一个模型搞定图像标注、读图问答两件事,VQA准确率逼近人类水平 | Demo可玩
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
现在,丢给AI一张图,它不仅能看图说话,还能应对人们提出的刁钻问题了。
比如,给它看一张经典卷福照。
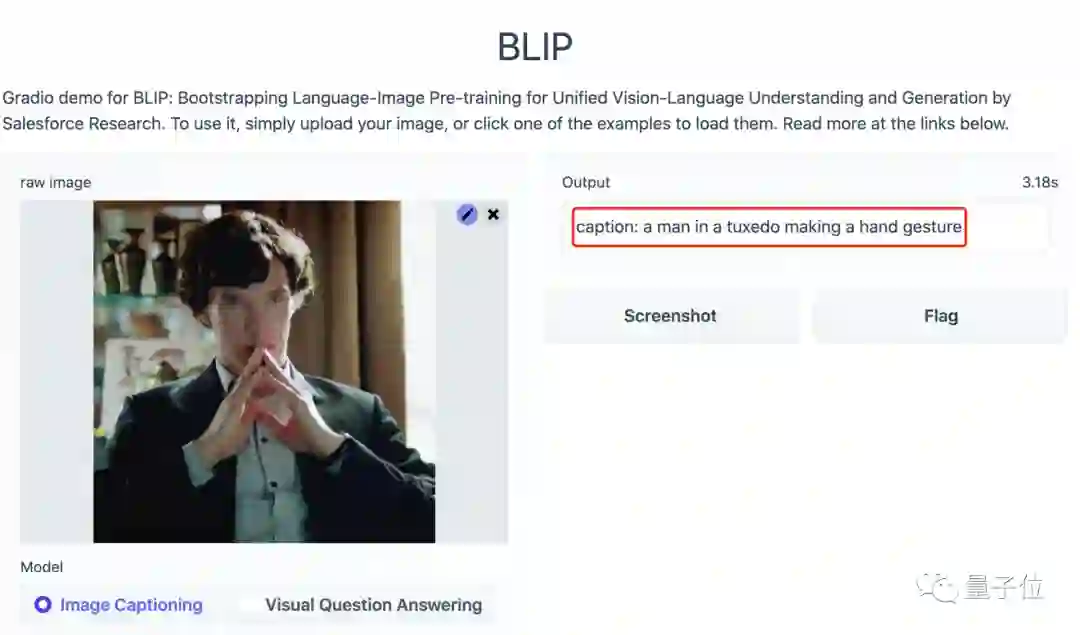
它便能回答出:
一个穿着西服、正在比划手势的男人。
那么图中男人的眼睛是什么颜色的呢?
蓝色。
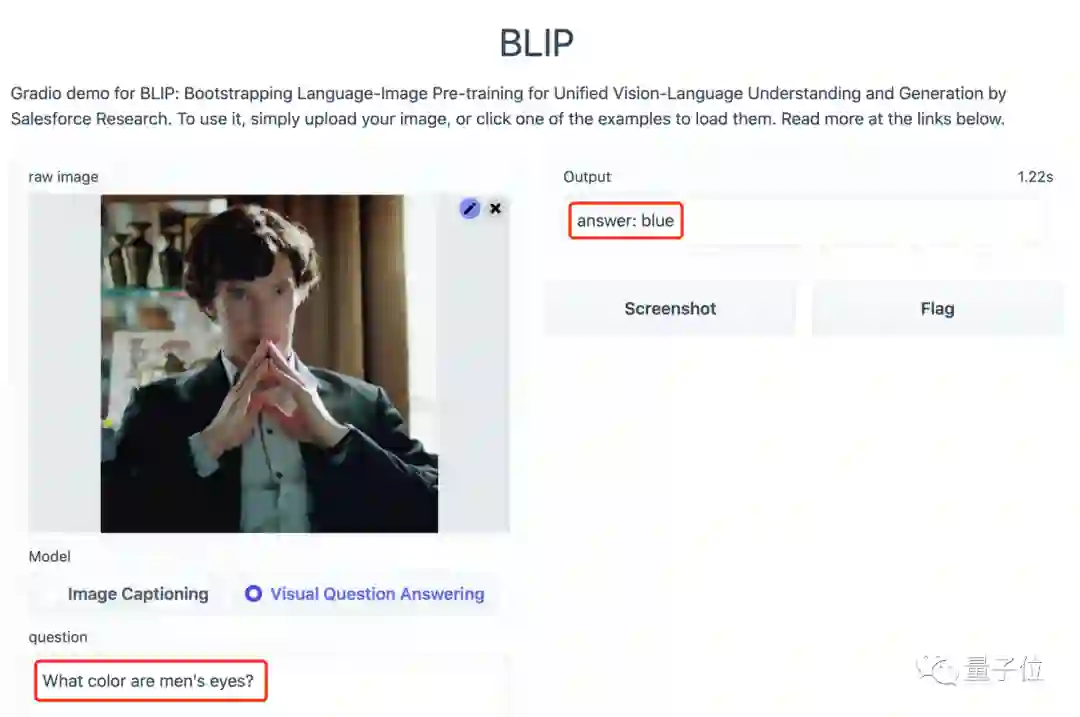
我定睛一看,还真是如此!
