![]()
本文为预训练语言模型专题系列第八篇
感谢清华大学自然语言处理实验室对
预训练语言模型架构的梳理,我们将沿此脉络前行,探索预训练语言模型的前沿技术,红框中为已介绍的文章,绿框中为本期介绍的文章,欢迎大家留言讨论交流。
Multi-Task Deep Neural Networks for Natural Language Understanding(2019)
本期介绍的是由微软提出的 Multi-Task Deep Neural Networks。众所周知,语言模型预训练方法和多任务学习策略都是提高模型性能的重要手段,本文就结合了两者的优点,提出了MT-DNN的方案,并在GLUE上的八个NLU任务上超越了之前的state-of-art模型。
首先,MT-DNN考虑了四种类型的NLU任务,分别是单句文本分类(CoLA, SST-2),文本对的分类(RTE,MNLI,QQP,MRPC),文本相似度度量(STS-B),相关度排序(QNLI)。括号中是在GLUE中四种类型对应的任务。这四种类型的任务在MT-DNN中对应着三种损失函数来优化,分别是分类,回归和排序 。
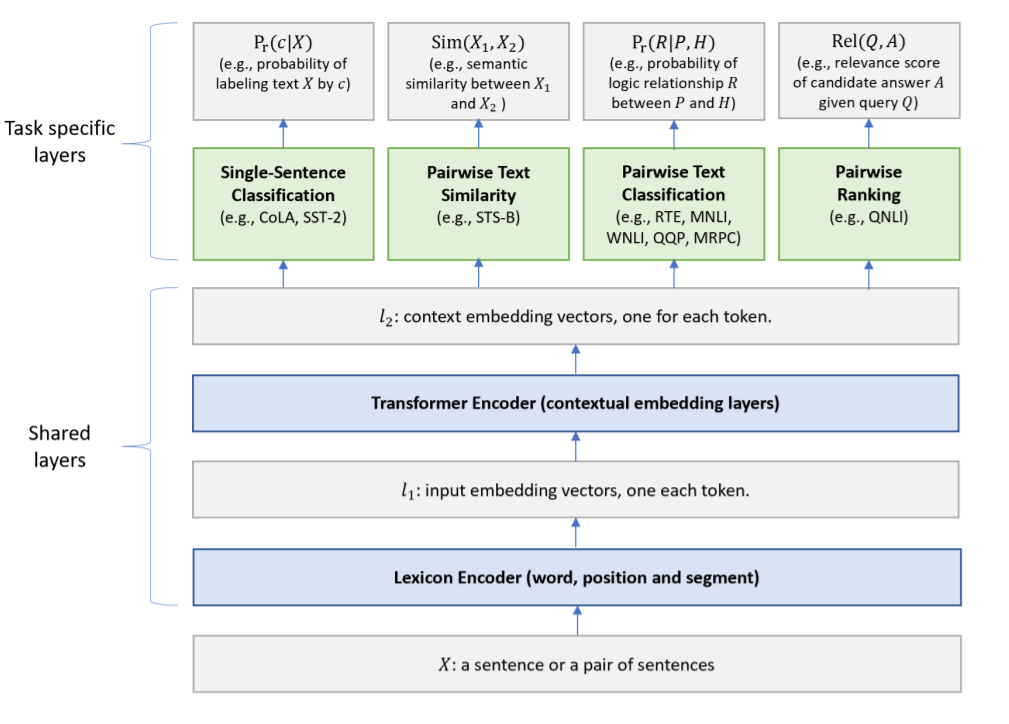
其次,MT-DNN的结构如下图,低层的结构是对所有任务通用的,高层结构则是对应特定的任务。底层的词经过embedding获得词级别的表示l1,再经过Transformers通过self-attention获得上下文语义的表示l2,两者都是会通过多任务来训练出的共同的语义表示。再往上就是对应特定任务的头,经过特定的任务损失函数来进行训练。
MT-DNN数据构造的方式和BERT差不多,开头[CLS],两句句子中用[SEP]隔开,结尾[SEP]。上面四种类型任务的数据构造都可以遵循这种方式。
