学界 | 从文本挖掘综述分类、聚类和信息提取等算法
选自arXiv
机器之心编译
参与:机器之心编辑部
文本挖掘一直是十分重要的信息处理领域,因为不论是推荐系统、搜索系统还是其它广泛性应用,我们都需要借助文本挖掘的力量。本文先简述文本挖掘包括 NLP、信息检索和自动文本摘要等几种主要的方法,再从文本表征、分类方法、聚类方法、信息提取方法等几大部分概述各类机器学习算法的应用。机器之心对本论文进行简要的概述,更详细的内容请查看原论文。
论文地址:https://arxiv.org/abs/1707.02919

摘要:每天所产生的信息量正在迅猛增加,而这些信息基本都是非结构化的海量文本,它们无法轻易由计算机处理与感知。因此,我们需要一些高效的技术和算法来发现有用的模式。文本挖掘近年来颇受大众关注,是一项从文本文件中提取有效信息的任务。本文将对一些最基本的文本挖掘任务与技术(包括文本预处理、分类以及聚类)做出阐述,此外还会简要介绍其在生物制药以及医疗领域的应用。
1 简介
由于以各种形式(如社交网络、病历、医疗保障数据、新闻出版等)出现的文本数据数量惊人,文本挖掘(TM)近年来颇受关注。IDC 在一份报告中预测道:截至到 2020 年,数据量将会增长至 400 亿 TB(4*(10^22) 字节),即从 2010 年初开始增长了 50 倍 [50]。
文本数据是典型的非结构化信息,它是在大多数情况下可产生的最简单的数据形式之一。人类可以轻松处理与感知非结构化文本,但机器显然很难理解。不用说,这些文本定然是信息和知识的一个宝贵来源。因此,设计出能有效处理各类应用中非结构化文本的方法就显得便迫在眉睫。
1.1 知识发现 vs 数据挖掘(略)
1.2 文本挖掘方法
信息检索(Information Retrieval,IR):信息检索是从满足信息需求的非结构化数据集合中查找信息资源(通常指文档)的行为。
自然语言处理(Natural Language Processing,NLP):自然语言处理是计算机科学、人工智能和语言学的子领域,旨在通过运用计算机理解自然语言。
文本信息提取(Information Extraction from text,IE):信息提取是从非结构化或半结构化文档中自动提取信息或事实的任务。
文本摘要:许多文本挖掘应用程序需要总结文本文档,以便对大型文档或某一主题的文档集合做出简要概述。
无监督学习方法(文本):无监督学习方法是尝试从未标注文本中获取隐藏数据结构的技术,例如使用聚类方法将相似文本分为同一类。
监督学习方法(文本):监督学习方法从标注训练数据中学习分类器或推断功能,以对未知数据执行预测的机器学习技术。
文本挖掘的概率方法:有许多种概率技术,包括无监督主题模型(如概率潜在语义分析模型(pLSA)[64] 与文档主题生成模型(LDA)[16])和监督学习方法(如可在文本挖掘语境中使用的条件随机场)[83]。
文本流与社交媒体挖掘:网络上存在许多不同的应用程序,它们可以生成大量的文本数据流。
观点挖掘与情感分析:随着电子商务和网络购物的问世,产生了大量的文本,并在不同的产品评论或用户意见上不断增长。
生物医学文本挖掘:生物医学文本挖掘是指对生物医学科学领域的文本进行文本挖掘的任务。
2 文本表征和编码
2.1 文本预处理
标记化(Tokenization):标记化是将字符序列分解成标记(token/单词或短语)的任务,同时它可能会去掉某些字符(如标点符号)。
过滤:过滤通常在文档上完成,用于删除某些单词。一种常见过滤是停用词删除。
词形还原:词形还原是有关单词形态分析的任务,即对单词的各种变形形式进行分组,以便将它们作为单个项目进行分析。
词干提取:词干提取方法旨在获取派生词的词干(词根)。词干提取算法比较依赖于语言。
2.2 向量空间模型(略)
3 分类
3.1 朴素贝叶斯分类器
