最新《多模态预训练模型》概述!
作者:哈工大SCIR 吴洋、胡晓毓
1.介绍
让机器能以人类智能相似的方式作出反应一直是人工智能研究人员的目标。为了让机器能听会说、能看会认、能理解会思考, 研究者提出一系列相关任务,如人脸识别、语音合成、阅读理解等来训练及评价机器在某一方面的智能程度。具体来说是,领域专家人工构造标准数据集,然后在其上训练及评价相关模型及方法。但由于相关技术的限制,要想获得效果更好、能力更强的模型,往往需要在大量的有标注的数据上进行训练。
近期预训练模型的出现在一定程度上缓解了这个问题。预训练模型的解决思路是,既然昂贵的人工标注难以获得,那么就去寻找廉价或者说几乎无代价的标注信息。先利用廉价的标注信息预训练模型再使用少量的昂贵的人工标注对模型进行微调。但是由于廉价的标注信息带来的信息比较少又含有噪音,往往需要超大规模的数据以及超长的训练时间对模型进行预训练。目前来看这种代价是值得的,文本预训练模型BERT一出世就在多项NLP任务上取得最好的结果。受此影响,语音领域预训练模型也如雨后春笋般出现,如 MOCKINGJAY等。预训练模型通过在大规模无标注数据上进行预训练,一方面可以将从无标注数据上更加通用的知识迁移到目标任务上,进而提升任务性能;另一方面,通过预训练过程学习到更好的参数初始点使得模型在目标任务上只需少量数据就能达到不错的效果。
那么能否将预训练方法应用到多模态任务上呢?能否通过挖掘不同模态数据之间关系设计预训练任务训练模型呢?能否通过大规模的无标注样本让模型理解懂得不同模态数据之间的关联呢(如:文字的“马”与图片中的“马”)?研究人员也抱着同样的问题展开了探索,并取得了一定成果。本文梳理了目前多模态预训练领域相关方法,并总结了各个方法所设计的预训练任务及验证实验所使用的下游任务,希望对读者能有所帮助。
2.多模态预训练模型概览
我们期望多模态预训练模型能够通过大规模数据上的预训练学到不同模态之间的语义对应关系。在图像-文本中,我们期望模型能够学会将文本中的“狗”和图片中“狗”的样子联系起来。在视频-文本中,我们期望模型能够将文本中的物体/动作与视频中的物体/动作对应起来。为实现这个目标,需要巧妙地设计预训练模型来让模型挖掘不同模态之间的关联。本文将侧重介绍“如何设计预训练任务”并通过表格来统计各个模型设计任务的异同。需要说明的是,为了方便对比我们统一了不同论文对相似任务的称呼。
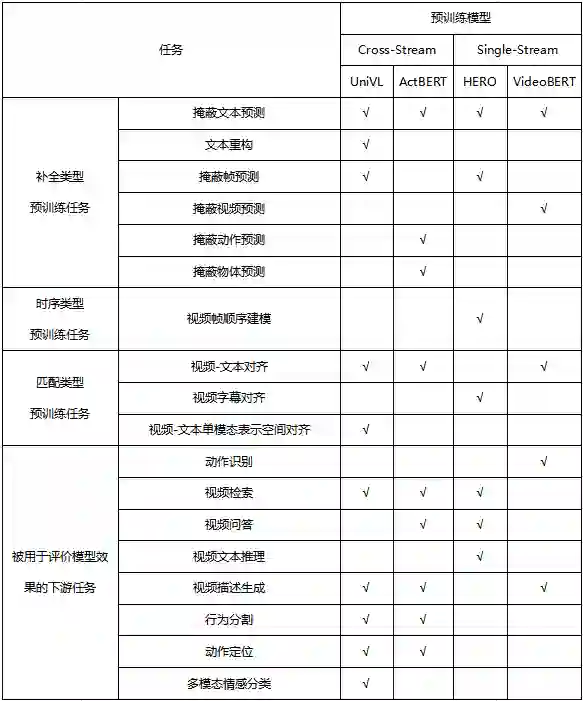
本文将目前多模态预训练模型分为两大类,图像-文本预训练模型(第3章)及视频-文本预训练模型(第4章)。对于两大类预训练模型,我们进一步将其分为Single-Stream 和Cross-Stream两类,Single-Stream将图片、文本等不同模态的输入一视同仁,输入同一个模型进行融合,而Cross-Stream将不同模态的输入分别处理之后进行交叉融合。在第3章和第4章的最后,会用表格列出各个模型所使用的预训练任务。在第5章会对目前的预训练模型的方法进行总结。
3. 图像-文本多模态预训练模型
3.1 Cross-Stream
3.1.1 ViLBERT[1]
模型细节
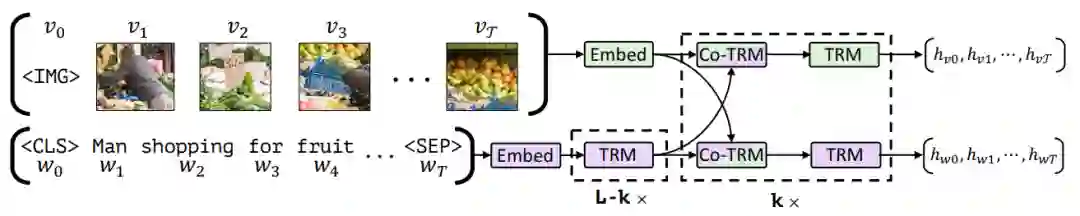
