Focal Loss升级!EFL:用于密集长尾目标检测的均衡Focal Loss
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
Equalized Focal Loss for Dense Long-Tailed Object Detection
代码:https://github.com/ModelTC/EOD
论文下载链接:https://arxiv.org/abs/2201.02593

尽管最近长尾目标检测取得了成功,但几乎所有的长尾目标检测器都是基于两阶段范式开发的。在实践中,一阶段检测器在行业中更为普遍,因为它们有一个简单和快速的Pipeline,易于部署。然而,在长尾情况下,这一工作迄今还没有得到探索。
在本文中,研究了一阶段检测器在这种情况下是否表现良好。作者发现,阻碍一阶段检测器取得优异性能的主要障碍是:在长尾数据分布下,类别存在不同程度的正负不平衡问题。传统的Focal Loss以所有类别中的相同调制因子来平衡训练过程,因此无法处理长尾问题。
为了解决这个问题,本文提出了均衡Focal Loss(EFL),根据不同类别的正负样本的不平衡程度,独立地重新平衡不同类别样本的损失贡献。具体来说,EFL采用了一个与类别相关的调制因子,可以根据不同类别的训练状态进行动态调整。在具有挑战性的LVISv1基准上进行的大量实验证明了所提出的方法的有效性。通过端到端训练,EFL在总体AP方面达到了29.2%,并在罕见类别上获得了显著的性能改进,超过了所有现有的最先进的方法。
开源地址:https://github.com/ModelTC/EOD
1简介
长尾目标检测是一项具有挑战性的任务,近年来越来越受到关注。在长尾场景中,数据通常带有一个Zipfian分布(例如LVIS),其中有几个头类包含大量的实例,并主导了训练过程。相比之下,大量的尾类缺乏实例,因此表现不佳。长尾目标检测的常用解决方案是数据重采样、解耦训练和损失重加权。尽管在缓解长尾不平衡问题方面取得了成功,但几乎所有的长尾物体检测器都是基于R-CNN推广的两阶段方法开发的。在实践中,一阶段检测器比两阶段检测器更适合于现实场景,因为它们计算效率高且易于部署。然而,在这方面还没有相关的工作。
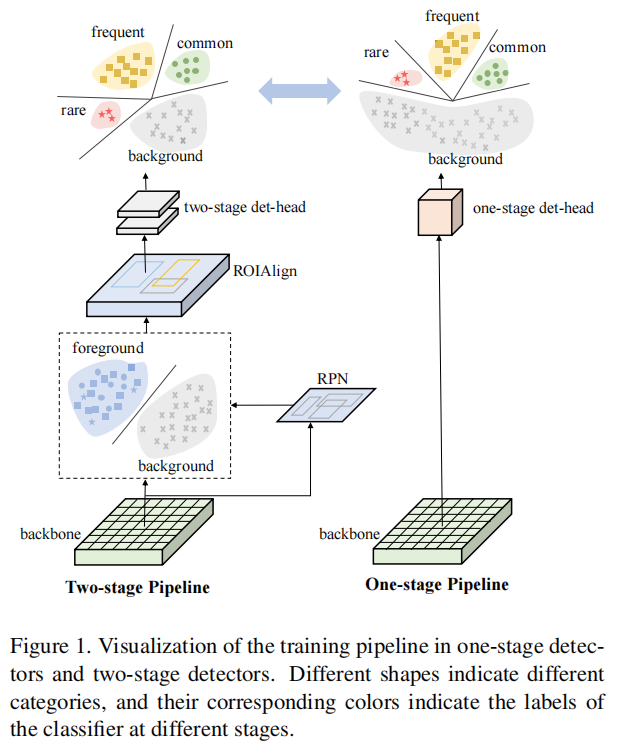
与包含区域建议网络(RPN)的两阶段方法,在将建议提供给最终的分类器之前过滤掉大多数背景样本相比,一阶段检测器直接检测规则的、密集的候选位置集上的目标。如图1所示,由于密集的预测模式,在一阶段检测器中引入了极端的前景-背景不平衡问题。结合长尾场景下的前景类别(即类别的前景样本)不平衡问题,严重损害了一阶段检测器的性能。
