行了人脸表情的联合检测和人脸关键点检测。
Li, Y., Wang, S., Zhao, Y., Ji, Q.: Simultaneous facial feature tracking and facial expression recognition. IEEE Transactions on Image Processing 22(7), 2559–2573 (2013)
上文提出了一种动态贝叶斯网络模型,用于建模面部动作单元、面部表情和面部形状之间的依赖关系,用于联合面部行为分析和面部关键点跟踪。研究表明,利用联合关系和相互作用可以提高人脸表情识别和人脸关键点检测的性能。
总 结
S u m m a r y
最近“计算机视觉战队”平台推送的连续三期人脸检测,关键点检测三种主要类别的算法:整体方法、约束局部方法和基于再回归的方法。此外,我们特别讨论了在不同的变化下尝试处理面部关键点检测的几种最新算法由头部姿势、面部表情、面部遮挡、强光照、低分辨率等引起。
此外,我们还讨论了一些关于面部的问题具有里程碑意义的检测。第一,当前的面部关键点检测和跟踪算法仍然存在问题,尤其在具有挑战性的条件下的面部图像,包括极端的头部姿势、面部遮挡,强烈的光照等。
现有算法的焦点解决一个或几个条件。仍然缺乏一种面部关键点检测与跟踪算法可以处理所有这些情况。
有几个未来的研究方向。
首先,由于在三种主要的方法中存在相似性以及关于方法的独特性质,具有混合所有三种方法的混合方法将是有益的。例如,要了解外观和形状模型怎样用在整体方法和CLM中,是否可以帮助基于回归的方法。
其次,动态信息是用在有限的意义上。面部运动信息应当与面部外观相结合,用于面部关键点跟踪。例如,很有趣的是,看看动态特征是否将有助于面部关键点追踪。具有面部结构信息的关键点跟踪也是一个有趣的方向。
第三,由于面部关键点检测和其它之间存在关系,面部表情分析任务,包括头部姿势估计和面部表情识别,它们的交互应该被用于关节分析。通过利用它们的依赖关系,可以融入计算机视觉投影模型并提高性能。
最后,在不同的条件下充分挖掘深度学习的力量,需要学习大量的带注释的数据库。这种大图像的注释需要有混合注释方法,包括人类注释、在线人群来源补充和自动注释算法。

如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!