这就是视觉-语言领域的新成果:BLIP (Bootstrapping Language-Image Pre-training)。
它突破性地将过去往往只能单独执行的视觉-文本生成、视觉-文本理解两种任务整合在了一起,让AI可以在看图说话和视觉问答两种模式来回切换。
并且在各种任务上的表现也都优于过去SOTA方法,VQA准确率超过78%,逼近人类基准线(80.83%)。
话不多说,就让我们来试玩一下,看看这个模型究竟有多厉害。
Demo试玩
BLIP可以提供两种功能。
第一是描述图片的内容,第二是回答有关图片的提问。
上传好图片后,便可从图片下方的模式中任选一种进行试玩。
首先我们来看看它看图说话的水平如何。
上传了一张有小孩、猫、狗多种元素的图片后,模型输出的内容为:
一个小男孩和一只猫、一只狗一起趴在地上。
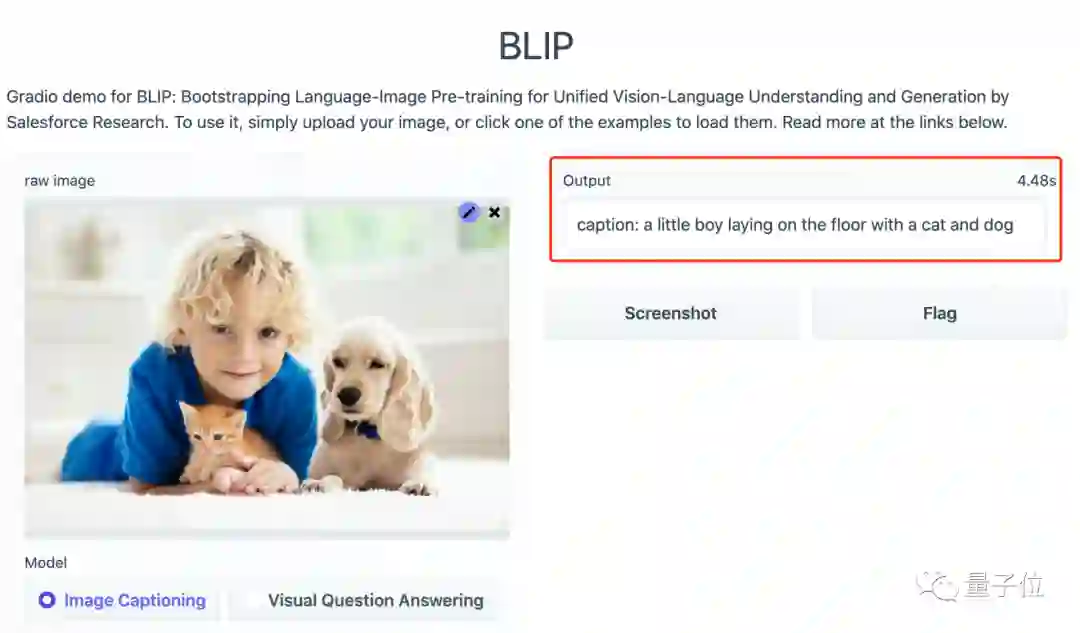
再提问试试看:
图中有鱼吗?
