新一代多模态文档理解预训练模型LayoutLM 2.0,多项任务取得新突破!
编者按:近年来,预训练模型是深度学习领域中被广泛应用的一项技术,对于自然语言处理和计算机视觉等领域的发展影响深远。2020年初,微软亚洲研究院的研究人员提出并开源了通用文档理解预训练模型 LayoutLM 1.0,受到了广泛关注和认可。如今,研究人员又提出了新一代的文档理解预训练模型 LayoutLM 2.0,该模型在一系列文档理解任务中都表现出色,并在多项任务中取得了新的突破,登顶 SROIE 和 DocVQA 两项文档理解任务的排行榜(Leaderboard)。未来,以多模态预训练为代表的智能文档理解技术将在更多的实际应用场景中扮演更为重要的角色。
文档智能是一种旨在针对扫描文件或数字商业文档(图像、PDF 文件等)进行理解并分析,同时将其中的非结构化信息进行抽取和结构化的技术。与传统的信息抽取技术不同,文档智能技术不仅仅依赖于商业文档中的文本信息,同时还会考虑更多的富文本图像和布局位置等信息对文档进行分析。例如,图1中包含了多种文档类型(包括表单、收据、发票、商业报告),不同的文档类型反应了人们所关心的信息会出现在不同的视觉位置上,而这些视觉位置经常由文档模板的类型和风格所决定。因此,如果希望能够从不同类型的文档中精确地分析和抽取出感兴趣的重要内容,仅仅考虑纯文本信息是远远不够的,而是需要利用不同模态之间的关联,通过文本、图像、布局位置信息的联合建模来进行智能文档理解。

图1:常见商业文档示例:表单、收据、发票、报告
通常来讲,文档智能的技术路线总体上分类两大类:第一类方法是利用文本和视觉信息的浅层融合进行文档内容理解,但是这种方式得到的模型通用性一般来讲不够强,需要针对不同文档模板类型训练不同的模型,因此需要更多的人工数据标注来弥补这方面的不足。