Focal Loss是解决前景-背景不平衡问题的一种常规解决方法。它侧重于硬前景样本的学习,并减少了简单背景样本的影响。这种损失再分配技术在类别平衡分布下效果很好,但不足以处理长尾情况下前景类别间的不平衡问题。为了解决这个问题,作者从两阶段中现有的解决方案(如EQLv2)开始,将它们调整在一阶段检测器中一起处理Focal Loss。作者发现这些解决方案与它们在两阶段检测器上的应用相比,只带来了微小的改进(见表1)。然后,作者认为,简单地结合现有的解决方案与Focal Loss,不能同时解决这两种类型的不平衡问题。通过比较不同数据分布中正样本与负样本的比值(见图2),进一步认识到这些不平衡问题的本质是类别之间的正负不平衡程度不一致。罕见类别比频繁类别遭受更严重的正负失衡,因此需要更多的重视。
在本文中,提出了均衡Focal Loss(EFL),通过将一个类别相关的调制因子引入Focal Loss。具有两个解耦的动态因子(即聚焦因子和加权因子)的调制因子独立处理不同类别的正负不平衡。focusing factor根据硬正样本对应类别的不平衡程度,决定了对硬正样本的学习集中度。加权因子增加了稀有类别的影响,确保了稀有样本的损失贡献不会被频繁的样本所淹没。这两个因素的协同作用使EFL在长尾场景中应用一阶段检测器时,能够均匀地克服前景-背景不平衡和前景类别不平衡。
在具有挑战性的LVISv1基准测试上进行了广泛的实验。通过简单有效的起始训练,达到29.2%的AP,超过了现有的长尾目标检测方法。在开放图像上的实验结果也证明了方法的泛化能力。
综上所述,主要贡献可以总结如下:
-
是第一个研究单阶段长尾目标检测的工作; -
提出了一种新的均衡Focal Loss,它用一个类别相关的调制因子扩展了原始的Focal Loss。它是一种广义的Focal Loss形式,可以同时解决前景-背景不平衡和前景类别不平衡的问题; -
在LVISv1基准测试上进行了广泛的实验,结果证明了方法的有效性。它建立了一种新的先进技术,可以很好地应用于任何单阶段检测器。
2相关工作
2.1 普通目标检测
近年来,由于卷积神经网络的巨大成功,计算机视觉社区在目标检测方面有了显著的进步。现代目标检测框架大致可分为两阶段方法和一阶段方法。
1、两阶段目标检测
随着快速RCNN的出现,两阶段方法在现代目标检测中占据了主导地位。两阶段检测器首先通过区域建议机制(如选择性搜索或RPN)生成目标建议,然后根据这些建议执行特征图的空间提取,以便进一步预测。由于这个建议机制,大量的背景样本被过滤掉了。在之后,大多数两阶段检测器的分类器在前景和背景样本的相对平衡的分布上进行训练,比例为1:3。
2、一阶段目标检测
一般来说,一阶段目标检测器有一个简单和快速的训练管道,更接近真实世界的应用。在单阶段的场景中,检测器直接从特征图中预测检测框。一阶段目标检测器的分类器在一个有大约104到105个候选样本的密集集合上进行训练,但只有少数候选样本是前景样本。有研究试图从困难样本挖掘的视角或更复杂的重采样/重称重方案来解决极端的前景-背景不平衡问题。
Focal Loss及其衍生重塑了标准的交叉熵损失,从而减轻了分配给良好分类样本的损失,并集中对硬样本进行训练。受益于Focal Loss,一阶段目标检测器实现了非常接近两阶段目标检测器方法的性能,同时具有更高的推理速度。最近,也有学者尝试从标签分配的角度来提高性能。
而本文提出的EFL可以很好地应用于这些单阶段框架,并在长尾场景中带来显著的性能提高。
2.2 Long-Tailed 目标检测