MT-DNN的训练也分成两个阶段,预训练和多任务学习。预训练的任务与BERT一致,有MLM和NSP,这里不再赘述。整体的训练方式我们可以看下图的流程。首先,对包括Transformer encoder 在内的模型中的共享层进行预训练。接着,将数据混合起来,每次取一个小的batch,它会是属于某个任务T的。如果这个任务T是分类任务,则用分类任务的公式计算loss,如果是回归任务或排序任务,则用回归任务或排序任务的公式计算loss,接着利用loss更新梯度。
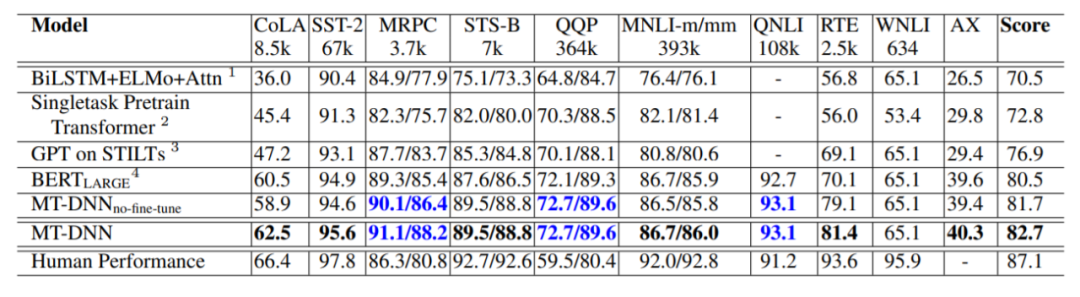
实现细节上,MT-DNN是基于BERT的pytorch实现,优化器使用Adamax,学习率5e-5,batch_size32,总共训练五轮。使用了linear decay,并且加上了0.1的warmup。使用了大约为0.1的dropout,并且将梯度剪切到1,接下来,我们看看模型的结果,排行榜信息截至2019年2月25日。
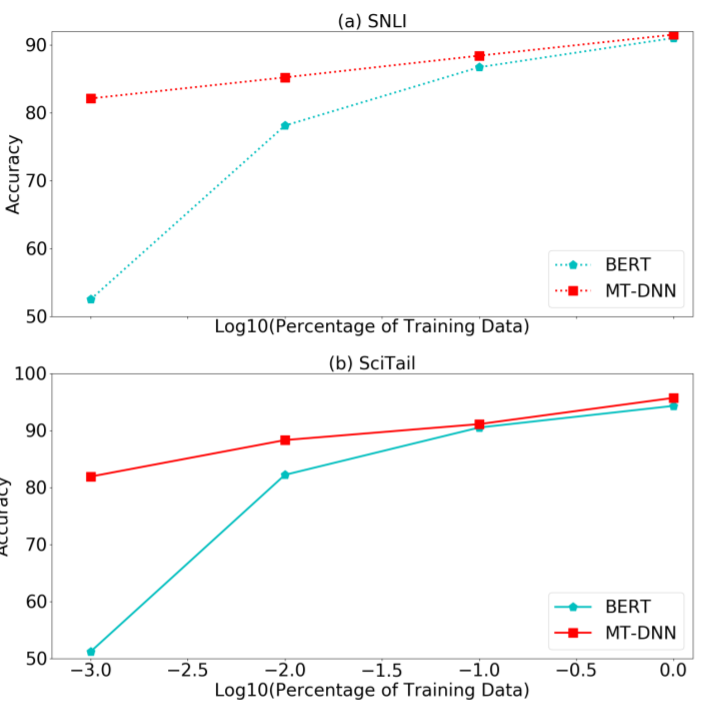
可以看到,MT-DNN效果是要强于BERT的,对特定任务进行finetune会效果更好。上面BERT模型的结果是经过finetune的。另外一点值得注意的是,因为MT-DNN多任务预训练的效果,所以它在迁移的场景中,特别是数据量小的情况下,表现更优于BERT,如下图。可以预想到的是,MT-DNN将会更容易适应新的环境和任务。
总结一下,MT-DNN基本上还是一个在BERT上的改进,改进的内容是使用了一种多任务的训练方式,使模型更加稳定,泛化性更好,且能在更少的数据或者新任务上获得良好的效果。其实我个人挺受这篇文章启发的,因为遵循MT-DNN的思路,其实我们可以让BERT的预训练变得更好,使用更多更优秀的任务去进行预训练,甚至结合有标注的数据,这样可以更大程度地利用数据,加强模型的效果。
Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding(2019)
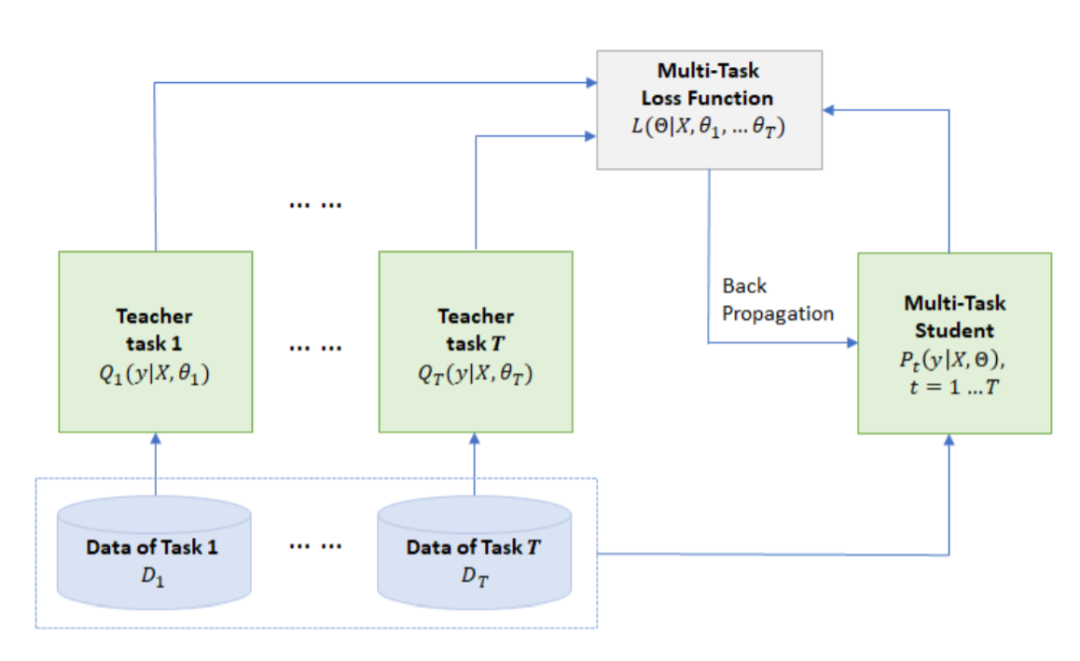
这篇文章是上一篇文章的延续,主要改进部分是加入了知识蒸馏, 被称为MT-DNN(KD),文章中提到,对每个任务,他们训练了多个模型集成而成的MT-DNN作为Teacher Model,它是会强过单个模型的。然后通过多任务学习,将这些Teacher Model的知识蒸馏到单个MT-DNN上,他们观察这样做以后,效果在GLUE的七个任务上大幅提高了。
模型的集成已经成为各大排行榜上提高模型成绩的通用做法了。但是集成的模型通常是由许多模型堆叠而成,对资源的要求较高,更别说目前很多模型本身就很大,给在线上的部署带来了很大的挑战。所以本文选择首先对每个集成模型,获得比较强的Teather model,然后通过知识蒸馏的方式,离线地对每个任务生成软标签,比如对分类任务来讲就是分类的概率。接着,结合硬标签和软标签,通过多任务学习,训练出一个MT-DNN(Student),通过这种方式,在不增加系统负担的情况下,把集成的能力带给了学生模型,提供了良好的泛化性和效果。
![]()
Hinton2015年的文章曾经说到,软标签中包含了Teacher model是如何泛化的信息,是Student model 获取其泛化能力的关键。在本篇文章中,每一个特定任务的Teacher,都是集成后的MT-DNN,它拥有很好的泛化能力,通过软标签和多任务学习,就能将这个能力传递给Student,让它表现更好。
实现细节上,对每个任务,首先在{0,1, 0.2, 0.3}中选择并改变dropout,训练了六个MT-DNN模型,挑选了在MNLI和RTE上效果最好的三个,接下来把他们在特定任务MNLI,QQP,RTE,QNLI上finetune,并生成软标签。对单个任务,软标签平均作为这个任务最终的软标签。而硬标签软标签的权重作者进行尝试过,并无明显区别。