第二类方法与第一类的最大区别在于利用了文本和视觉信息的深层融合,通过端到端多模态预训练的方式对文档内容和文档图像进行联合学习。这样一来,预训练模型可以学习到不同文档模板类型的局部不变性信息,当模型需要迁移到另一种模板类型时,只需要人工标注少量的样本就可以对预训练模型进行调优。LayoutLM 1.0 模型在设计之初就采用了这种深层次预训练的方案,从模型的输入阶段就将跨模态的文档信息利用起来,从而取得了更好的结果。
在 LayoutLM 1.0 模型提出一年之后,微软亚洲研究院自然语言计算组的研究人员基于 LayoutLM 1.0 的设计方案进一步提出了 LayoutLM 2.0 模型。作为 LayoutLM 1.0 模型的延续,2.0模型的主要特点在于,在输入阶段直接引入了图像信息,利用多模态预训练框架对文本、图像和布局信息进行联合建模。不仅如此,受到纯文本预训练模型中一维相对位置表征的启发,研究人员还提出了一种空间感知自注意力机制 (spatial-aware self-attention),以帮助 Transformer 模型学习到文档图像中不同文本块之间的相对位置关系。与此同时,两种新的预训练任务被使用其中——“文本—图像对齐”和“文本—图像匹配”。实验表明,LayoutLM 2.0 模型将文档图像和其中文本内容进行统一多模态预训练,在多个智能文档理解任务中取得了最佳的结果,其中包括表单理解 FUNSD 数据集,票据理解 CORD 和 SROIE 数据集,复杂布局长文档理解 Kleister-NDA 数据集,文档图像分类 RVL-CDIP 数据集,以及文档图像视觉问答 DocVQA 数据集。
