ICLR 2022 | 超越Focal Loss!PolyLoss用1行代码+1个超参完成超车!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:集智书童

PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions
论文:https://openreview.net/forum?id=gSdSJoenupI
Cross-entropy loss和Focal loss是在训练深度神经网络进行分类问题时最常见的选择。然而,一般来说,一个好的损失函数可以采取更灵活的形式,并且应该为不同的任务和数据集量身定制。通过泰勒展开来逼近函数,作者提出了一个简单的框架,称为
PolyLoss,将损失函数看作和设计为多项式函数的线性组合。PolyLoss可以让Polynomial bases(多项式基)的重要性很容易地根据目标任务和数据集进行调整,同时也可以将上述Cross-entropy loss和Focal loss作为PolyLoss的特殊情况。大量的实验结果表明,在
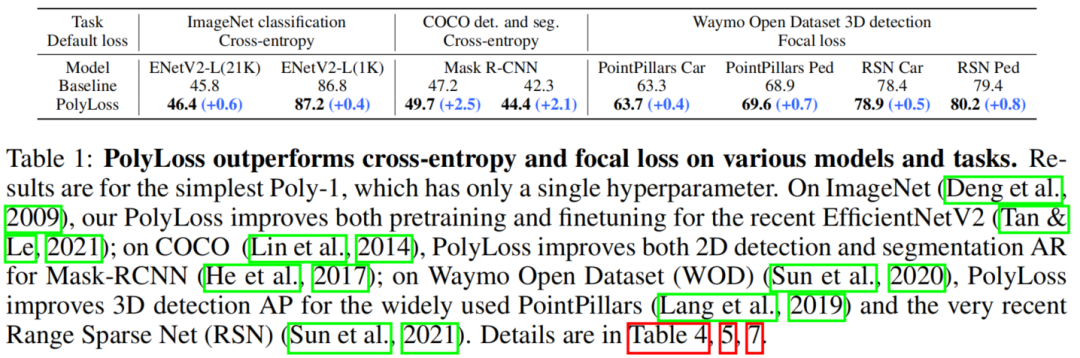
PolyLoss内的最优选择确实依赖于任务和数据集。只需引入一个额外的超参数和添加一行代码,PolyLoss在二维图像分类、实例分割、目标检测和三维目标检测任务上都明显优于Cross-entropy loss和Focal loss。
1简介
原则上,损失函数可以是将预测和标签映射到任何(可微)函数。但是,由于损失函数具有庞大的设计空间,导致设计一个良好的损失函数通常是具有挑战性的,而在不同的工作任务和数据集上设计一个通用的损失函数更是具挑战性。
例如,L1/L2 Loss通常用于回归的任务,但很少用于分类任务;对于不平衡的目标检测数据集,Focal loss通常用于缓解Cross-entropy loss的过拟合问题,但它并不能始终应用到其他任务。近年来,许多研究也通过元学习、集成或合成不同的损失来探索新的损失函数。
在本文中,作者提出了PolyLoss:一个新的框架来理解和设计损失函数。
作者认为可以将常用的分类损失函数,如Cross-entropy loss和Focal loss,分解为一系列加权多项式基。
它们可以被分解为
的形式,其中
为多项式系数,
为目标类标签的预测概率。每个多项式基
由相应的多项式系数