![]()
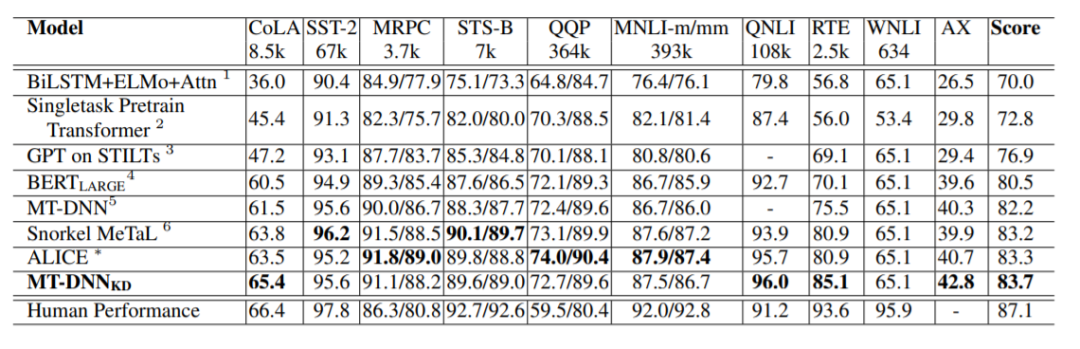
上图为模型效果在GLUE上的汇总,排行榜信息截至于2019年4月1日。首先,从最终Score来看,知识蒸馏的MT-DNN超越了其他的state-of-art,名列第一。其次,第三名的Snorkel MeTaL是一个emsemble的模型,第二名的ALICE当时还未发表,无法得知是否为emsemble。
从这个结果看,知识蒸馏给MT-DNN带来了很大的提高,甚至超过了很多集成模型。
![]()
上图可以看到,知识蒸馏的方法确实给模型带来了很大的收益,只略低集成模型一点点,而且又并没有增加模型的负担。这篇论文本质上是讲知识蒸馏在MT-DNN上的应用。硬标签软标签结合训练的方式,以及伪标签,在很多比赛中已经被大家广泛应用,取得了很不错的效果。总的来说,这两篇文章中所使用的技巧都是比较实用可靠的,如果还没有了解的小伙伴,推荐大家自己去试一试哦~
本期的论文就给大家分享到这里,感谢大家的阅读和支持,下期我们会给大家带来其他预训练语言模型的介绍,敬请大家期待!
推荐阅读
AINLP年度阅读收藏清单
当当的羊毛,快薅,这一次要拼手速!
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
自动作诗机&藏头诗生成器:五言、七言、绝句、律诗全了
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
这门斯坦福大学自然语言处理经典入门课,我放到B站了
可解释性论文阅读笔记1-Tree Regularization
征稿启示 | 稿费+GPU算力+星球嘉宾一个都不少
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()