朴素贝叶斯分类器可能会是最简单,用途也最广泛的分类器。在假设不同项相互独立且服从相同分布的情况下,它通过概率模型对文档的类别分布进行建模。朴素贝叶斯发对条件概率分布作了条件独立性假设,由于这是一个较强的假设,朴素贝叶斯法由此得名。虽然在很多实际应用中,这种所谓的「朴素贝叶斯」的假设明显有错误,但它的表现仍旧令人惊讶。
用于朴素贝叶斯分类 [94] 的通常有两个主要模型,它们都以根据文档中的单词分布进而得出每一类的后验概率为目标。
多变量伯努利模型:该模型中,每篇文档会由一个二进制特征向量来表征文档中某单词是否存在,因而忽略了单词出现的频率。原论文可在 [86] 中找到。
多项式模型:通过将文档表示为词袋(Bag Of Words),因此它能够捕捉文档中单词(项)出现的频率。在 [74,95,99,104] 中则介绍了多项式模型的许多不同变体。McCallum 等人在伯努利和多项式模型之间进行了广泛对比,并得出结论:若词汇的数量很少,伯努利模型可能会优于多项式模型;若词汇数量很多,多项式模型则总会优于伯努利模型;而当词汇数量对两种模型而言都处于最优状态时,多项式模型总会更胜一筹。
最近邻分类器
最近邻分类器是一种基于临近数据的分类器,并且基于距离度量来执行分类。其主要思想为,属于同一类的文档更可能「相似」或者基于相似度计算彼此更为接近,如在(2.2)中定义的余弦相似度。测试文档的分类根据训练集中相似文档的类别标签推断而出。如果我们考虑训练集中 K 个最邻近的值为一个标签,那么该方法被称为 k 近邻分类并且这 k 个邻近值最常见的类就可以作为整个集群的类,请查看 [59, 91, 113, 122] 了解更多 K 近邻方法。
决策树分类器
基本上说,决策树是一种训练样本的层次树,其中样本的特征值可用于分离数据的层次,特征分离的顺序一般是通过信息熵和信息增益来确定。换句话说,基于定义在每个节点或者分支的分割标准,决策树能递归地将训练数据集划分为更小的子树。
树的每个节点都是对训练样本一些特征的判定,且从该节点往下的每个分支或子分支对应于这个特征值。从根节点开始对实例进行分类,首先需要确定信息增益最大的特征并排序,然后通过该节点判定样本是否具有某种特定的特征,并将样本分到其以下的分支中,直到完成最后一次分类到达叶节点。这个过程被递归性地重复 [99]。查看 [19, 40, 69, 109] 获取决策树的详细信息。
决策树已经与提升算法结合使用,例如梯度提升树。[47,121] 讨论了提高决策树分类的准确性的增强技术。
3.4 支持向量机
支持向量机(SVM)是受监督的学习分类算法,它广泛应用于文本分类问题中。不带核函数的支持向量机是线性分类器的一种形式。在文本文档中,线性分类器是一种线性结合文档特征而做出分类决策的模型。因此,线性预测的输出可定义为 y = a · x + b,其中 x = (x1, x2, . . . , xn) 是归一化的文档词频向量,a = (a1, a2, . . . , an) 是系数向量,b 是标量。我们可以将类别分类标签中的预测器 y = a · x + b 可理解为不同类别中的分离超平面,不带核函数的硬间隔支持向量机只能分割线性可分数据。
支持向量机最初在 [34, 137] 被引入。支持向量机尝试在不同的类中找到一个「不错的」线性分离器 [34, 138]。一个单独的支持向量机只能分离两个类别,即正类和负类 [65]。支持向量机试图找到离正样本和负样本间有最大距离 ξ(也被称为最大间隔)的超平面。而确定超平面与样本见距离 ξ 的文档被称为支持向量,支持向量实际上指定了超平面的实际位置。如果两类文档不是线性可分的,那么一定有样本是超平面分类错误的。这种线性不可分的数据是无法使用线性支持向量机的,而支持向量机的强大之处在于它的核函数,软间隔支持向量机应用核函数就能够成为十分强大的非线性分类器,并且拥有极其强大的鲁棒性。
4 聚类