进行加权,这使PolyLoss能够很容易地调整不同的多项式基。
-
当 时, PolyLoss等价于常用的Cross-entropy loss,但这个系数分配可能不是最优的。
研究表明,为了获得更好的结果,在不同的任务和数据集需要调整多项式系数
。由于不可能调整无穷多个的
,于是作者便探索具有小自由度的各种策略。作者实验观察到,只需调整单多项式系数,这里表为示
,足以实现比Cross-entropy loss和Focal loss的更好的性能。
2主要贡献
-
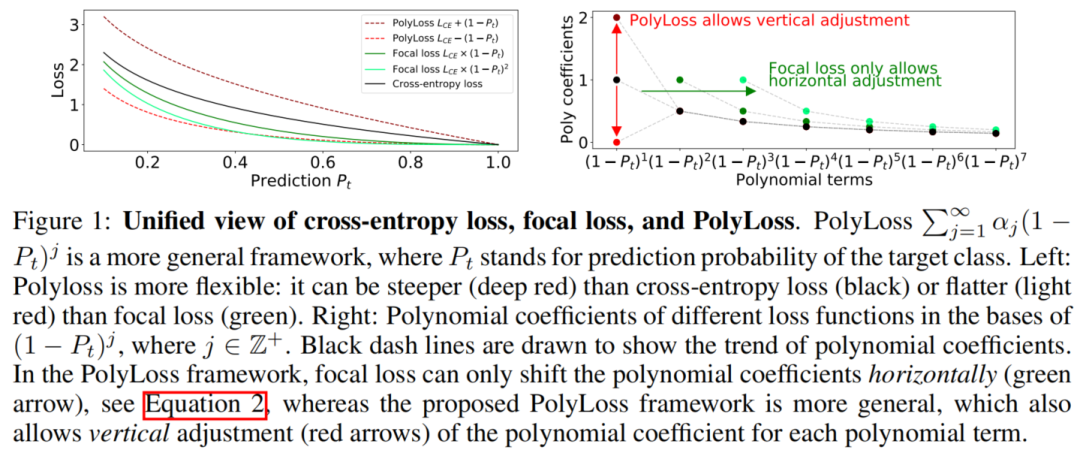
Insights on common losses:提出了一个统一的损失函数框架,名为PolyLoss,以重新思考和重新设计损失函数。这个框架有助于将Cross-entropy loss和Focal loss解释为多损失族的2种特殊情况(通过水平移动多项式系数),这是以前没有被认识到的。这方面的发现促使研究垂直调整多项式系数的新损失函数,如图1所示。 -
New loss formulation:评估了垂直移动多项式的不同方法,以简化超参数搜索空间。提出了一个简单而有效的Poly-1损失,它只引入了一个超参数和一行代码。 -
New findings:作者发现Focal loss虽然对许多检测任务有效,但对于不平衡的ImageNet-21K并不是很优秀。作者还发现多项式在训练过程中对梯度有很大的贡献,其系数与预测置信度 相关。 -
Extensive experiments:在不同的任务、模型和数据集上评估了PolyLoss。结果显示PolyLoss持续提高了所有方面的性能。
3PolyLoss
PolyLoss为理解和改进常用的Cross-entropy loss、Focal loss提供了一个框架,如图1所示。它的灵感来自于Cross-entropy loss和Focal loss的基于
泰勒展开式:
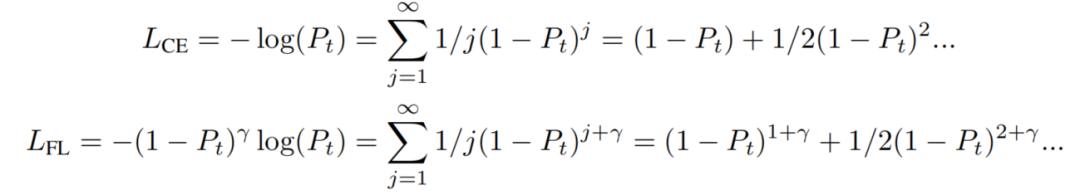
式中 为模型对目标类的预测概率。
3.1 Cross-entropy loss as PolyLoss
使用梯度下降法来优化交叉熵损失需要对Pt进行梯度。在PolyLoss框架中,一个有趣的观察是系数
正好抵消多项式基的第
次幂。因此,Cross-entropy loss的梯度就是多项式
的和:
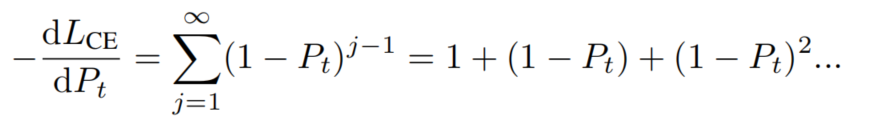