LayoutLM 2.0 的主体结构是带有空间感知自注意力机制的多模态 Transformer 编码器网络,它主要有两方面优势:其一是在输入阶段同时接受文本、图像、布局三种模态的信息,利用深层网络的强大建模能力实现多模态深度融合;其二是基于文档智能领域特性的空间感知自注意力机制,通过在传统自注意力机制的基础上显式添加空间相对位置信息,进一步帮助模型在一维文本序列基础上加深对二维版面信息的理解。
如图2所示,模型首先将文本、图像、布局三种模态的输入转换成向量表示,然后再交给编码器网络,最终输出的表示向量可以供下游任务使用。下面将从三种模态输入的向量表示以及编码器网络四个方面展开描述。
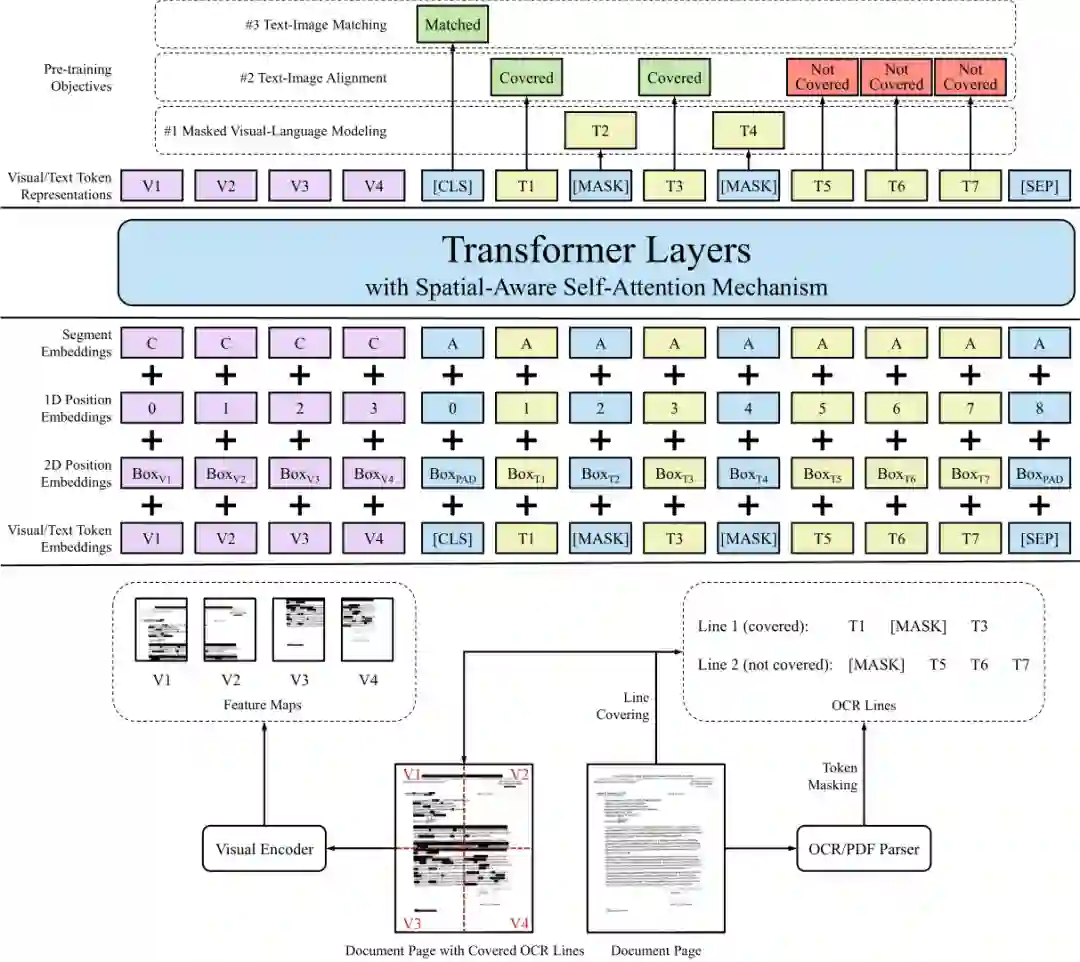
图2:LayoutLM 2.0 模型结构及预训练任务示意图
文本向量 (Text Embedding)
文本输入采用常规做法,使用 WordPiece 切分原始输入文本,之后添加 [CLS] 和 [SEP] 标记,并用 [PAD] 补齐长度得到文本输入序列:
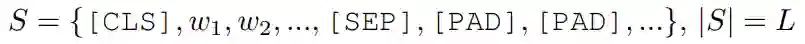
再将词向量、一维位置向量、分段向量(代表 [A] 或 [B])相加得到文本向量,算法公式如下:
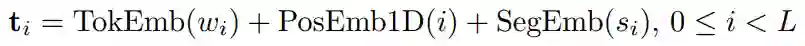
图像向量 (Image Embedding)
LayoutLM 1.0 采用了整体和局部两种图像表示方法。使用图像整体表示可以帮助模型捕捉页面整体样式信息,但是模型难以高效建模细节特征。而使用图像中的局部文本区域则会顾及更多细节特征,但文本区域众多,且非文本区域也可能含有重要的视觉信息。因此2.0结合二者特点,可以将图像网格状均分,表示为定长向量序列。