与一般的目标检测相比,长尾目标检测是一项更加复杂的任务,因为它存在着前景类别之间的极端不平衡。解决这种不平衡的一个直接方法是在训练期间执行数据重采样。重复因子采样(RFS)对来自尾部类的训练数据进行过采样,而对来自图像级的头部类的训练数据进行过采样。
有学者以解耦的方式训练检测器,并从实例级别提出了一个具有类平衡采样器的额外分类分支。Forest R-CNN重新采样从RPN与不同的NMS阈值的建议。其他工作是通过元学习方式或记忆增强方式实现数据重采样。
损失重加权是解决长尾分布问题的另一种广泛应用的解决方案。有研究者提出了均衡损失(EQL),它减轻了头类对尾类的梯度抑制。EQLv2是EQL的一个升级版,它采用了一种新的梯度引导机制来重新衡量每个类别的损失贡献。
也有学者从无统计的角度解释了长尾分布问题,并提出了自适应类抑制损失(ACSL)。DisAlign提出了一种广义的重加权方法,在损失设计之前引入了一个平衡类。除了数据重采样和损失重加权外,许多优秀的工作还从不同的角度进行了尝试,如解耦训练、边缘修改、增量学习和因果推理。
然而,所有这些方法都是用两阶段目标检测器开发的,到目前为止还没有关于单阶段长尾目标检测的相关工作。本文提出了基于单阶段的长尾目标检测的第一个解决方案。它简单而有效地超越了所有现有的方法。
3本文方法
3.1 再看Focal Loss
在一阶段目标检测器中,Focal Loss是前景-背景不平衡问题的解决方案。它重新分配了易样本和难样本的损失贡献,大大削弱了大多数背景样本的影响。二分类Focal Loss公式为:
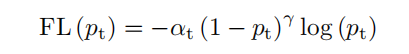
表示一个候选目标的预测置信度得分,而术语 是平衡正样本和负样本的重要性的参数。调节因子 是Focal Loss的关键组成部分。通过预测分数 和Focal参数 ,降低了简单样本的损失,侧重于困难样本的学习。
大量的阴性样本易于分类,而阳性样本通常很难分类。因此,阳性样本与阴性样本之间的不平衡可以大致看作是容易样本与困难样本之间的不平衡。Focal参数 决定了Focal Loss的影响。它可以从等式中得出结论:一个大的 将大大减少大多数阴性样本的损失贡献,从而提高阳性样本的影响。这一结论表明,阳性样本与阴性样本之间的不平衡程度越高, 的期望值越大。
当涉及到多类情况时,Focal Loss被应用于C分类器,这些分类器作用于每个实例的s型函数转换的输出日志。C是类别的数量,这意味着一个分类器负责一个特定的类别,即一个二元分类任务。由于Focal Loss同样对待具有相同调制因子的所有类别的学习,因此它未能处理长尾不平衡问题(见表2)。
3.2 Equalized Focal Loss
在长尾数据集(即LVIS)中,除了前景-背景不平衡外,一阶段检测器的分类器还存在前景类别之间的不平衡。
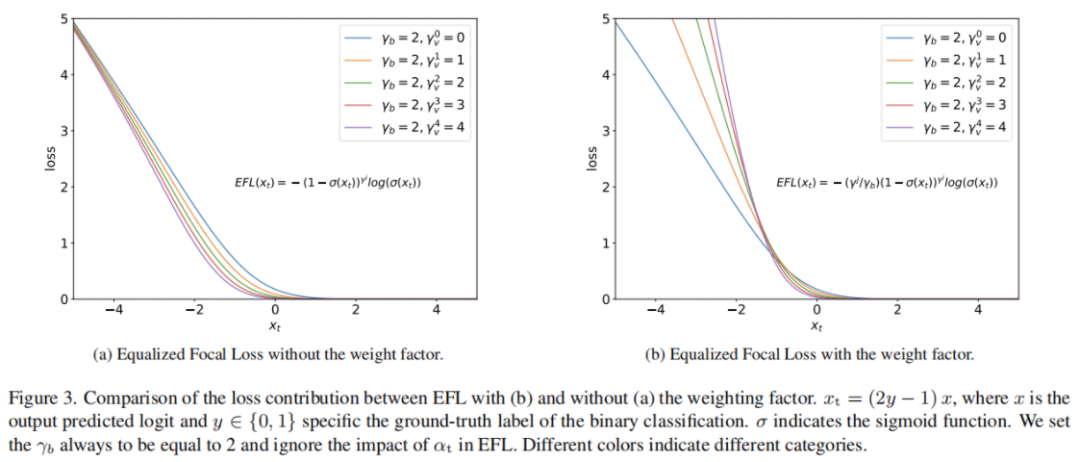
如图2所示,如果从y轴上看,正样本与负样本的比值远小于零,这主要揭示了前景和背景样本之间的不平衡。这里将该比值的值称为正负不平衡度。从x轴的角度可以看出,不同类别之间的不平衡程度存在很大差异,说明前景类别之间的不平衡。