梯度展开中的多项式项捕获了对 的不同灵敏度。第一个梯度项是1,它提供了一个恒定的梯度,而与 的值无关。相反,当 时, 接近1时,第 项被强烈抑制。
3.2 Focal loss as PolyLoss
在PolyLoss框架中,Focal loss通过调制因子γ简单地将
移动。这相当于水平移动所有的多项式系数的γ。为了从梯度的角度理解Focal loss,取关于
的Focal loss梯度:
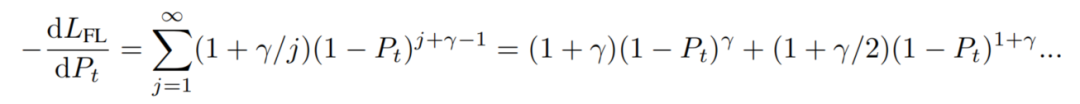
对于正的γ,Focal loss的梯度降低了Cross-entropy loss中恒定的梯度项1。正如前段所讨论的,这个恒定梯度项导致模型强调多数类,因为它的梯度只是每个类的示例总数。
通过将所有多项式项的幂移动γ,第1项就变成 ,被γ抑制,以避免过拟合到(即 接近1)多数类。
3.3 与回归和一般形式的联系
在PolyLoss框架中表示损失函数提供了与回归的直观联系。对于分类任务,
是GT标签的有效概率,多项式基
可以表示为
;
因此,Cross-entropy loss和Focal loss都可以解释为预测到标签的距离的j次幂的加权集合。
因此,交叉熵损失和焦点损失都可以解释为预测和标记到第j次幂之间的距离的加权集合。
然而,在这些损失中有一个基本的问题:回归项前的系数是最优的吗?
一般来说,PolyLoss是[0,1]上的单调递减函数,可以表示为
,并提供了一个灵活的框架来调整每个系数。PolyLoss可以推广到非整数j,但为简单起见,本文只关注整数幂(
)。
4理解多项式系数的影响
在前面的谈论中建立了PolyLoss框架,并展示了Cross-entropy loss和Focal loss简单地对应于不同的多项式系数,其中Focal loss就可以表达为水平移动了多项式系数的Cross-entropy loss。
这里要深入研究了垂直调整多项式系数对于训练可能的影响。具体来说,作者探索了3种分配多项式系数的不同策略:
-
去掉高阶项 -
调整多个靠前多项式系数 -
调整第1个多项式系数

作者发现,调整第1个多项式系数(Poly-1)便可以最大的增益,而且仅仅需要很小的代码更改和超参数调整。
4.1 :回顾高阶多项式项的删除
已有研究表明,降低高阶多项式和调整前置多项式可以提高模型的鲁棒性和性能。作者采用相同的损失公式
,并在ImageNet-1K上比较它们与基线Cross-entropy loss的性能。