使用 ResNeXt-FPN 网络作为图像编码器,要先抽取原始文档图像的特征图,再将其平均池化为固定尺寸(W×H),接着按行展开平均池化后的特征图,之后经过线性投影,就可以得到图像对应的特征序列。和文本向量的组成对应,图像向量也补充了一维相对位置和分段信息。有别于文本的 [A]、[B] 段,图像统一归入 [C] 段。用特征向量、一维位置向量、分段向量相加得到最终的图像向量:
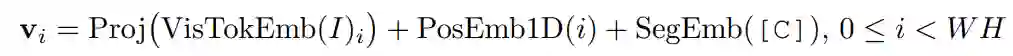
布局向量 (Layout Embedding)
对应于每个词或图像区域在页面中覆盖的坐标范围,使用平行于坐标轴的边界框(bounding box)表示布局信息。LayoutLM 2.0 沿用了1.0的处理方式,用4个边界坐标值、宽、高来表示一个边界框。最终的布局向量由6个特征对应的向量拼接得到:
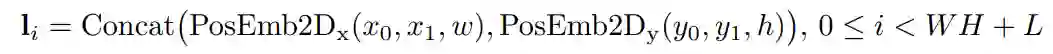
基于空间感知自注意力机制的多模态编码器
为了融合三种输入模态,编码器部分首先将图像向量序列和文本向量序列拼接成统一的输入序列,并且在对应位置加上布局向量。编码器首层输入可以表示为:
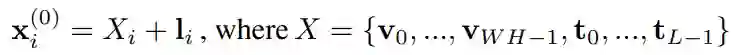
编码器部分改进了传统的自注意力机制,引入了空间相对位置信息。传统自注意力机制通过如下方式计算注意力得分:
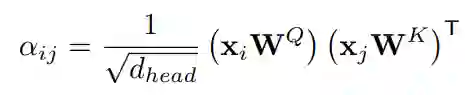
可以看出,这种方式只能隐式地利用输入的绝对位置信息。于是为注意力得分显式地添加空间相对位置偏差项:
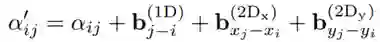