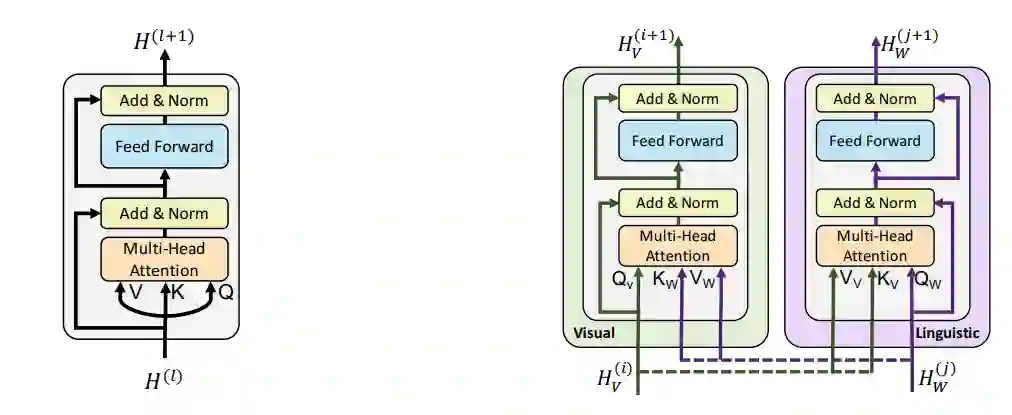
输入的文本经过文本Embedding层后被输入到文本的单模态Transformer编码器中提取上下文信息。使用预训练Faster R-CNN对于图片生成候选区域提取特征并送入图像Embedding层生成Embedding。然后将获取好的文本和图像的Embedding通过Co-attention-transformer模块进行相互交互融合,得到最后的表征。
ViLBERT模型图如图1所示,Co-attention-transformer模块如图2所示。
预训练任务
掩蔽文本预测(masked multi-modal modelling) 与BERT的设计思路一样,根据概率随机替换掉文本中部分词,使用[MASK]占位符替代,需要模型通过文本中上下文,以及对应图片中给出的信息,预测出被替换的词。
掩蔽图像预测(masked multi-modal modelling) 通过掩蔽经过Faster R-CNN提取到的预候选区域,使模型通过对应文本以及其他区域的图像预测出被遮掩区域的类别。
图片-文本对齐(multi-modal alignment) 给定构造好的图文关系对,让模型来判断文本是否是对应图片的描述,具体是使用<IMG>以及<CLS>
下游任务
作者将该模型应用到视觉问答(Visual Question Answering)、视觉常识推理(Visual Commonsense Reasoning)、指示表达定位(Grounding Referring Expressions)、图像检索(Caption-Based Image Retrieval)等下游任务上,并且取得了较好的结果。
3.1.2 LXMERT[2]
模型细节
类似于ViLBERT,对于文本和图像经过Embedding层之后被送入各自的单模态编码器,然后通过跨模态编码器进行融合。
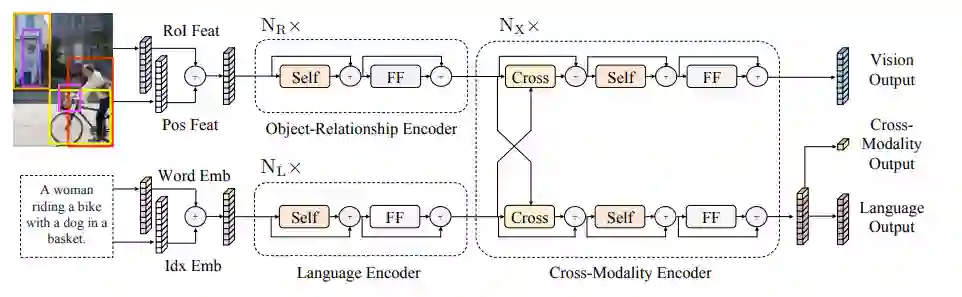
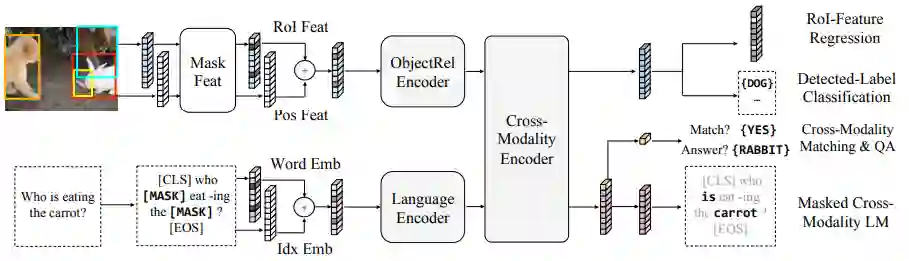
预训练任务
掩蔽文本预测(Masked Cross-Modality LM) 该任务的设置与BERT的MLM任务设置一致。作者认为除了从语言模态中的非模态词中预测被掩蔽词外,LXMERT还可利用其跨模态模型架构,从视觉模态中预测被掩蔽词,从而解决歧义问题,所以将任务命名为Masked Cross-Modality LM以强调这种差异。
掩蔽图像类别预测(Detected-Label Classification)该任务要求模型根据图像线索以及对应文本线索预测出直接预测被遮蔽ROI的目标类别。
掩码图像特征回归(RoI-Feature Regression)不同于类别预测,该任务以L2损失回归预测目标ROI特征向量。
图片-文本对齐(Cross-Modality Matching) 通过50%的概率替换图片对应的文本描述,使模型判断图片和文本描述是否是一致的。
图像问答(Image Question Answering) 作者使用了有关图像问答的任务,训练数据是关于图像的文本问题。当图像和文本问题匹配时,要求模型预测这些图像有关的文本问题的答案。