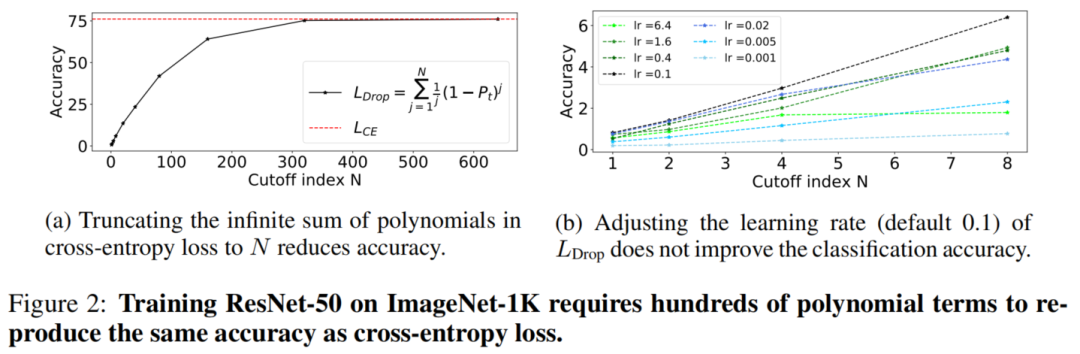
如图2a所示,需要求和超过600个多项式项才能匹配Cross-entropy loss的精度。值得注意的是,去除高阶多项式不能简单地解释为调整学习率。为了验证这一点,图2b比较了在不同的截止条件下不同学习率下的性能:无论从初始值0.1增加或减少学习率,准确率都会变差。
为了理解为什么高阶项很重要,作者对Cross-entropy loss中去除前N个多项式项后的结果进行了求和:
定理1:对于任何小的ζ>0,δ>0,如果N> ,那么对于任何p∈[δ,1],都有|R_N(p)|<ζ和|R'_N(p)|<ζ。
因此,从损失和损失导数[δ,1]的角度来看,需要取一个大的N来确保 尽可能地接近 。对于固定ζ,当δ接近0时,N迅速增大。作者的实验结果与定理一致。
高阶(j>N+1)多项式在训练的早期阶段发挥重要作用,此时 通常接近于零。例如,当 时,根据公式,第500项的梯度系数为 ,这是相当大的。与前面的工作不同,本文作者的实验结果表明,不能轻易地减少高阶多项式。
在PolyLoss框架中,丢弃高阶多项式等价于将所有高阶(j>N+1)多项式系数
垂直推到0。
4.2 :扰动重要的多项式系数
在本文中提出了在PolyLoss框架中设计一个新的损失函数的替代方法,其中调整了每个多项式的系数。一般来说,有无穷多个多项式系数
需要调节。因此,对最一般损失进行优化是不可行的:
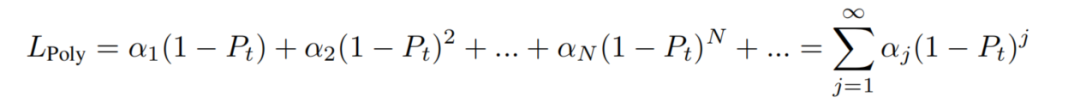
第4.1小节已经表明,在训练中需要数百个多项式来很好地完成诸如ImageNet-1K分类等任务。如果天真地将方程中的无限和截断到前几百项,那么对这么多多项式的调优系数仍然会带来一个非常大的搜索空间。此外,综合调整许多系数也不会优于Cross-entropy loss。
为了解决这一问题,作者提出扰动交叉熵损失中的重要的多项式系数(前N项),同时保持其余部分不变。将所提出的损失公式表示为 ,其中N表示将被调整的重要系数(前N项)的数量。
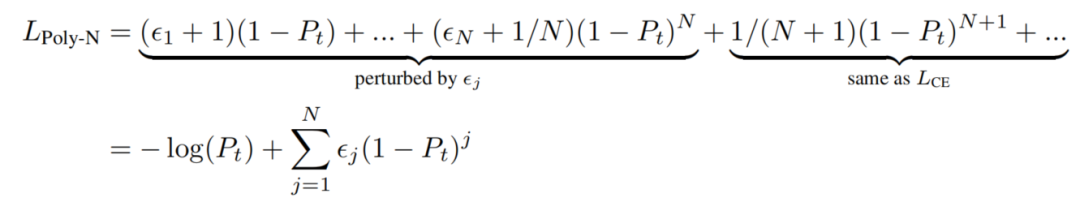
这里,用
来替代第
个Cross-entropy loss项的系数
,其中
是扰动项。这使得可以精确地定位第1个N个多项式,而不需要担心无限多个高阶(j>N+1)系数。
表3显示了
的性能优于Cross-entropy loss的。
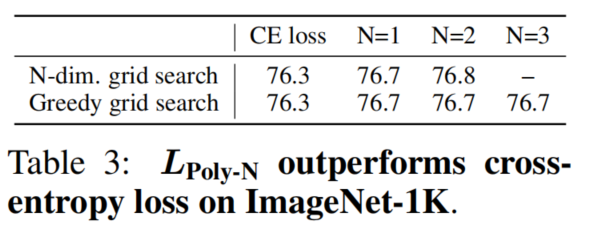