基于这种空间感知的自注意力权重,编码器可以将模型隐藏层表示为:
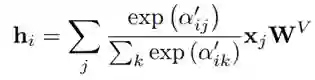
如图2顶部所示,LayoutLM 2.0 的预训练阶段采用了3个自监督预训练任务帮助模型提升语言能力、对齐模态信息。
遮罩式视觉语言模型(Masked Visual-Language Model)
作为对 LayoutLM 1.0 的扩展,2.0使用的遮罩式视觉语言模型任务要求模型根据图文和布局信息中的上下文还原文本中被遮盖的词,遮盖操作同时遮盖文本中的词和图像中的对应区域,但保留空间位置信息。
文本—图像对齐(Text-Image Alignment)
遮罩式视觉语言模型更关注模型的语言能力,视觉和布局信息只提供隐式线索,为此一种细粒度的多模态对齐任务在 LayoutLM 2.0 中被提出,即文本—图像对齐。该方法在文档图像上随机按行遮盖一部分文本,利用模型的文本部分输出进行词级别二分类,预测每个词是否被覆盖。文本—图像对齐任务帮助模型对齐文本和图像的位置信息。
文本—图像匹配(Text-Image Match)
现有工作证明,粗粒度的文本—图像匹配任务有助于帮助模态信息对齐。对于预训练阶段的文档数据,随机地替换或舍弃一部分文档图像,会构造图文失配的负样本。LayoutLM 2.0 的模型以文档级二分类的方式预测图文是否匹配,以此来对齐文本和图像的内容信息。
预训练
LayoutLM 2.0 的预训练采用了 IIT-CDIP Test Collection 数据集,数据集包含千万级扫描文档图像,从中抽取文本和对应位置信息的数据准备工作使用的是 Microsoft Read API。研究人员训练了 BASE、LARGE 两种规模的模型,参数量分别是200M、426M。
