多 Agent 强化学习综述

这是来自我们组同事谢思发同学 (微博:https://weibo.com/DMRookie)的文章。谢思发同学硕士毕业于厦门大学,于 2016 年加入腾讯互动娱乐数据挖掘团队,从事用户画像、知识图谱和社交网络方面的工作。
最近在大神们的带领下学习强化学习,啃了一篇多Agent强化学习的综述论文[1],这里简单做下笔记。
1. 背景介绍
多智能体系统由一群有自主性的,可互相交互的实体组成,它们共享一个相同的环境,通过感知器感知环境并通过执行器采取行动。多智能体在现实生活中已有应用,如机器人战队,分布式控制和资源管理。虽然可以预先设定多智能体的行为表现,但因为环境太过复杂,有时甚至会随时间而变化。所以很难提前设计一个良好的行为,或者随时间推移,先前良好的行为也会慢慢变差。通常需要在线学习新的行为,才能提高智能体或整个系统的性能。
在单Agent的强化学习中,Agent在感知完环境的状态后,采取了一个动作,使得环境转移到下一个状态,并得到一个评价这次动作好坏的反馈。Agent的学习目标就是最大化累计反馈。强化学习的反馈比有监督学习信息量少,但多于无监督学习。通过一些简化或泛化,单Agent的强化学习算法也可以运用到多Agent中。
1.1. 强化学习
首先回顾单Agent的强化学习算法,介绍单Agent强化学习任务以及求解方法。然后过渡到多Agent强化学习(Multi-Agent Reinforcement Learning,MARL)的定义。本次的讨论主要限制在状态空间是离散的,并且动作空间有限的强化学习场景中,大部分的MARL算法也是在这个设定下提出的。
单Agent的强化学习可以用马尔科夫决策过程表征,其定义如下:
定义1. 有限马尔科夫决策过程是一个4元组 。
其中 是Agent的状态空间,
是动作空间,
是状态转移概率函数,
是奖励函数。
Agent在状态 下,采取了动作
,根据状态转移概率值
转移到了状态
,获得即时回报
。对于确定性系统,概率转移函数变成
.,此时即时回报只跟当前状态和当前采取的动作有关,即
,
。Agent在任一个状态下如何选择动作的决策过程,称为Agent的策略,用h表示。如果策略不随时间而变化,就称策略是稳定的(stationary)。Agent在状态X下,根据策略h,执行后续的动作,所能获得的期望回报如下:
其中 是折扣因子,保证越后面的回报,对回报函数的影响越小,刻画了未来回报的不确定性,同时也使得回报函数是有界的。强化学习的目标就是寻找一个最优策略h,使得Agent在任一状态下的期望回报都是最大的。期望回报涉及到后面一系列动作的回报值,而Agent每次只能获得当前步的即时回报,不好直接求解。可以转换成计算状态动作值函数(Q-function),它给出,在策略h下,每个状态动作对的期望回报:
最优Q函数定义为 。
它满足贝尔曼最优等式:
等式表明在状态X下采取动作U的最优回报值是期望的即时回报,加上下一状态的最优(折扣)回报值。当 计算好后,最优策略就是在每一状态下,选择回报最大的动作。
在实际求解的过程中,可以采用一种迭代近似的方法求解,即Q-learning:
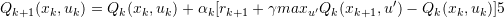
算法先随机初始化 值,然后不停地迭代更新,使
最终收敛于
。因为最开始的Q函数是随机的,不准确,而且Q-learning如果要收敛,还要求每个状态动作对都走过,所以需要有一个探索和贪婪的的平衡过程。在每个状态下,以
的概率随机选择一个动作,以
的概率选择最优动作。还可以使用玻尔兹曼探索过程(Boltzmann exploration procedure),Agent在状态
下依概率
选择动作
,其中
为:
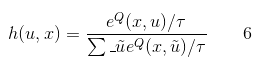
是超参数,当
时,Agent倾向选择最优动作,当
时,Agent则是随机选择动作。
马尔科夫决策过程泛化到多Agent情形则是随机博弈,定义如下:
定义2:随机博弈是一个多元组 ,n是Agent的个数,
是状态集合,
是
的动作空间。所有Agent的动作组成联合动作空间集
。
是状态转移函数,
是每个Agent的回报函数。
定义中概率转移和每个Agent的回报函数都是基于联合动作空间计算的。此外每个Agent的策略是 ,所有Agent的策略组合成联合策略
。每个Agent在状态x下的期望回报为
Q函数为
按照状态数目的不同,随机博弈可以分为静态博弈和动态博弈。静态博弈对应系统中只有一个状态的情形。多于一个状态的情形则为动态博弈。将一个静态博弈重复进行多次,即为重复博弈。此外还可以分为完全合作,完全竞争和混合随机博弈。在完全合作的随机博弈中,所有Agent的回报函数都是一样的,即 ,从而有
。在完全竞争的随机博弈中,如果只有两个Agent,则
。而混合的随机博弈,则包括竞争和合作关系。
1.2 机会和挑战
多Agent强化学习较单Agent存在一定优势:不同Agent通过共享经验,可以更快更好的完成任务。比如有经验的Agent可以当老师,指导无经验的Agent;如果任务可以拆分不同子任务时,不同Agent可以并行执行子任务,以此加速计算;当系统中有Agent失效时,其他Agent可替代执行任务,从而使整个系统更加鲁棒;而且可方便地加入新的Agent,扩展性也更好。
但同时也面临着一些挑战:首先维度灾难问题更加严重,之前状态转移概率函数和回报函数都是在联合动作空间下计算的。随着状态和动作的增加,计算复杂度呈指数增长。其次学习目标不好定义,Agent的回报跟其他Agent的行为相关的,没办法单独最大化某个Agent的回报。不稳定性也是MARL的一个问题,Agent是同时在学习的,每个Agent都是面临着一个不停变化的环境,最好的策略可能会随着其他Agent策略的改变而改变。最后,探索和贪婪过程会更复杂,在多Agent下,探索不仅是为了获取环境的信息,还包括其他Agent的信息,以此来适应其他Agent的行为。但是又不能过度探索,不然会打破其他Agent的平衡。
基于上述挑战,在MARL中,主要关注两方面学习目标,稳定性(stability)和适应性(adaptation)。稳定性指Agent的策略会收敛至固定,而适应性确保性能不会因为其他Agent改变策略而下降。收敛至均衡态是稳定性的基本要求,这要求所有Agent的策略收敛至协调平衡状态,最常用的是纳什均衡。适应性体现在理性或无悔两个准则上。理性指出,当其他Agent稳定时,Agent会收敛于最优反馈。无悔是说最终收敛的策略,其回报要不差于任何其他的策略。
2. MARL
可以从不同维度来分类MARL算法,首先从任务的类型来分的话,MARL算法可以分成如下三大类:
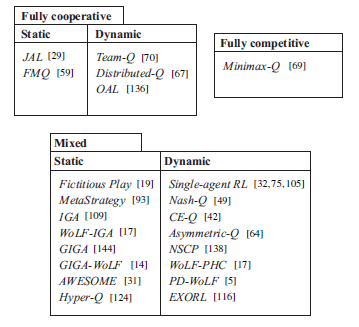
也可以从算法侧重的学习目标来分,关注稳定性的算法通常对其他Agent是独立无感知的,而侧重适应性的算法都需要能感知其他Agent,它们会为对手建模,来追踪对手的策略。
2.1 完全合作
首先看完全合作下的MARL算法,如果在随机博弈中,存在一个中心控制者,可以控制其他Agent的行动。那么就能求得最佳的联合动作值,随机博弈就退化成马尔科夫决策过程,并且可以用Q-learning算法求解。
但是大部分系统是不存在中心控制者,那么是否可以假定其他Agent都是选择当前状态下最优的动作,在这种假定下,再选择对自己最优的动作,即
但在特定状态下,一些组合动作才可能取得最优结果(此时Agent不一定都是取自己最优的动作)。这时就需要协同机制,来协调Agent的动作。在下图中,有两个Agent需要一起通过障碍物,并且保持之间一格的距离。如果两个同时往左或往右,那么有机会通过障碍物,回报值是10。如果Agent1往左,Agent2往右,虽然有机会通过障碍物,但破坏了一格距离的限定,这时回报值是0。其他情况下,都会发送碰撞,回报值都是负的。所以最优动作要么同时往左,要么同时往右。这时就需要协同机制了,否则Agent1会认为大家同时往左,而Agent2却选择同时往右。