作者还探索了在N=1~3的 中对j的N维网格搜索和贪婪网格搜索,发现简单地调整第1个多项式的系数(N=1)便可以获得更好的分类精度。
4.3 :简单而有效
如前一节所示,作者发现调整第1个多项式项会带来最显著的增益。在本节中,进一步简化了Poly-N公式,并重点计算了Poly-1,其中只修改了Cross-entropy loss中的第1个多项式系数。
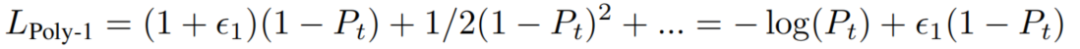
作者还研究了不同第1项缩放对精度的影响,并观察到增加第1个多项式系数可以提高ResNet-50的精度,如图3a所示。
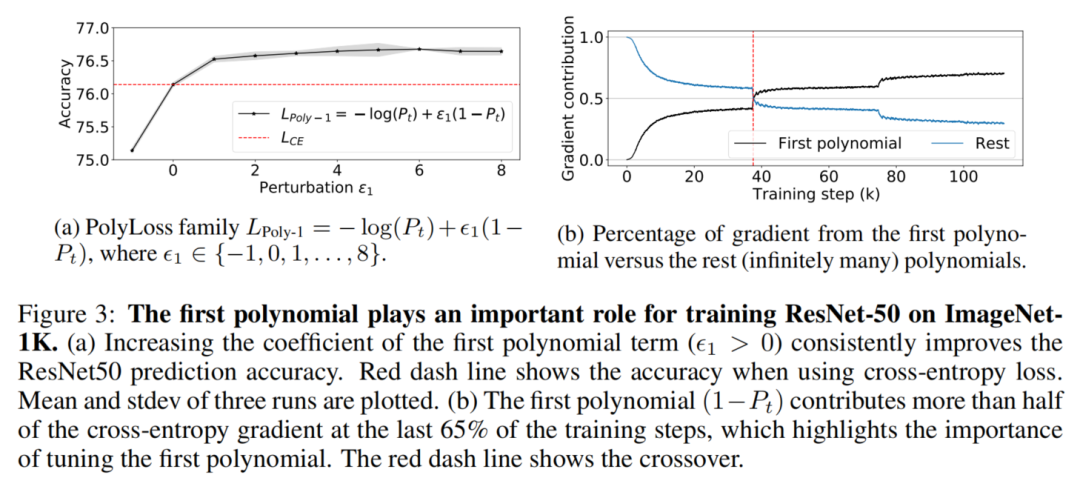
这一结果表明,Cross-entropy loss在多项式系数值上是次优的,增加第1个多项式系数可以得到一致的改善。
图3b显示了在训练的大部分时间内,多项式贡献了Cross-entropy梯度的一半以上,这突出了第1个多项式项
与无限多项的其他项相比的重要性。
因此,在本文的其余部分中,都采用了
的形式,并主要关注于调整重要前几项多项式系数。从方程中可以明显看出,它只通过一行代码来修改了原始的损失实现(在Cross-entropy loss的基础上添加一个
项)。

注意,所有训练超参数都针对Cross-entropy loss进行了优化。即便如此,对Poly-1公式中的第1个多项式系数进行简单的网格搜索可以显著提高分类精度。作者还发现对LPoly-1的其他超参数进行优化还可以获得更高的精度。
4.4 PolyLoss的Tensorflow实现
1、PolyLoss-CE
def poly1_cross_entropy(logits, labels, epsilon=1.0):
# pt, CE, and Poly1 have shape [batch].
pt = tf.reduce_sum(labels * tf.nn.softmax(logits), axis=-1)
CE = tf.nn.softmax_cross_entropy_with_logits(labels, logits)
Poly1 = CE + epsilon * (1 - pt)
return Poly1
2、PolyLoss-Focal Loss
def poly1_focal_loss(logits, labels, epsilon=1.0, gamma=2.0):