下游任务微调:表单理解
表单理解任务使用了 FUNSD 作为测试数据集,该数据集中的199个标注文档包含了31,485个词和9,707个语义实体。任务要求模型从表单中抽取四种类型的语义实体,包括问题、答案、标题、其他。下表所示的实验结果表明,多模态融合预训练方式显著提高了模型性能,F1 达到84.20%。
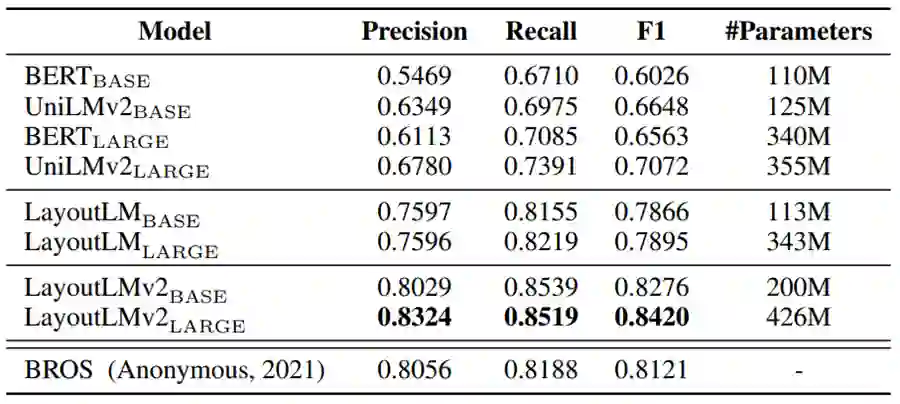
表1:LayoutLM 2.0 在表单理解数据集 FUNSD 上的实验结果
下游任务微调:票据理解
研究人员使用了 CORD 和 SROIE 两个票据理解数据集来评估模型性能。CORD 数据集包含了1,000张扫描票据数据,需要从中抽取名称、价格、数量等30类关键信息实体。LayoutLM 2.0 模型在此数据集上微调后F1值达到96.01%。
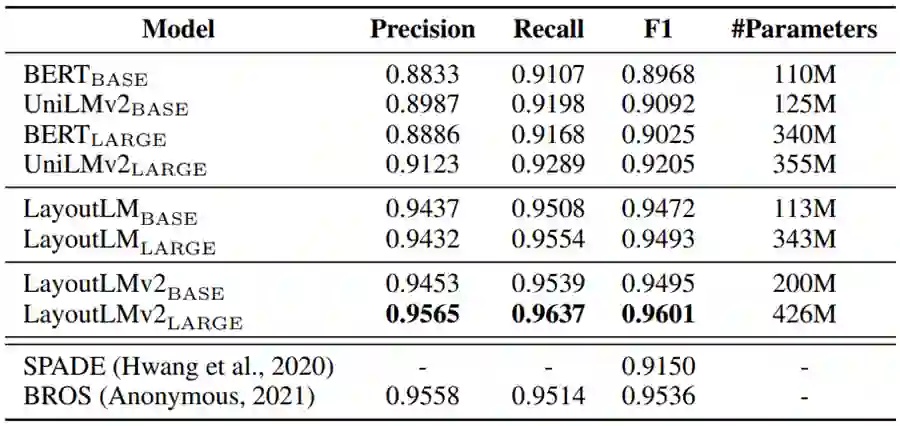
表2:LayoutLM 2.0 在票据理解数据集 CORD 上的实验结果
SROIE 数据集由1,000张票据数据组成,数据中标注了店铺名、店铺地址、总价、消费时间四个语义实体,是票据理解领域中被广泛使用的数据集。通过在该数据集上微调,LayoutLM 2.0 模型预测结果的 F1 值达到了97.81%,位列 SROIE 测评任务三榜首。
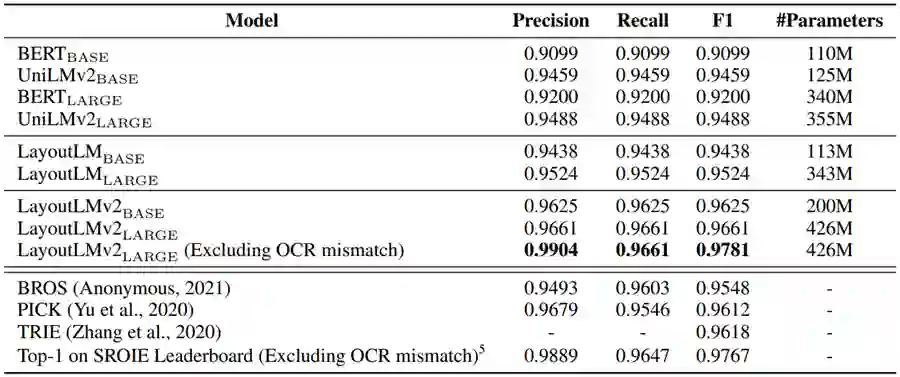
表3:LayoutLM 2.0 在票据理解数据集 SROIE 上的实验结果
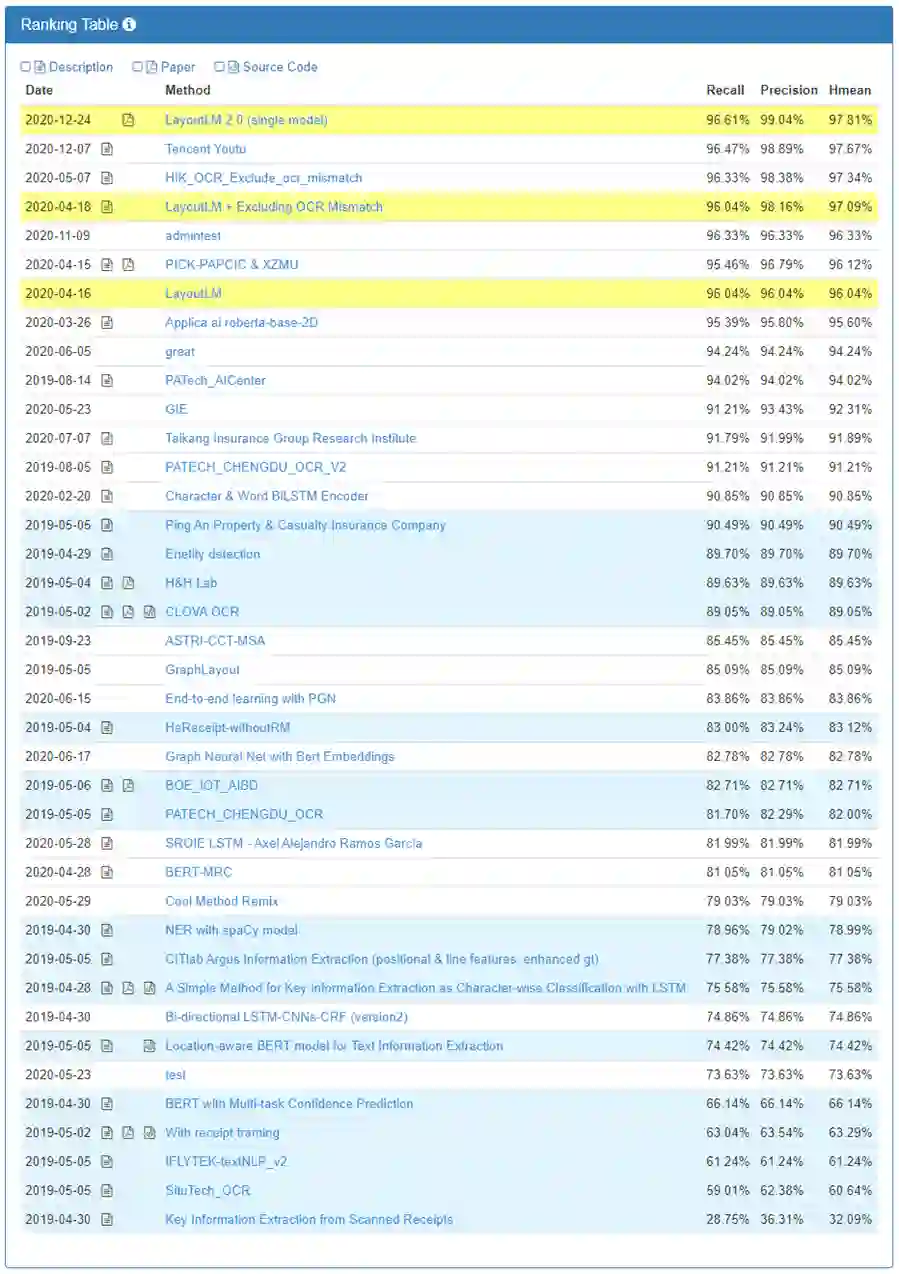
图3:SROIE 排行榜(截至2020-12-24)