作者将该模型在多个下游任务上进行了测试,分别在视觉问答任务(Visual Question Answering)、面向现实世界视觉推理(Visual Reasoning in the Real World)等取得了很好的效果。
3.1.3 ERNIE-ViL[3]
模型细节
模型结构采用双流架构,对于图像和文本分别使用单模编码器进行编码然后使用跨模态Transformer实现两个模态的信息交融。值得一提的是该模型引入了场景图信息,通过将场景图知识融入多模态预训练中,使得模型更能精准把握图像和文本之间细粒度的对齐信息。模型图如图5所示。
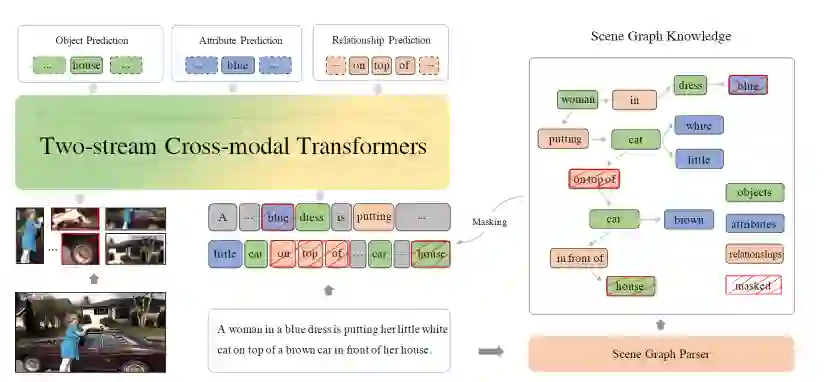

模型在预训练任务中融入了场景图(如图6所示)的信息。场景图中有目标(objects)、属性(attributes)、关系(relationships)三种类别。
预训练任务
场景图预测(Scene Graph Prediction)根据给定的一段文本解析出场景图结构,然后根据解析出的场景图设计了三个子任务,分别是目标预测(object prediction)、属性预测(attribute prediction)、关系预测(relationship prediction),通过掩蔽图像和文本中场景图解析出来的目标、属性以及关系,使用模型进行预测,以让模型学习到跨模态之间的细粒度语义对齐信息。
同时模型还使用了传统的预训练任务,分别是掩蔽文本预测(Masked Cross-Modality LM)、掩蔽图像类别预测(Detected-Label Classification),以及图片-文本对齐(Cross-Modality Matching)。
下游任务
作者在下游多个任务上进行检测都取得了比较大的提升,具体有视觉常识推理(Visual Commonsense Reasoning)、视觉问答(Visual Question Answering)、图像检索(Image Retrieval)、文本检索(Text Retrieval)、指示表达定位(Grounding Referring Expressions)。
3.2 Single-Stream
3.2.1 VL-BERT[4]
模型细节
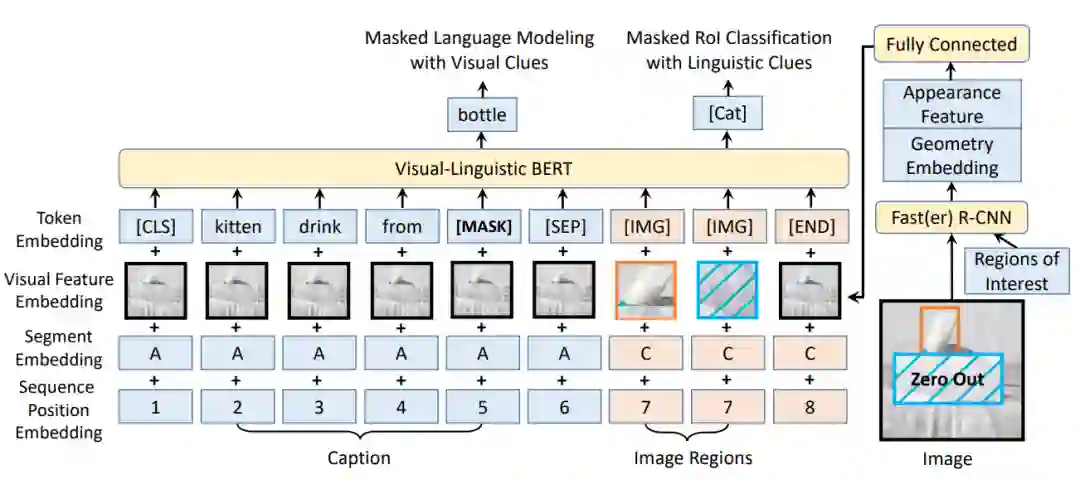
模型架构与BERT相似,如图7所示。整个模型的输入有四部分embedding。
Token embedding层:对于文本内容使用原始BERT的设定,但是添加了一个特殊符[IMG]作为图像的token。
Visual feature embedding层:这层是为了嵌入视觉信息新添加的层。该层由视觉外部特征以及视觉几何特征拼接而成,具体而言,对于非视觉部分的输入是整个图像的提取到的特征,对应于视觉部分的输入即为图像经过预训练之后的Faster R-CNN提取到的ROI区域图像的相应视觉特征。
Segment embedding层:模型定义了A、B、C三种类型的标记,为了指示输入来自于不同的来源,A、B指示来自于文本,分别指示输入的第一个句子和第二个句子,更进一步的,可以用于指示QA任务中的问题和答案;C指示来自于图像。
Position embedding层:与BERT类似,对于文本添加一个可学习的序列位置特征来表示输入文本的顺序和相对位置。对于图像,由于图像没有相对的位置概念,所以图像的ROI特征的位置特征都是相同的。