显然,在数据分布(即COCO)中,所有类别的不平衡程度是相似的。因此,Focal Loss使用相同的调制因子就足够了。相反,这些不平衡的程度在长尾数据的情况下是不同的。罕见类别比常见类别遭受更严重的正负失衡。如表1中所示。大多数一阶段检测器在罕见类别上的表现比在频繁类别上更差。这说明,同一调制因子并不适用于所有不同程度的不平衡问题。
1、Focusing Factor
在此基础上,提出了均衡Focal Loss(EFL),该方法采用类别相关Focusing Factor来解决不同类别的正负不平衡。将第 类的损失表述为:
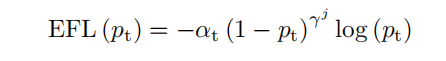
其中 和 与在Focal Loss中的相同。
参数 是第 类的Focusing Factor,它在Focal Loss中起着与 类似的作用。正如在前面提到的不同的 值对应于不同程度的正向-负向不平衡问题。这里采用一个大的 来缓解严重的正负失衡问题。对于有轻微不平衡的频繁类别,一个小的 是合适的。Focusing Factor 被解耦为2个组件,特别是一个与类别无关的参数 和一个与类别相关的参数 :
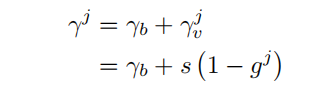
其中, 表示控制分类器基本行为的平衡数据场景中的Focusing Factor。参数 ≥0是一个与第 类不平衡度相关的变量参数。它决定了学习的注意力集中在正负不平衡问题上。受EQLv2的启发,采用了梯度引导的机制来选择 。参数 表示第 类正样本与负样本的累积梯度比。
值较大表示第j类(例如频繁)是训练平衡,较小值表示类别(例如罕见)是训练不平衡。为了满足对 的要求,将 的值定义在[0,1]范围内,并采用 来反转其分布。超参数s是决定EFL中 上限的缩放因子。与Focal Loss相比,EFL可以独立处理每个类别的正负不平衡问题,从而带来性能的提升(见表3)。
2、Weighting Factor
即使使用了Focusing Factor ,仍然有2个障碍损失的性能:
-
对于二元分类任务,更大的 适用于更严重的正负不平衡问题。而在多类的情况下,如图3a所示,对于相同的 , 的值越大,损失就越小。这导致了这样一个事实:当想要增加对学习一个具有严重的正负不平衡的类别的注意力时,必须牺牲它在整个训练过程中所做的部分损失贡献。这种困境阻碍了稀有类别获得优异的表现。 -
当 较小时,来自不同Focusing Factor的不同类别样本的损失将收敛到一个相似的值。实际上,期望罕见的困难样本比频繁的困难样本做出更多的损失贡献,因为它们是稀缺的,并且不能主导训练过程。
于是作者提出了Weighting Factor,通过重新平衡不同类别的损失贡献来缓解上述问题。与Focusing Factor相似为罕见类别分配了一个较大的权重因子值,以提高其损失贡献,同时保持频繁类别的权重因子接近于1。具体地说,将第 类的Weighting Factor设置为 ,以与Focusing Factor相一致。EFL的最终公式为:
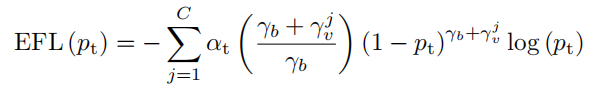
如图3b所示,使用Weighting Factor,EFL显著增加了稀有类别的损失贡献。同时,与频繁的困难样本相比,它更侧重于罕见的困难样本的学习。
Focusing Factor和Weighting Factor构成了EFL的与类别相关的调节因子。它使分类器能够根据样本的训练状态 和对应的类别状态 动态调整样本的损失贡献。Focusing Factor和Weighting Factor在EFL中均有重要作用。同时,在平衡数据分布中,所有 的EFL都相当于Focal Loss。这种吸引人的特性使得EFL可以很好地应用于不同的数据分布和数据采样器之中。
PyTorch实现如下:
@LOSSES_REGISTRY.register('equalized_focal_loss')
class EqualizedFocalLoss(GeneralizedCrossEntropyLoss):
def __init__(self,
name='equalized_focal_loss',
reduction='mean',
loss_weight=1.0,
ignore_index=-1,
num_classes=1204,
focal_gamma=2.0,
focal_alpha=0.25,
scale_factor=8.0,
fpn_levels=5):
activation_type = 'sigmoid'
GeneralizedCrossEntropyLoss.__init__(self,
name=name,
reduction=reduction,
loss_weight=loss_weight,
activation_type=activation_type,
ignore_index=ignore_index)
# Focal Loss的超参数
self.focal_gamma = focal_gamma
self.focal_alpha = focal_alpha
# ignore bg class and ignore idx
self.num_classes = num_classes - 1
# EFL损失函数的超参数
self.scale_factor = scale_factor
# 初始化正负样本的梯度变量
self.register_buffer('pos_grad', torch.zeros(self.num_classes))
self.register_buffer('neg_grad', torch.zeros(self.num_classes))
# 初始化正负样本变量
self.register_buffer('pos_neg', torch.ones(self.num_classes))
# grad collect
self.grad_buffer = []
self.fpn_levels = fpn_levels