下游任务微调:复杂布局长文档理解
Kleister-NDA 数据集提供了254篇合同文档数据,其特点是页面布局复杂且内容较长。实验针对数据集标注中预定义的四类关键信息实体进行抽取,结果表明 LayoutLM 2.0 模型性能相比1.0取得了进一步提升,F1 达到85.2%。
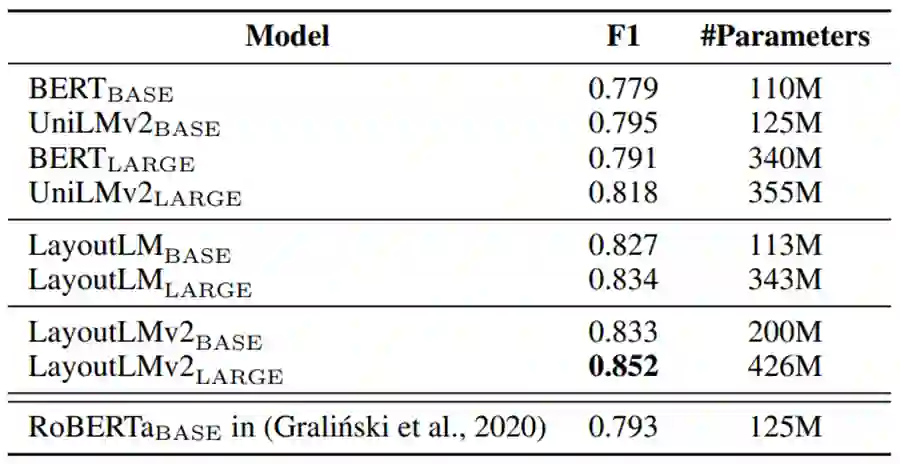
表4:LayoutLM 2.0 在复杂布局长文档理解数据集 Kleister-NDA 上的实验结果
下游任务微调:文档图像分类
文档图像分类任务使用了 RVL-CDIP 数据集测试模型性能。数据集由16类文档组成,每类均包含25,000页文档图像,共计40万页文档图像数据。经过微调,LayoutLM 2.0 模型的预测准确率相比先前的最好结果提升了1.2个百分点,达到了95.64%。
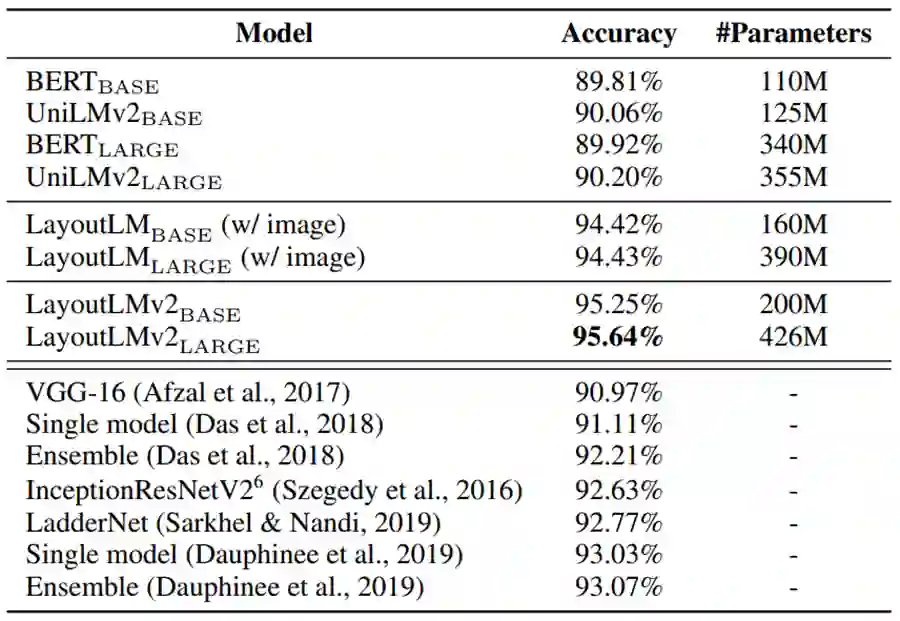
表5:LayoutLM 2.0 在文档图像分类数据集 RVL-CDIP 上的实验结果
下游任务微调:视觉问答
研究人员使用 DocVQA 数据集来验证 LayoutLM 2.0 模型在视觉问答任务上的效果,该数据集共包含超过一万页文档上的五万组问答对。得益于文本、图像、布局信息的深度融合,LayoutLM 2.0 性能相比 LayoutLM 1.0 和纯文本模型有了显著进步。经过数据增强和全量数据微调,LayoutLM 2.0 单模型性能超出了使用30个模型联合预测的原榜首方法1.6个百分点,达到86.72%,成为新的 SOTA。
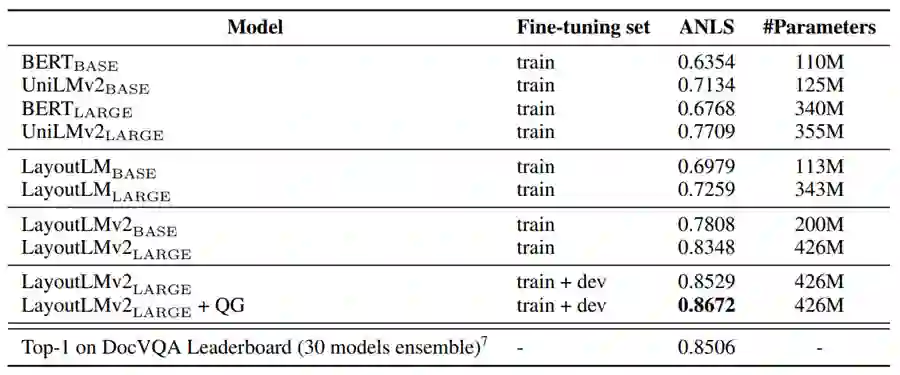
表6:LayoutLM 2.0 在视觉问答数据集 DocVQA 上的实验结果