BLIP:NO.
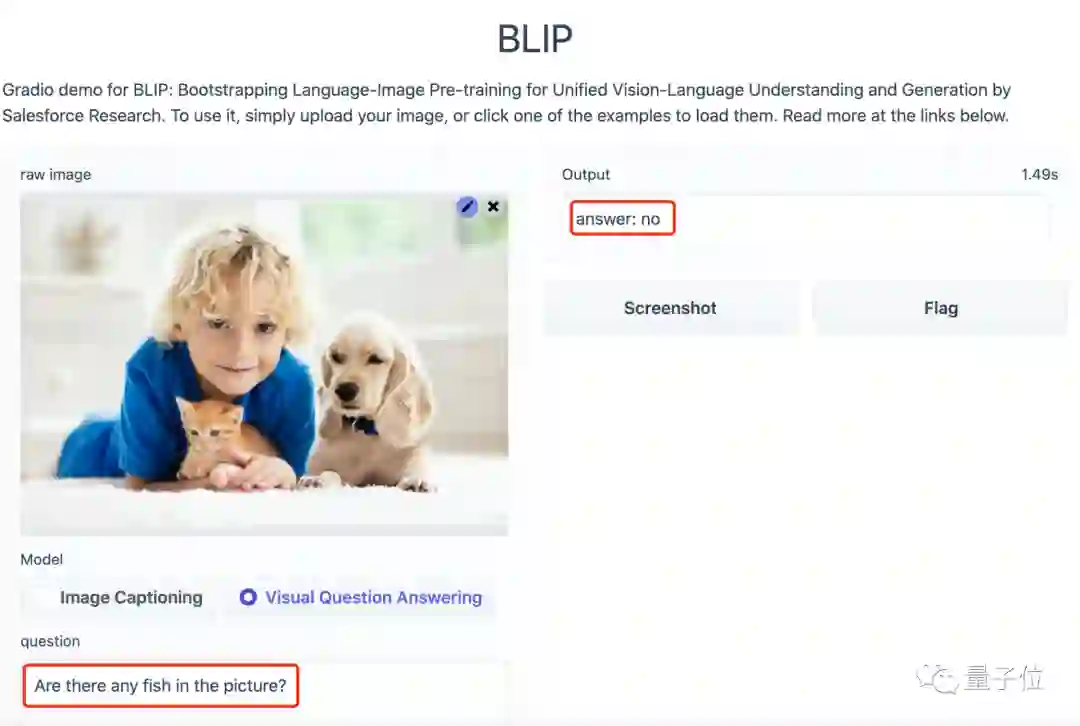
可以看到,BLIP对图片的理解很到位,那么再多换几张图片呢?