作者在视觉-语言数据集以及纯语言数据集上都进行了大规模的预训练,使用概念标题数据库(Conceptual Captions)数据集作为视觉-语言语料库,该数据集包含了大约330万张带有标题注释的图片,图片来自于互联网。但是这个数据集存在一个问题就是图像对应的标题是简短的句子,这些句子很短并且很简单,为了避免模型只关注于简单子句,作者还使用了BooksCorpus和英语维基百科数据集进行纯文本的训练。
预训练任务
掩蔽文本预测(Masked Language Model with visual Clues) 此任务与BERT中使用的Masked Language Modeling(MLM)任务非常相似。关键区别在于,在VL-BERT中包含了视觉线索,以捕获视觉和语言内容之间的依存关系。
掩蔽图像类别预测(Masked RoI Classification with Linguistic Clues) 类似于掩蔽文本预测,每个RoI图像以15%的概率被随机掩蔽,训练的任务是根据其他线索预测被掩藏的RoI的类别标签。值得一提的是为了避免由于其他元素的视觉特征的嵌入导致视觉线索的泄漏,在使用Faster R-CNN之前,需要先将被Mask的目标区域的像素置零。
下游任务
作者将模型应用于视觉常识推理(Visual Commonsense Reasoning)、视觉问答(Visual Question Answering)、引用表达式理解(Referring Expression Comprehension)任务,并且都取得了显著的效果。
3.2.2 Image-BERT[5]
模型细节
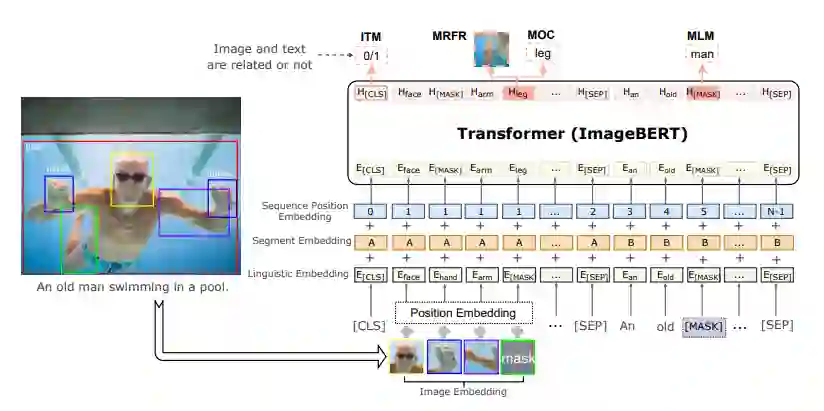
ImageBERT在图像Embedding层添加了图像位置编码,即将通过Faster R-CNN得到的物体对应的ROI区域相对于全局图的位置信息,编码为五维向量,作为位置编码添加进图像的特征表示中。
预训练任务
掩蔽文本预测(Masked Language Modeling) 此任务与BERT中使用的Masked Language Modeling(MLM)任务设定基本一致。
掩蔽图像类别预测(Masked Object Classification) 此任务是MLM任务的扩展。与语言建模类似,通过对视觉对象进行掩蔽建模,期望模型预测出被掩蔽的图像token的类别。
掩蔽图像特征回归(Masked Region Feature Regression) 该任务旨在预测被掩蔽的视觉对象的嵌入特征。通过在相应位置的输出特征向量后添加一个全连接层,以将其投影到与原始RoI对象特征相同的维度上,然后应用L2损失来进行回归。
图片-文本对齐(Image-Text Matching) 除了语言建模任务和视觉内容建模任务之外,作者还添加了图片-文本对齐任务以学习图像-文本对齐。对于每个训练样本,对每个图像随机抽取负例句子,对每个句子随机抽取负例图像以生成负例训练数据,让模型判断给定的图像文本对是否对应。
下游任务
作者在MSCOCO以及Filcker30k数据上分别测试模型在图像检索(Image Retrieval)以及文本检索(Sentence Retrieval)任务上的性能,取得了一定的提升。
