通用近似定理很好地解释了为什么神经网络能工作以及为什么它们经常不起作用。
此前,图灵奖得主、深度学习先驱 Yann LeCun 的一条推文引来众多网友的讨论。
在该推文中,LeCun 表示:「深度学习并不像你想象的那么令人印象深刻,因为它仅仅是通过曲线拟合产生的插值结果。但在高维空间中,不存在插值这样的情况。在高维空间中,一切都是外推。」
![]()
而 LeCun 转发的内容来自哈佛认知科学家 Steven Pinker 的一条推文,Pinker 表示:「 通用近似定理很好地解释了为什么神经网络能工作以及为什么它们经常不起作用。只有理解了 Andre Ye 的通用近似定理,你才能理解神经网络。」
![]()
Pinker 所提到的 Andre Ye,正是接下来要介绍《You Don’t Understand Neural Networks Until You Understand the Universal Approximation Theorem》文章的作者。虽然该文章是去年的,但在理解神经网络方面起到非常重要的作用。
在人工神经网络的数学理论中, 通用近似定理(或称万能近似定理)指出人工神经网络近似任意函数的能力。通常此定理所指的神经网络为前馈神经网络,并且被近似的目标函数通常为输入输出都在欧几里得空间的连续函数。但亦有研究将此定理扩展至其他类型的神经网络,如卷积神经网络、放射状基底函数网络、或其他特殊神经网络。
此定理意味着神经网络可以用来近似任意的复杂函数,并且可以达到任意近似精准度。但它并没有告诉我们如何选择神经网络参数(权重、神经元数量、神经层层数等等)来达到我们想近似的目标函数。
1989 年,George Cybenko 最早提出并证明了单一隐藏层、任意宽度、并使用 S 函数作为激励函数的前馈神经网络的通用近似定理。两年后 1991 年,Kurt Hornik 研究发现,激活函数的选择不是关键,前馈神经网络的多层神经层及多神经元架构才是使神经网络有成为通用逼近器的关键。
最重要的是,该定理解释了为什么神经网络似乎表现得如此聪明。理解它是发展对神经网络深刻理解的关键一步。
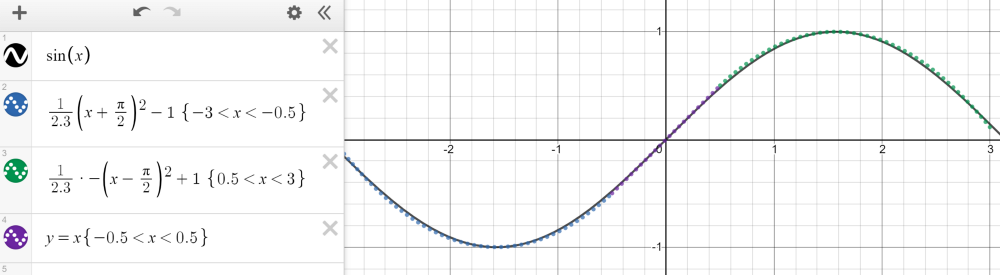
紧凑(有限、封闭)集合上的任何连续函数都可以用分段函数逼近。以 - 3 和 3 之间的正弦波为例,它可以用三个函数来近似——两个二次函数和一个线性函数,如下图所示。
![]()
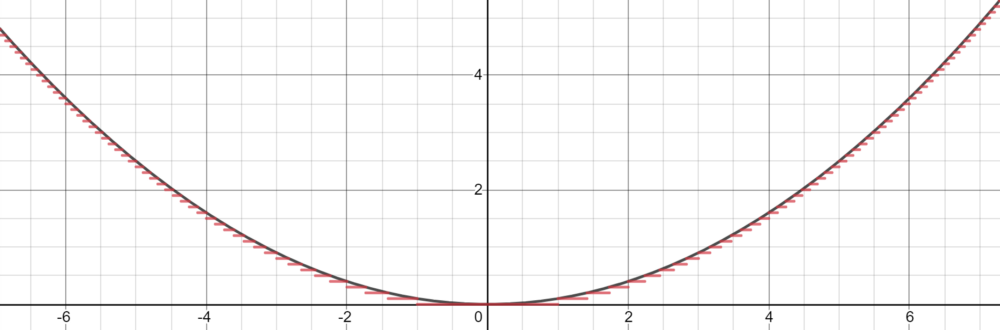
然而,Cybenko 对这个分段函数描述更为具体,因为它可以是恒定,本质上通过 step 来拟合函数。有了足够多的恒定域 (step),我们就可以在给定的范围内合理地估计函数。
![]()
基于这种近似,我们可以将神经元当做 step 来构建网络。利用权值和偏差作为「门」来确定哪个输入下降,哪个神经元应该被激活,一个有足够数量神经元的神经网络可以简单地将一个函数划分为几个恒定区域来估计。