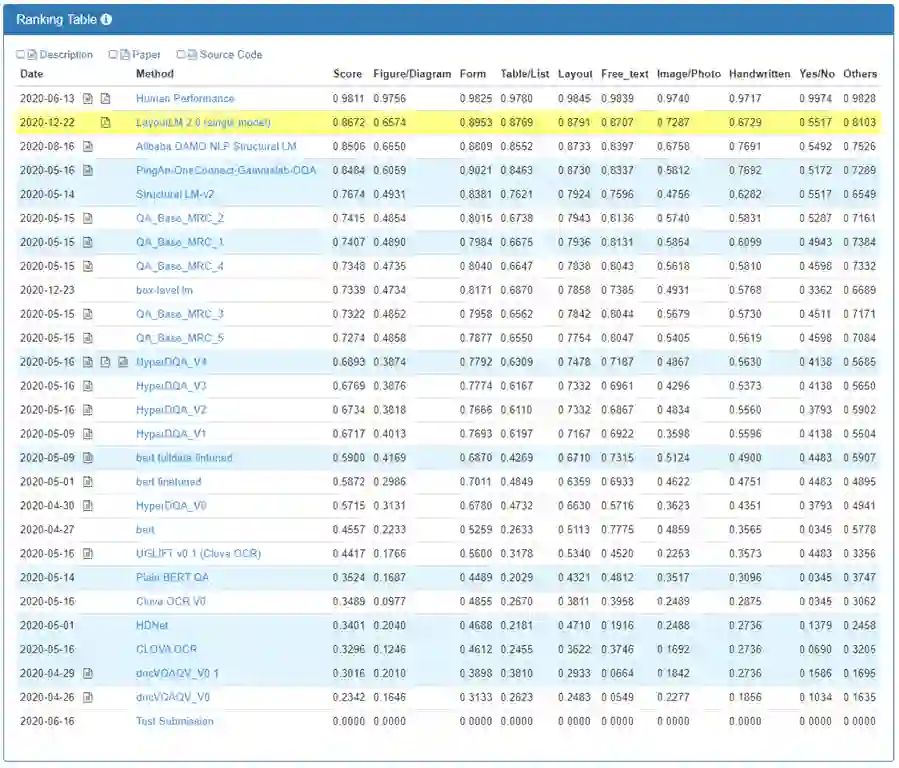
图4:DocVQA 排行榜(截至2020-12-24)
消融实验
为了探究模型各部分带来的影响,研究人员从 LayoutLM 1.0 出发,通过依次添加改动的方式在 DocVQA 数据集上进行了消融实验,结果如表7所示。LayoutLM 2.0 主要有四点主要升级:在输入中融合图像信息(#1到#2a)、添加新的多模态对齐预训练任务(#2a到#2d)、在多模态编码器中引入空间感知自注意力机制(#2d到#3)、使用更好的初始化模型(#3到#4)。可以观察到,各部分改进均显著提高了模型性能。整理来看,模型 ANLS 得分从68.41%提升到了74.21%,充分证明了LayoutLM 2.0 改进的有效性。

表7:针对图像输入、预训练任务、空间感知自注意力机制、初始化的消融实验
针对多模态文档理解任务提出的多模态预训练模型 LayoutLM 2.0,不仅考虑了文本和页面布局信息,还将图像信息融合到了多模态框架内。同时,空间感知自注意力机制的引入进一步提高了模型对文档内容的理解能力。为了进一步在模态间建立深度关联,研究人员也提出了新的多模态信息对齐预训练任务。实验结果显示,经过预训练—微调的 LayoutLM 2.0 在对应不同类型任务的六个文档理解数据集上显著优于基线方法,表明提出的方法能够有效提升文档理解效果。
在未来的研究中,微软亚洲研究院的研究员们将进一步探索 LayoutLM 系列模型的架构和预训练策略,以及相应的多语言扩展,从而在各方面增强模型的文档理解能力。
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴