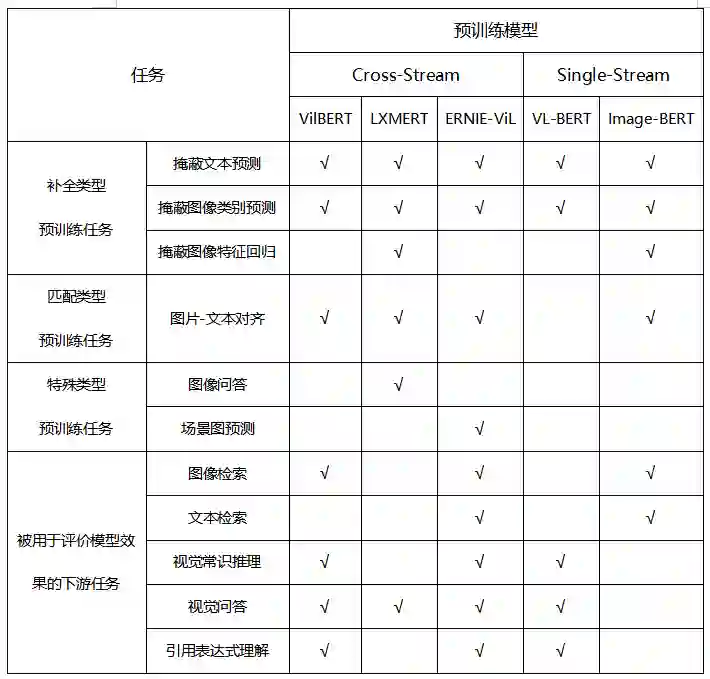
表1 图像-文本预训练模型概览表
4. 视频文本多模态预训练
4.1 Cross-Stream
4.1.1 UniVL[6]
模型细节
该模型先使用单模态编码器对文本与视频数据进行单独建模,再使用跨模态编码器对两个模态的表示进行联合编码。
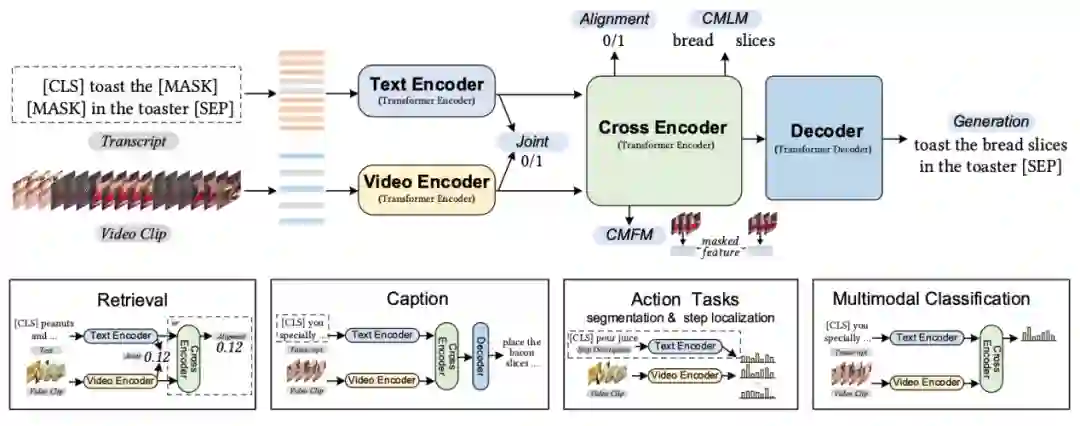
预训练任务
视频-文本单模态表示空间对齐(video-text joint) 为了利用BERT来帮助模型获得更好的视频表示,作者设计了视频-文本单模态表示空间对齐任务。该任务具体是,构造正例对(视频与对应/相近的文本)和负例对(视频与不相关的文本),希望正例对中的视频表示与文本表示更接近而负例对中的更远。其中,视频表示由视频单模态编码器得出,文本表示由文本单模态编码器得出。
条件掩蔽文本预测(conditioned masked language model) 与BERT的设计思路类似,作者设计条件掩蔽文本预测任务来训练模型。文本中的词被随机替换成占位符[MASK],然后替换后的文本与视频进行联合表示后,预测替换前的词。
掩蔽帧预测(conditioned masked frame model) 输入的视频帧被随机替换成占位符号,然后使用模型来预测被替换的视频帧。由于直接预测原始的RGB视频帧非常困难,因此作者使用对比学习的方法,希望原始视频帧与模型相应位置得到的表示相关性更高。
视频-文本对齐(video-text alignment) 视频与相应的文本之间对齐标签为1,而与其他文本对应的标签为0。使用这个对齐信息作为监督信号训练模型。
文本重构(language reconstruction) 为了使得模型能够应用到下游任务-视频描述生成上,作者设计了文本重构任务。具体采用了一个自回归解码器,其输入为处理后的文本和视频帧,输出是原始的文本。
下游任务
作者在视频检索(Text-based Video Retrieval)、视频描述生成(Multimodal Video Captioning)、行为分割(Action Segmentation)、动作定位(Action step localization),以及多模态情感分类(Multimodal Sentiment Analysis)等下游任务上进行了实验,验证了模型的有效性。
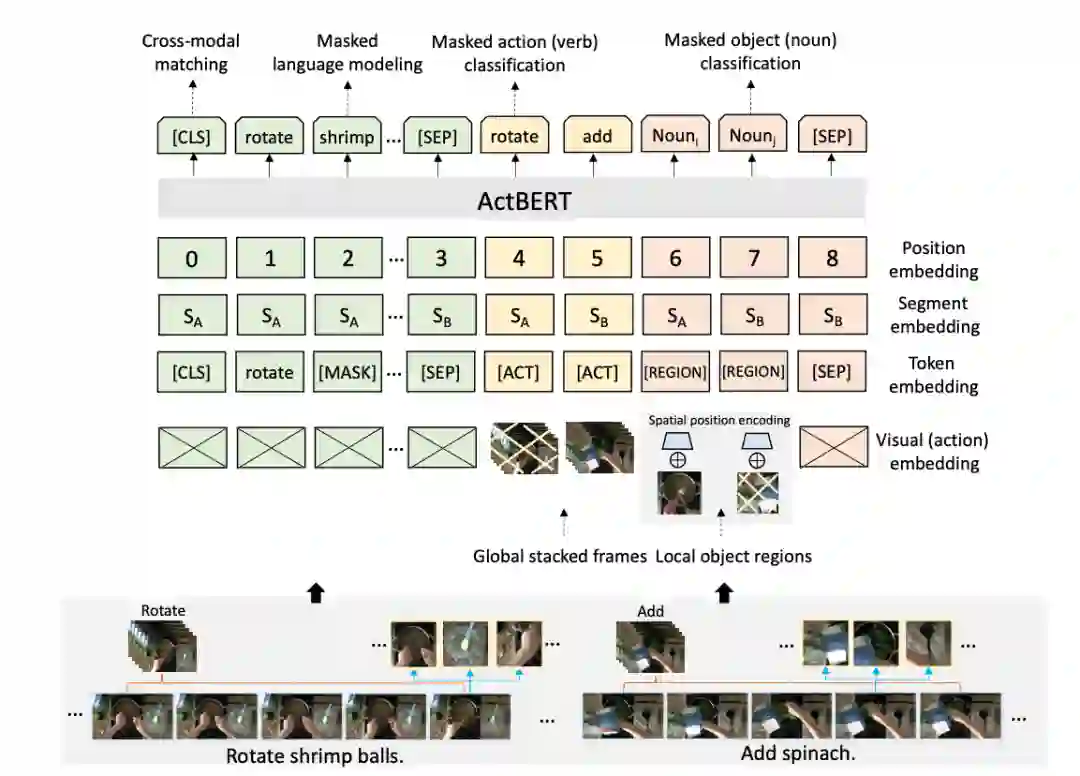
4.1.2 ActBERT[7]
模型细节
与之前不同的是本工作考虑了视频中更细粒度的信息——物体信息,引入掩蔽物体预测任务,使得模型更细粒度地捕捉图像信息。工作框图如下。
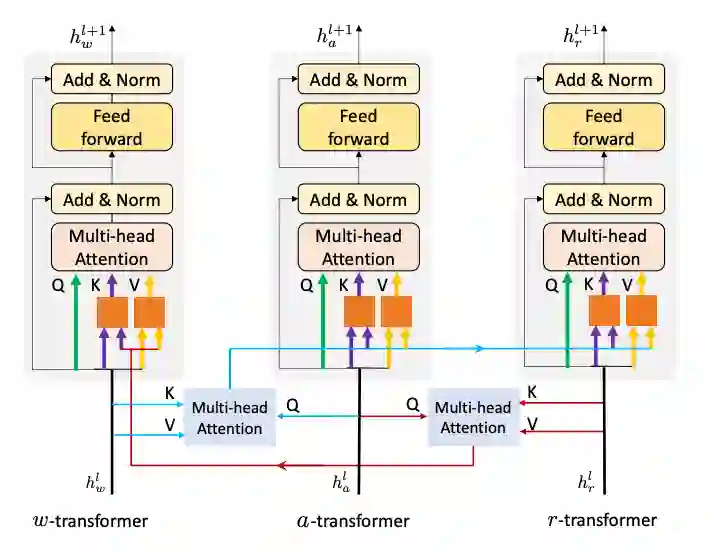
为了使得模型能够充分利用文本信息、视频中时序信息,以及视频中物体信息,该工作提出了Tangled Transformer模型,模型图如下。a-transformer模块对动作特征进行建模,r-transformer模块对物体对象特征进行建模,w-transformer模块对文本特征进行建模。三者之间的信息通过跨模态的多头注意力机制进行交互。
预训练任务