logger.info("build EqualizedFocalLoss, focal_alpha: {focal_alpha}, focal_gamma: {focal_gamma},scale_factor: {scale_factor}")
def forward(self, input, target, reduction, normalizer=None):
self.n_c = input.shape[-1]
self.input = input.reshape(-1, self.n_c)
self.target = target.reshape(-1)
self.n_i, _ = self.input.size()
def expand_label(pred, gt_classes):
target = pred.new_zeros(self.n_i, self.n_c + 1)
target[torch.arange(self.n_i), gt_classes] = 1
return target[:, 1:]
expand_target = expand_label(self.input, self.target)
sample_mask = (self.target != self.ignore_index)
inputs = self.input[sample_mask]
targets = expand_target[sample_mask]
self.cache_mask = sample_mask
self.cache_target = expand_target
pred = torch.sigmoid(inputs)
pred_t = pred * targets + (1 - pred) * (1 - targets)
# map_val为:1-g^j
map_val = 1 - self.pos_neg.detach()
# dy_gamma为:gamma^j
dy_gamma = self.focal_gamma + self.scale_factor * map_val
# focusing factor
ff = dy_gamma.view(1, -1).expand(self.n_i, self.n_c)[sample_mask]
# weighting factor
wf = ff / self.focal_gamma
# ce_loss
ce_loss = -torch.log(pred_t)
cls_loss = ce_loss * torch.pow((1 - pred_t), ff.detach()) * wf.detach()
if self.focal_alpha >= 0:
alpha_t = self.focal_alpha * targets + (1 - self.focal_alpha) * (1 - targets)
cls_loss = alpha_t * cls_loss
if normalizer is None:
normalizer = 1.0
return _reduce(cls_loss, reduction, normalizer=normalizer)