# p, pt, FL, and Poly1 have shape [batch, num of classes].
p = tf.math.sigmoid(logits)
pt = labels * p + (1 - labels) * (1 - p)
FL = focal_loss(pt, gamma)
Poly1 = FL + epsilon * tf.math.pow(1 - pt, gamma + 1)
return Poly1
5实验
5.1 图像分类
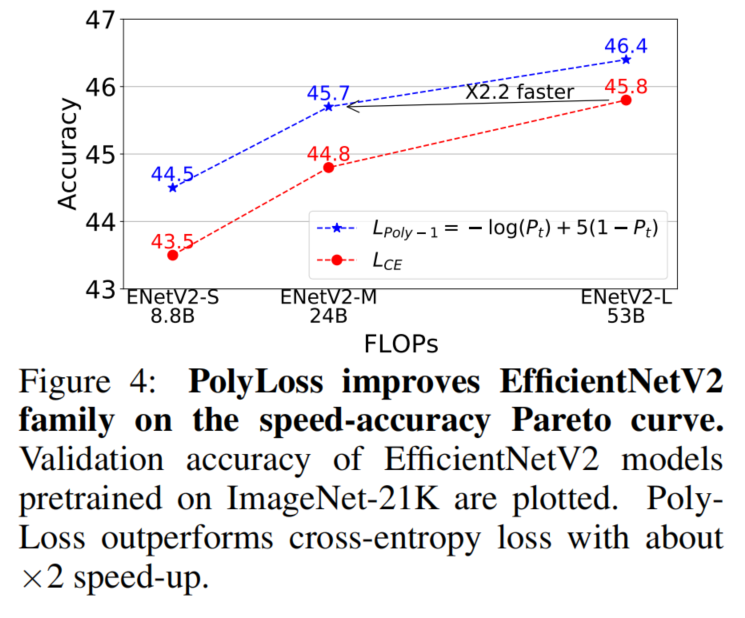

5.2 目标检测
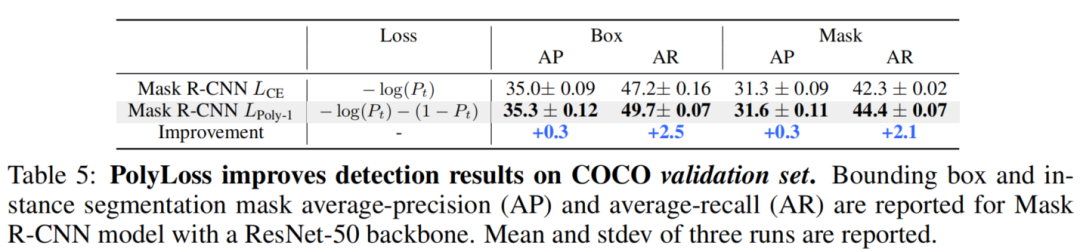
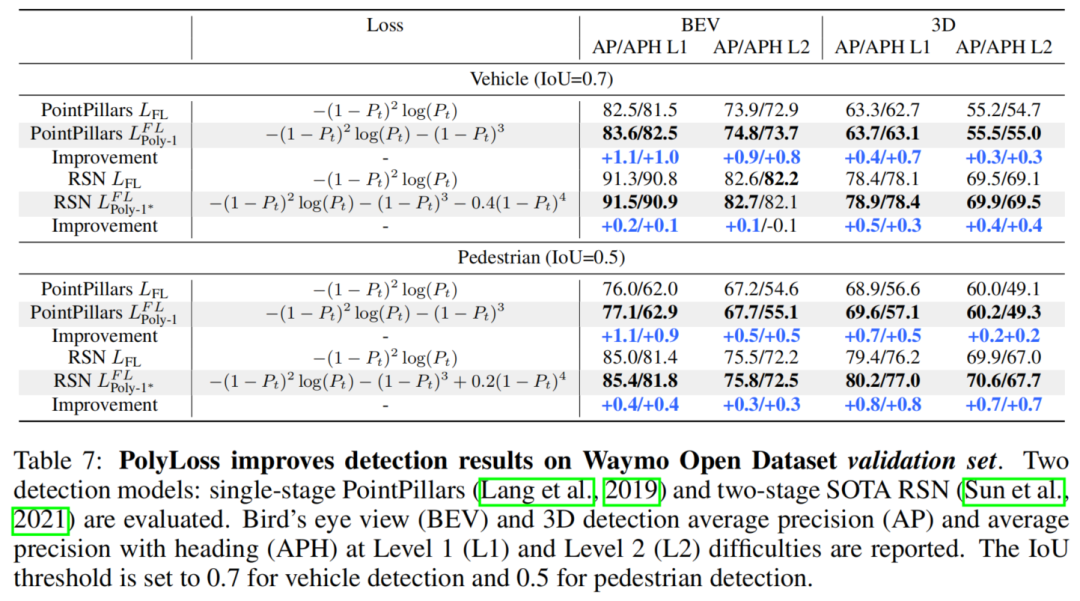
5.3 3D目标检测
PolyLoss论文PDF下载
后台回复:PolyLoss,即可下载上面论文
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号


整理不易,请点赞和在看