掩蔽文本预测(Masked Language Modeling with Global and Local Visual Cues)该任务设计与BERT一致,掩蔽部分词,然后将文本与动作特征以及物体特征送入模型中进行联合建模,最后使用相应位置的输出向量预测被掩蔽的词。
掩蔽动作预测(Masked Action Classification) 随机将输入的动作表示向量进行掩蔽,然后强迫模型通过其他信息如文本信息和物体信息来预测出动作的标签如add等。
掩蔽物体预测(Masked Object Classification) 随机将物体特征向量进行掩蔽,然后让模型预测出该位置上物体的分布概率。希望预测出来的概率与Faster R-CNN对该区域的预测概率相近。
视频-文本对齐(Cross-modal matching) 使用[CLS]的表示去预测文本与视频是否匹配,负例是通过随机从其他数据中进行采样得到。
下游任务
作者将该模型应用到视频检索(Text-video clip retrieval)、视频描述生成(Video Captioning)、行为分割(Action Segmentation)、视频问答(Video question answering)、动作定位(Action step localization)等下游任务上。
4.2 Single-Stream
4.2.1 VideoBERT[8]
模型细节
该工作使用Transformer对文本和视频统一进行建模。
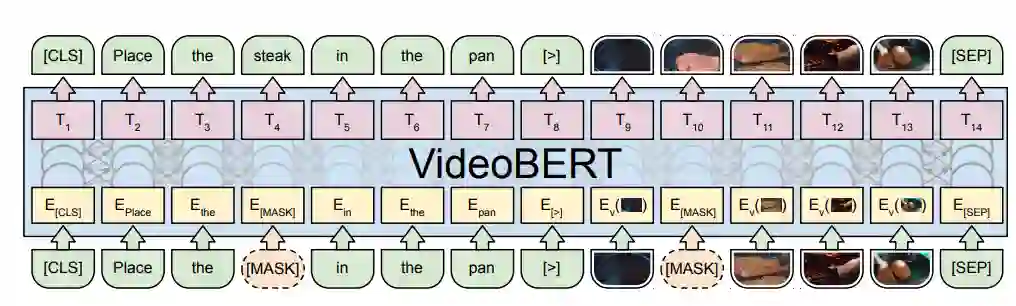
预训练任务
掩蔽文本预测(text-only mask-completion) 与BERT的设计思路一样,文本中的词被随机替换成占位符[MASK],然后替换后的文本与视频进行联合表示后,预测替换前的词。
掩蔽视频预测(video-only mask-completion) 为了使得模型适配于BERT架构,作者建立“视觉词表”将输入视频量化。具体是,将所有视频切成片段,使用S3D模型对片段进行表示。然后使用聚类算法对表示进行聚类,共得到20736个聚类中心,这样每个视频片段就可以由聚类中心来表示,即可将视频片段用离散的聚类中心编号进行表示。输入的“视觉词”被随机替换成占位符号,然后使用模型来预测被替换的“视觉词”。
视频-文本对齐(linguistic-visual alignment) 使用[CLS]表示预测视频和文本是否在时序上对齐。
下游任务
作者在动作识别、视频描述生成等下游任务上进行了实验。此外,该模型还可以用于给定文本生成视频以及给定视频上文生成视频下文等任务。
4.2.2 HERO[9]
模型细节
该篇工作为了捕捉视频的时序信息以及文本与视频的对应信息设计了两个新的预训练任务, 视频字幕对齐(Video Subtitle Matching)以及视频帧顺序建模(Frame Order Modeling)。整体工作框架如下。(注:每个句子的文本以及对应的视频帧通过Cross-Modal Transformer得到经过交互后的表示(棕色为文本表示),然后将获得的视频帧的表示送入到后续模块中。)
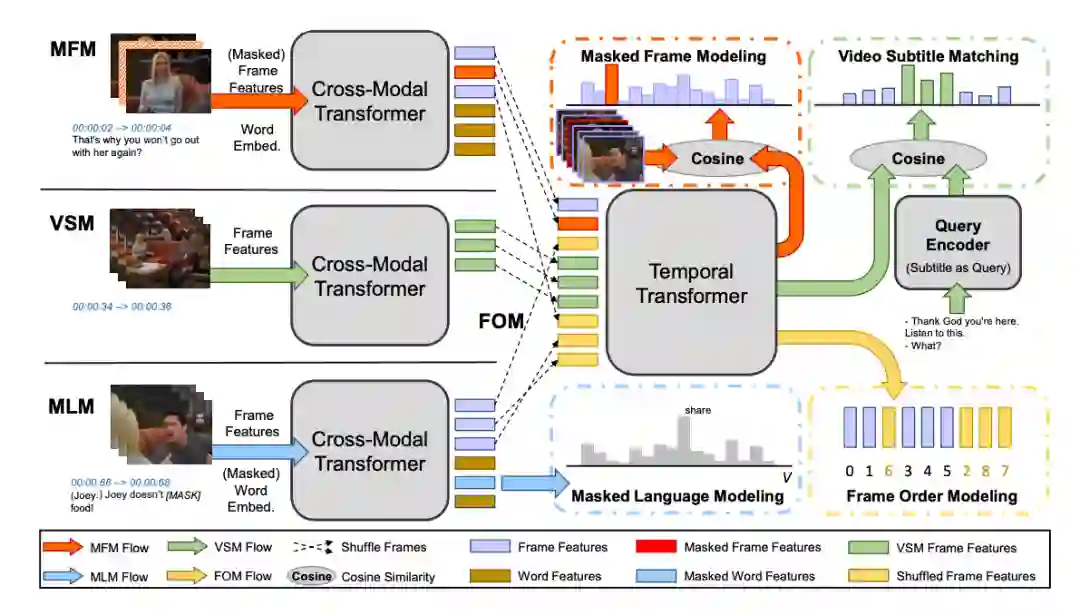
预训练任务