对于落在神经元下降部分的输入信号,通过将权重放大到较大的值,最终的值将接近 1(当使用 sigmoid 函数计算时)。如果它不属于这个部分,将权重移向负无穷将产生接近于 0 的最终结果。使用 sigmoid 函数作为某种处理器来确定神经元的存在程度,只要有大量的神经元,任何函数都可以近乎完美地近似。在多维空间中,Cybenko 推广了这一思想,每个神经元在多维函数中控制空间的超立方体。
通用近似定理的关键在于,它不是在输入和输出之间建立复杂的数学关系,而是使用简单的线性操作将复杂的函数分割成许多小的、不那么复杂的部分,每个部分由一个神经元处理。
![]()
自 Cybenko 的初始证明以后,学界已经形成了许多新的改进,例如针对不同的激活函数(例如 ReLU),或者具有不同的架构(循环网络、卷积等)测试通用近似定理。
不管怎样,所有这些探索都围绕着一个想法——神经网络在神经元数量中找到优势。每个神经元监视特征空间的一个模式或区域,其大小由网络中神经元的数量决定。神经元越少,每个神经元需要监视的空间就越多,因此近似能力就会下降。但是,随着神经元增多,无论激活函数是什么,任何函数都可以用许多小片段拼接在一起。
有人可能指出,通用近似定理虽然简单,但有点过于简单(至少在概念上)。神经网络可以分辨数字、生成音乐等,并且通常表现得很智能,但实际上只是一个复杂的逼近器。
神经网络旨在对给定的数据点,能够建模出复杂的数学函数。神经网络是个很好的逼近器,但是,如果输入超出了训练范围,它们就失去了作用。这类似于有限泰勒级数近似,在一定范围内可以拟合正弦波,但超出范围就失效了。
![]()
外推,或者说在给定的训练范围之外做出合理预测的能力,这并不是神经网络设计的目的。从通用近似定理,我们了解到神经网络并不是真正的智能,而是隐藏在多维度伪装下的估计器,在二维或三维中看起来很普通。
当然,通用逼近定理假设可以继续向无穷大添加神经元,这在实践中是不可行的。此外,使用神经网络近乎无限的参数组合来寻找性能最佳的组合也是不切实际的。然而,该定理还假设只有一个隐藏层,并且随着添加更多隐藏层,复杂性和通用逼近的潜力呈指数增长。
取而代之的是,机器学习工程师依据直觉和经验决定了如何构造适合给定问题的神经网络架构,以便它能够很好地逼近多维空间,知道这样一个网络的存在,但也要权衡计算性能。
与吴恩达共话ML未来发展,2021亚马逊云科技中国峰会可「玩」可「学」
2021亚马逊云科技中国峰会「第二站」将于9月9日-9月14日全程在线上举办。对于AI开发者来说,9月14日举办的「人工智能和机器学习峰会」最值得关注。
当天上午,亚马逊云科技人工智能与机器学习副总裁Swami Sivasubramanian 博士与 AI 领域著名学者、Landing AI 创始人吴恩达(Andrew Ng )博士展开一场「炉边谈话」。
不仅如此,「人工智能和机器学习峰会」还设置了四大分论坛,分别为「机器学习科学」、「机器学习的影响」、「无需依赖专业知识的机器学习实践」和「机器学习如何落地」,从技术原理、实际场景中的应用落地以及对行业领域的影响等多个方面详细阐述了机器学习的发展。
点击阅读原文,立即报名。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com