# 收集梯度,用于梯度引导的机制
def collect_grad(self, grad_in):
bs = grad_in.shape[0]
self.grad_buffer.append(grad_in.detach().permute(0, 2, 3, 1).reshape(bs, -1, self.num_classes))
if len(self.grad_buffer) == self.fpn_levels:
target = self.cache_target[self.cache_mask]
grad = torch.cat(self.grad_buffer[::-1], dim=1).reshape(-1, self.num_classes)
grad = torch.abs(grad)[self.cache_mask]
pos_grad = torch.sum(grad * target, dim=0)
neg_grad = torch.sum(grad * (1 - target), dim=0)
allreduce(pos_grad)
allreduce(neg_grad)
# 正样本的梯度
self.pos_grad += pos_grad
# 负样本的梯度
self.neg_grad += neg_grad
# self.pos_neg=g_j:表示第j类正样本与负样本的累积梯度比
self.pos_neg = torch.clamp(self.pos_grad / (self.neg_grad + 1e-10), min=0, max=1)
self.grad_buffer = []
4实验
4.1 消融实验研究
1、EFL中组件的影响
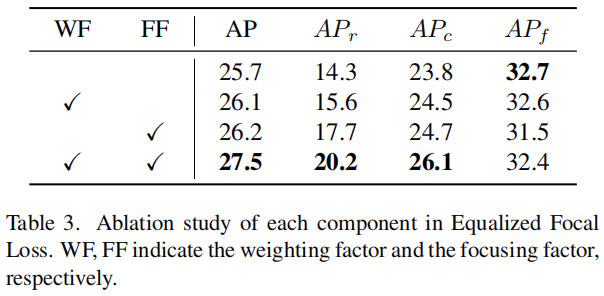
在EFL中有2个组成部分,即focusing factor和weighting factor。为了演示每个组件的效果,用提出的改进Baseline通过2倍计划和重复因子采样器来训练模型。如表3所示focusing factor和weighting factor在EFL训练过程中均有重要作用:
-
对于focusing factor,AP从25.7%提高到26.2%的AP。同时,在罕见类别上有显著提高,AP提高了3.4%,说明其在缓解严重的正负失衡问题方面的有效性。
-
对于weighting factor,通过在EFL中所有类别中设置focusing factor始终为 来观察其影响。因此,weighting factor的函数也可以看作是一种结合Focal Loss的重加权方法。正如预期的那样,weighting factor比改进的Baseline高出0.4%。
通过这2个组件的协同作用,EFL显著提高了改进的Baseline的性能,从25.7%AP提高到27.5%AP。
2、EFL中超参数的影响
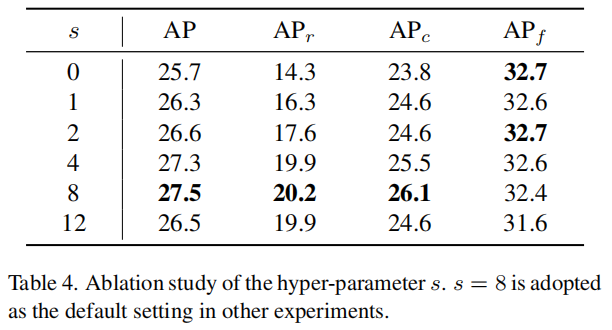
这里研究了不同s值的影响,发现s=8的性能最好。如表4中可以看出,几乎所有的s≥0都可以提高改进后Baseline的性能。更重要的是,s可以在很大的范围内保持相对较高的性能。这表明EFL是超参数不敏感的。