掩蔽文本预测(Masked Language Modeling) 该任务设计与BERT一致,掩蔽部分词,然后将文本与视频帧特征送入模型中进行联合建模,最后使用相应位置的输入向量预测被掩蔽的词。
掩蔽帧预测(Masked Frame Modeling) 该任务设计与BERT类似,掩蔽部分帧向量,然后将文本与视频帧特征送入模型中进行联合建模,最后使用相应位置的输出向量预测被掩蔽的帧。实现帧的预测可使用两种方式,一种是预测出帧向量,然后与标准帧向量计算损失。第二种是使用对比学习的方法,被掩蔽位置对应的输出向量应与被掩蔽的帧向量更为相关。
视频字幕对齐(Video Subtitle Matching) 作者为了更好的建模视频与文本,提出了视频字幕对齐(Video Subtitle Matching)任务。该任务包含两个任务目标,第一个是从一个完整视频对应的字幕中随机采样出一个句子,希望模型能够找出该句子在视频中对应的起始位置。第二个是从一个完整视频对应的字幕中随机采样出一个句子,希望该句子与该视频之间相关性更强而与其他视频相关性更弱。
视频帧顺序建模(Frame Order Modeling) 为了更好的建模视频的时序性,随机打乱部分输入帧的顺序,然后利用模型预测出来每一帧对应的实际位置。具体实践时将其建模成一个分类任务,类别数为输入长度为N。
下游任务
作者在视频检索(video-subtitle moment retrieval)、视频问答(Video question answering),以及视频文本推理(video-and-language inference)等下游任务上验证了模型的有效性。
表2 视频-文本预训练模型概览表
5. 总结
本文简单梳理了多模态图像-文本预训练模型以及多模态视频-文本预训练模型,简单介绍了相关预训练模型架构,设计的预训练任务,以及衡量模型性能的下游任务。
通过对多模态预训练任务的梳理,我们可以发现,现有预训练任务主要有两大类,一类是主要针对单个模态数据设计的,如掩蔽文本预测、掩蔽图像预测、掩蔽帧预测。其中掩蔽文本预测仍然沿用BERT的设计,掩蔽图像预测和掩蔽帧预测一般都不会直接预测原始的物体对象/帧图像,而是预测特征。由于视频具有时序性,有些模型还设计了视频帧顺序建模任务。该类任务可以使用多模态数据,也可只使用单模态数据进行训练。使用多模态数据时,模型预测时不仅可以使用该模态内部的信息,还可以使用其他模态的信息。第二类主要是针对多模态数据而设计的。该类任务通过挖掘不同模态数据中的对应关系,设计预训练目标,如视频-文本对齐、图片-文本对齐等。对于视频,还有研究者提出视频字幕对齐任务,来让模型捕捉两模态信息之间的关联。
目前的多模态预训练模型相关工作已经取得了一定的进展,在多个下游任务上有了不俗的表现。未来的工作可能从以下几个方向取得进一步的进展,第一是单模态下游任务上能否取得提升。现在大部分多模态预训练模型都是在多模态的下游任务上进行测试,少有工作在单模态任务如自然语言处理任务与单模态预训练模型如RoBERTa进行全面的比较。如果认为模型在多模态数据上通过预训练能够更加充分的理解语义,那么直觉上看多模态预训练模型与单模态模型在相近的实验设置下(如语料规模相似)应当取得更好的成绩。第二是更精细的挖掘不同模态数据间的相关信息并设计更巧妙的预训练任务。比如挖掘图像-文本之间,名词与物体对象之间的相关性,使得模型建立词语与物体对象之间的相关性。第三是设计更高效的模型架构以及挖掘更大规模的高质量多模态数据。