文本聚类算法被分为很多不同的种类,比如凝聚聚类算法(agglomerative clustering algorithm)、分割算法(partitioning algorithm)和概率聚类算法。
4.1 层次聚类算法
层次聚类算法构建了一组可被描述为层级集群的类。层级可以自上而下(被称为分裂)或者自下而上(被称为凝聚)的方式构建。层次聚类算法是一种基于距离的聚类算法,即使用相似函数计算文本文档之间的紧密度。关于层次聚类算法文本数据的完整描述在 [101, 102, 140] 可以找到。
4.2 K 均值聚类
K 均值聚类是一种在数据挖掘中被广泛使用的分割算法。k 均值聚类根据文本数据的语境将 n 个文档划分为 k 组。属于某一类典型数据则围绕在所构建的群集群中心周围。k 均值聚类算法的基本形式如下:

4.3 概率聚类和主题模型
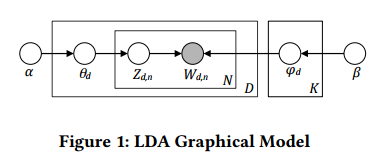
主题建模是最流行的一种概率聚类算法,近来受到广泛关注。主题建模 [16, 53, 64] 的主要思想是为文本文档的语料构建概率生成模型。在主题模型中,文档是主题的混合体,而主题则是单词的概率分布。
两种主要的主题模型分别为:概率潜在语义分析(Probabilistic Latent Semantic Analysis/pLSA)[64] 和隐狄利克雷分布(LDA))[16]。pLSA 模型在文档层面不提供任何概率模型,这使得很难泛化到新的没见过的文档。
隐狄利克雷分配模型是最新的无监督技术,用于提取所收集文档的专题信息(主题)[16, 54]。其基础思想为文档是潜在主题的随机混合,每个主题为单词的概率分布。
5 信息提取
信息提取(IE)是一种自动从非结构化或者半结构化文本中提取结构化信息的任务。换句话说,信息提取可被视做为一种完全自然语言理解的有限形式,其中我们会提前了解想要寻找的信息。
5.1 命名实体识别(NER)
命名的实体是一个单词序列,其可以识别一些现实实体,比如「谷歌公司(Google Inc)」、「美利坚合众国(United States)」、「巴拉克奥巴马(Barack Obama)」。命名实体识别的任务是在自定义文本中将找出命名实体的位置并将其区分为预先定义的类别(如人、组织、位置等)。NER 不能像字典一样简单地做一些字符串的匹配工作就行,因为 a) 字典通常是不全的且不会包含给定的实体类型的命名实体的所有形式。b) 命名实体经常取决于其语境,比如「大苹果(big apple)」可以是一种水果,也可以是纽约的绰号。
5.2 隐马尔可夫模型
隐马尔可夫模型假定产生标签(状态)或者观察的马尔可夫过程取决于一个或者多个之前的标签(状态)或者观察。因此对于一个观察序列 X = (x1, x2, . . . , xn),给定一个标签序列 Y = (y1,y2, . . . ,yn),我们有
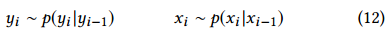
隐马尔可夫模型已经成功地被用于命名实体识别任务和语音识别系统中。隐马尔可夫的完整描述请查看 [110]。
5.3 条件随机场
条件随机场(CRFs)是序列标注的概率模型。CRF 由 Lafferty 等人首次引入。我们在如下的观察(未被标注的数据序列)和 Y(标签序列)中提到了与 [83] 中条件随机场的相同概念。
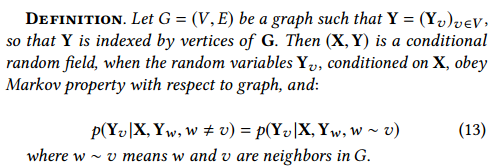
条件随机场被广泛用于信息提取和部分的语音标注任务中 [83]。
7 讨论
在本文中,我们不仅尝试对文本挖掘领域做一个简短的介绍,同时我们对一些在该领域广泛使用的基础算法和技术做了一个概述。虽然本文主要从发展和脉络上对文本挖掘领域进行大概的综述,并且也很难更细致地描述这些算法或方法,但本文提供了大量的相关论文资源,希望能对想深入了解这一领域的读者提供扩展。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