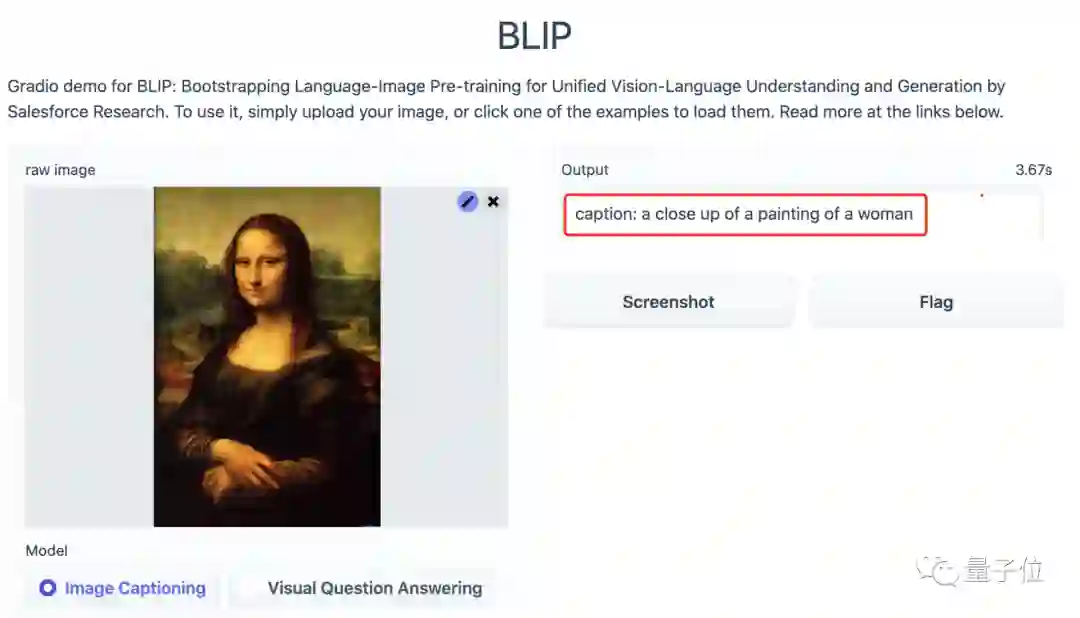
当我们上传蒙娜丽莎的画像后,模型很轻松地辨别出来了这是一张女人的画像,并非是一张照片。
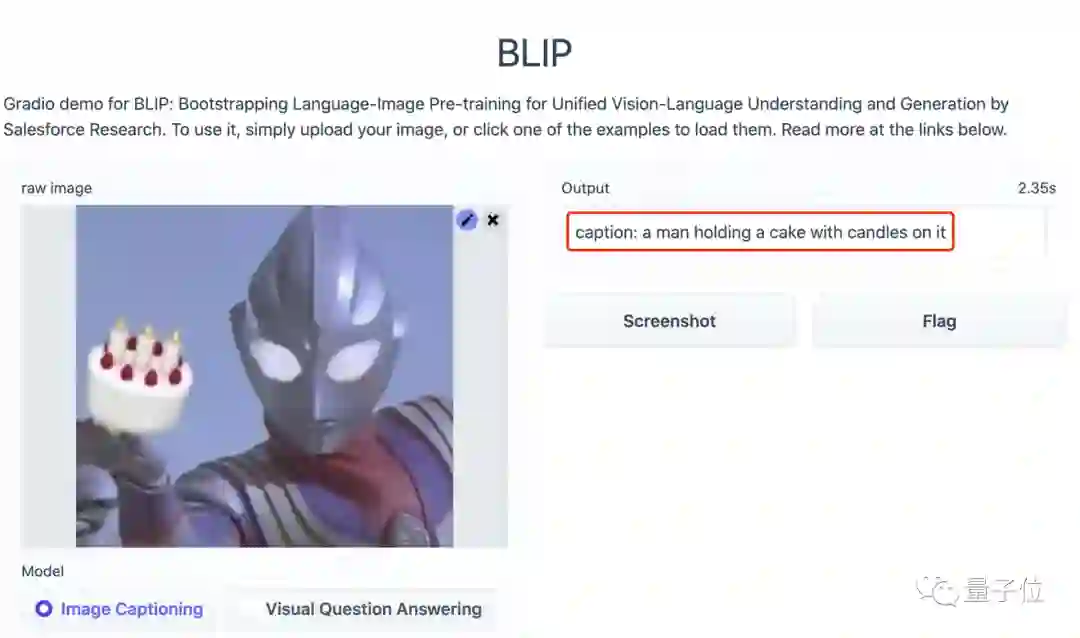
即便是上传一张恶搞的奥特曼图片,也没有难倒BLIP,并且还给出了一个一本正经的回答:
一个男人端着一个插有蜡烛的蛋糕。
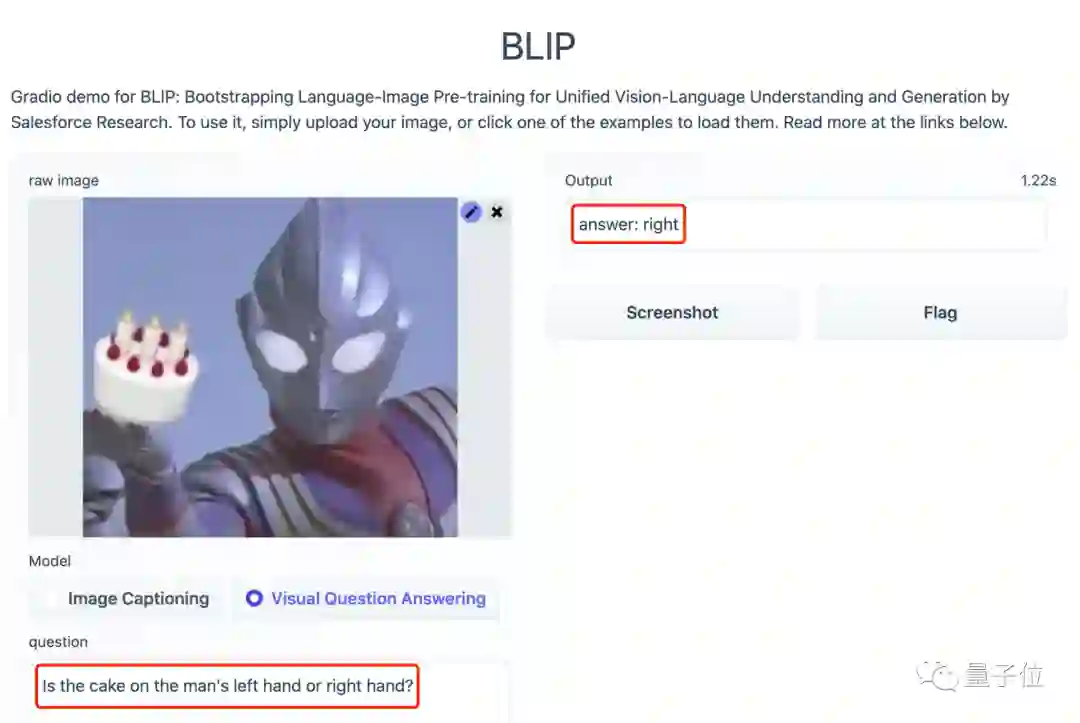
甚至问它:蛋糕是在男人的左手上还是右手上?BLIP都能给出正确的答案:
右手。
这波操作属实是6到我了。
那么它背后的原理是什么呢?我们一起来看。
学习带噪图像-文本对
BLIP这次主要做的工作有两方面。
第一,它使用了一个多任务模型(MED),将多种任务预训练整合在了一起。
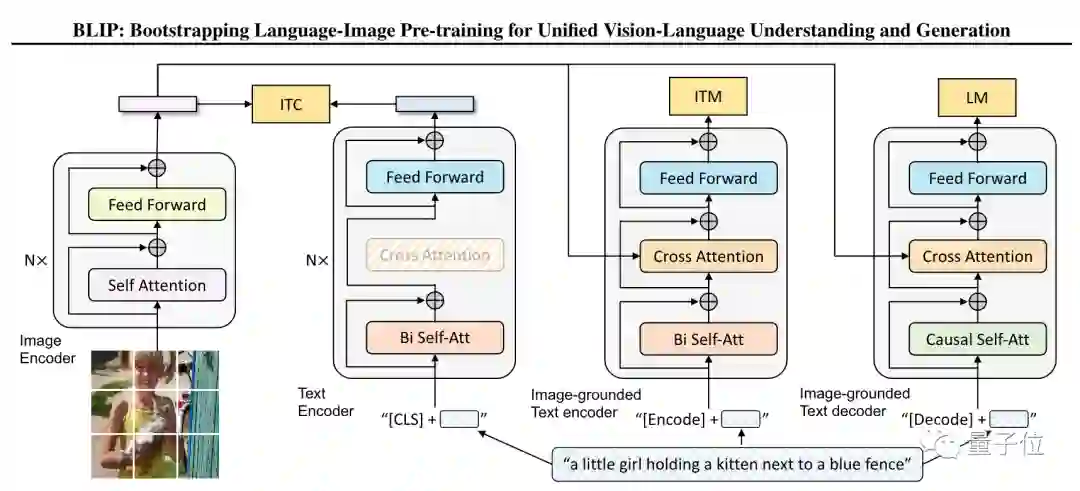
从框架图中看到,MED主要包括3个部分:
单峰编码器,可以用图像-文本对比损失(ITC)训练,让视觉和文本表征对齐。
基于图像的文本编码器,可以用传统的交叉注意层来模拟视觉-语言信息的转换,并通过图像-文本匹配损失(ITM)来进行训练,从而来区分正、负图像-文本对。
基于图像的文本解码器,可以将双向自注意力层转换为因果自注意力层,并且与编码器共享同一个交叉注意力层和前馈网络。解码器通过语言建模训练(LM)来输出文字标注。
由此,该模型可以执行图像-文本对比、图像-文本匹配和图像语言生成任务。
第二方面,研究人员提出了一种新型的数据自举法(CapFilt)。它可以让模型从带有噪声的图像-文本对中学习。
CapFilt中主要包含标注器 (captioner)和过滤器 (filter)两个部分。
其中,标注器用来生成描述图像的文本,过滤器将带有噪音的结果排除掉。
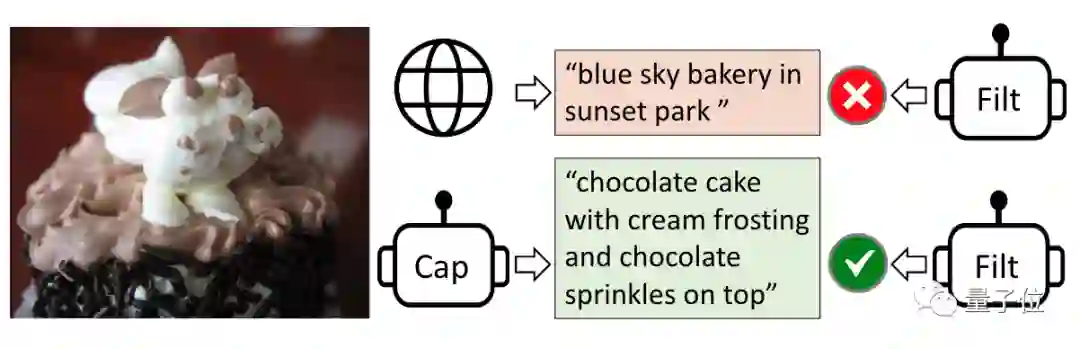
比如下面的几个例子,就是过滤器将错误的答案驳回。

研究表明,标注器列出的文本越多样化,最后的效果越好。
与此前取得SOTA的方法相比,BLIP在图像-文本检索任务上recall@1平均提升了2.7%;在看图生成文字上,CIDEr提升2.8%,视觉问答方面分数提升了1.6%。
通讯作者为清华校友
此项研究的通讯作者为许主洪 (Steven C.H. Hoi)。

他目前也任职于Salesforce亚洲研究院。此前为新加坡国立大学信息系统学院教授。
2002年,许主洪在清华大学计算机系获得学士学位。于2004年、2006年先后在香港大学计算机科学与工程系获得硕士、博士学位。
2019年当选IEEE Fellow。主要研究领域有计算机视觉、NLP、深度学习等。
第一作者为Junnan Li。

他目前是Salesforce亚洲研究院高级研究科学家。
本科毕业于香港大学,博士毕业于新加坡国立大学。
研究领域很广泛,包括自我监督学习、半监督学习、弱监督学习、迁移学习、视觉-语言。
其余两位作者也均为华人,分别是Dongxu Li和Caiming Xiong。
论文地址:
https://arxiv.org/abs/2201.12086
试玩地址:
https://huggingface.co/spaces/akhaliq/BLIP
GitHub地址:
https://github.com/salesforce/BLIP
— 完 —
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