参考资料
Lu J, Batra D, Parikh D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[J]. arXiv preprint arXiv:1908.02265, 2019.
[2]Tan H, Bansal M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 5103-5114.
[3]Yu F, Tang J, Yin W, et al. Ernie-vil: Knowledge enhanced vision-language representations through scene graph[J]. arXiv preprint arXiv:2006.16934, 2020.
[4]Su W, Zhu X, Cao Y, et al. Vl-bert: Pre-training of generic visual-linguistic representations[J]. arXiv preprint arXiv:1908.08530, 2019.
[5]Qi D, Su L, Song J, et al. Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data[J]. arXiv preprint arXiv:2001.07966, 2020.
[6]Luo H, Ji L, Shi B, et al. Univilm: A unified video and language pre-training model for multimodal understanding and generation[J]. arXiv preprint arXiv:2002.06353, 2020.
[7]Zhu L, Yang Y. Actbert: Learning global-local video-text representations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 8746-8755.
[8]Sun C, Myers A, Vondrick C, et al. Videobert: A joint model for video and language representation learning[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 7464-7473.
[9]Li L, Chen Y C, Cheng Y, et al. Hero: Hierarchical encoder for video+ language omni-representation pre-training[J]. arXiv preprint arXiv:2005.00200, 2020.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MPTM” 就可以获取《多模态预训练模型简述》相关论文专知下载链接