3、EFL中组件对于Baseline的提升影响
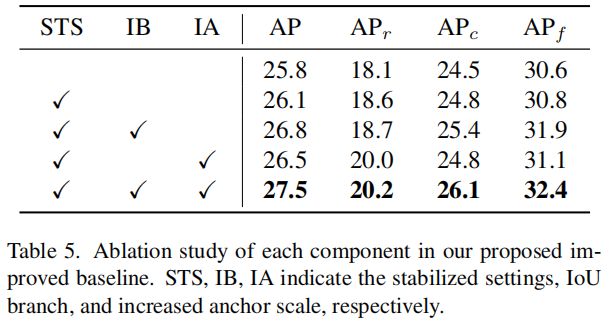
这些模型都是用提出的EFL进行训练的。如表5所示,同样的配置和训练过程,并带来了一些性能的提高(+0.3%AP)。IoU分支和增加的Anchor尺度分别使原始EFL提高了1.0%AP和0.7%AP。值得注意的是,与Tab1中的ATSS相比,即使没有稳定和改进的设置,EFL仍然带来了显著的性能改善(从24.7%AP到25.8%AP,+1.1%AP)。结合这些设置,性能改进进一步提高。如Tab2所示,本文的方法比改进的Baseline值高出1.8%。
4.2 LVIS v1实验
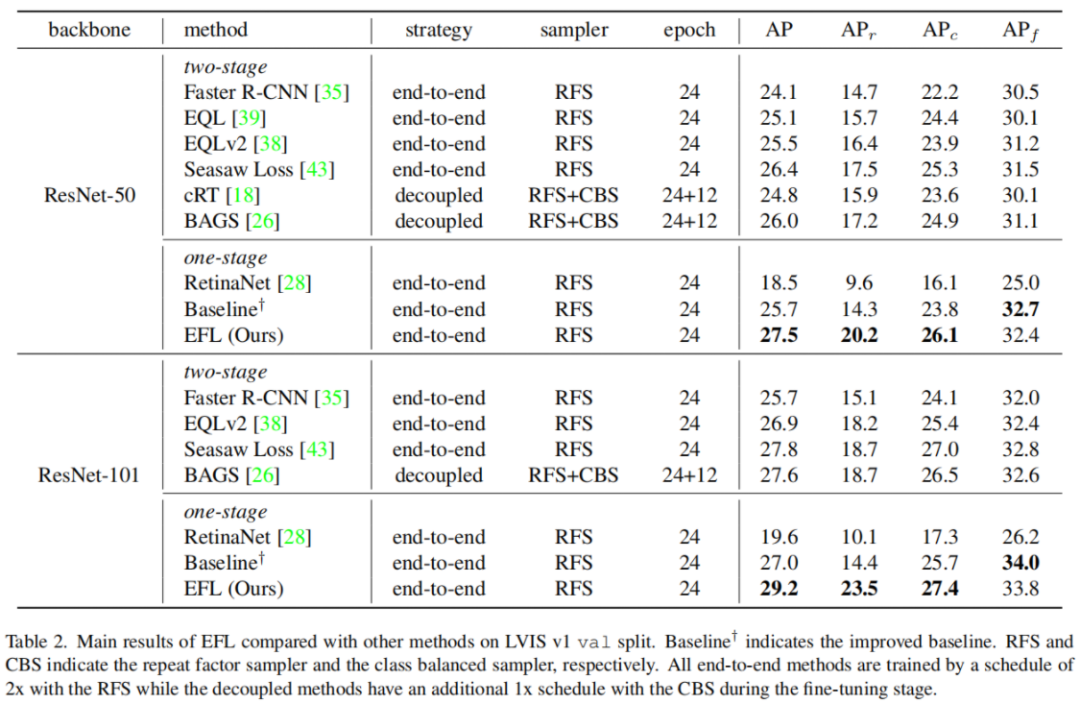
如Tab2所示,使用ResNet-50-FPN,本文提出的方法实现了总体27.5%的AP,将提出的改进Baseline提高了1.8%的AP,甚至在罕见类别上提高了5.9%。结果表明,EFL能够很好地处理稀有类的极正负失衡问题。
-
与EQL、EQLv2和SeesawLoss等其他端到端方法相比,本文方法的性能分别为2.4%、2.0%AP和1.1%AP。 -
与cRT和BAGS等解耦训练方法相比,本文方法以优雅的端到端训练策略(2.7%AP和1.5%AP)。除了高性能外,还保留了一阶段检测器的简单、快速、易于部署等优点。
4.3 模型分析
1、与其他一阶段检测器结合
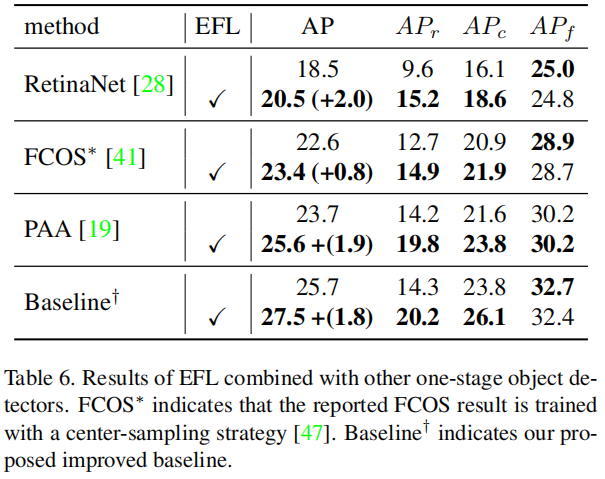
为了演示EFL在不同阶段检测器上的泛化能力,分别将其与RetinaNet、FCOS∗、PAA和改进的Baseline相结合。如表6所示,EFL在所有这些方法测试中都表现良好。与表1中的EQLv2和focal loss组合相比,提出的EFL相对于原检测器保持了稳定的较大性能提高(约+2% AP)。此外,EFL极大地提高了这些检测器在稀有类别上的性能,这表明在解决长尾分布问题方面的实力。
2、一个更明显的决策边界
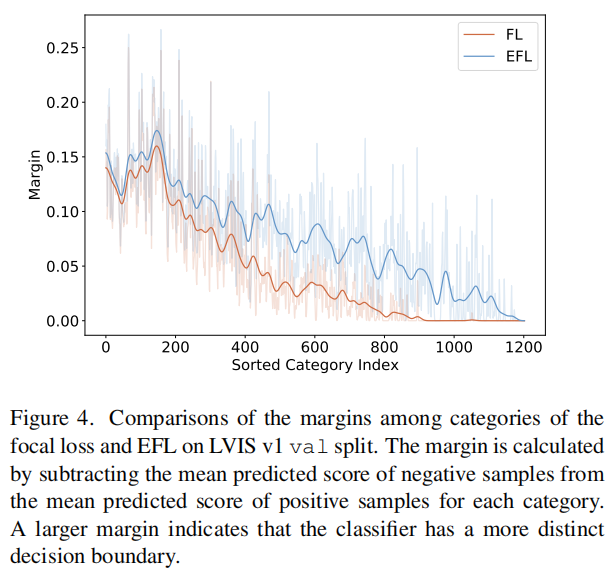
研究了EFL是否比罕见类别分类器上的Focal Loss具有更明显的决策边界。由于决策边界不能直观地显示,因此采用类别间正样本和负样本之间的经验边界来反映这些边界。边际是通过用每个类别的正样本的平均预测分数减去负样本的平均预测分数来计算的。由于EFL非常关注罕见类别的正负失衡问题,因此在EFL中,这些类别的阳性样本与阴性样本之间的差距应该很突出。如图4所示,在罕见类别中,阳性样本和阴性样本之间保持了较小的边缘。相比之下,提出的EFL增加了所有类别的边界,特别是对于稀有类别,带来了更明显的决策边界。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-目标检测交流群成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号