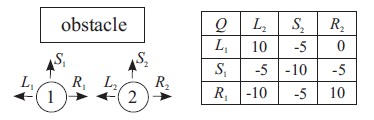
上面的例子,因为存在两个最优联合动作,所以需要互相协调。但如果在Agent2右边又有一个障碍物时,这时最优联合动作是同时往左,也就不需要协同机制了。Team Q-learning[2]是一种不需要协同机制的算法,它指出在最优联合动作是唯一情况下,可以采用(10)式贪婪公式求解。
在没有负回报的确定性(deterministic)问题中,可以用分布式(distributed)Q-learning[3]算法求解,这也不需要协调机制。每个Agent保存一个本地的策略 和只取决于自身动作的本地的Q函数
。Q函数的更新公式如下:
本地的策略更新公式如下:
此外有一类间接协调算法,每个Agent通过为其他Agent建模,或统计不同动作的历史的回报值,来选择可能获得更高回报的动作。Joint Action Learners(JAL)[4]算法中,每个Agent会为其他Agent建模:
是Agaent i 对Agent j的建模,
统计了Agaent i 观察到的Agaent j 采取动作
的次数。结合这些模型,JAL提出了几个启发式的方法,来提高状态动作对的回报。
Frequency Maximum Q-value(FMQ)[5]算法,统计每个动作取得最优回报的频率。然后用这个值修改公式6中的Q函数。
其中 是采取动作
取得的最大回报值,
是取得最大值的次数,
是采取动作
的次数。经过修改后,Agent就会倾向选择以往取得高回报的动作。简单理解,假设在某次动作组合下,所有Agent取得了一个高回报值(完全合作下Agent的回报是一样的),那么每个Agent在后面就会倾向选择在这个动作组合下各自采取的动作。逐渐地就会增加这个最优动作组合对出现的概率。
最后是基于社会公约(social conventions),角色,互相交流[6]等显式的协调机制。在社会公约中,会规定每个Agent的先后顺序以及动作选择的先后顺序,这些信息是共享周知的。例如在上面那两个Agent穿越障碍物的例子中,规定Agent 1优先于Agent 2,而且动作优先选择L。那么Agent 1在行动时,查Q表得知往左或往右都能取得最高收益,根据社会公约,采取L1。轮到Agent 2的时候,根据社会公约推理可知Agent 1是选择L1的,这时候Agent 2 就会选择L2,从而实现最大收益。如果可以互相交流,那么只需要规定每个Agent的先后顺序。同样的例子里,Agent 1先选L1或R1。然后把选择的动作告诉Agent 2,Agent 2再选择相对应的动作。
2.2 完全竞争
在完全竞争的随机博弈中,可以应用最小最大化(minimax)原则:在假定对手会采取使自己收益最小化的动作的情况下,采取使自己收益最大的动作(即以最坏的恶意揣度对手)。minimax-Q算法[7,8]基于最小最大化原则,使用下式来更新Agent 1的策略函数和Q函数。
其中 是Agent 1的最小最大值:
minmax-Q算法是对手独立的,不管对手如何选择,总能取得不差于minmax函数回报值。但如果对手不是采取最优策略(即使自己的收益最小化),而且能对对手建模,那么就可以取得更优的动作。一种为对手建模的方式是对公式12进行扩展:
其中 是Agent i 观察到Agent j 在状态
下采取动作
的次数。
在下面的例子中,Agent 1 需要到达X标志的位置,同时避免被Agent 2 捕抓到。Agent 2 的目标就是抓到Agent 1 ,两个Agent只能往左或往右移动。右侧是Agent 1 的Q表,两个同时往左不产生任何收益,同时往右,则Agent 1达成目标且没被抓到,收益10。Agent 1 往右而Agent 2 往左,则被抓到,收益-10。Agent 1 往左,Agent 2 往右,虽然没达到指定位置,但远离Agent 2 所以收益1。Agent 2 的Q表是Agent 1 的Q表取负。
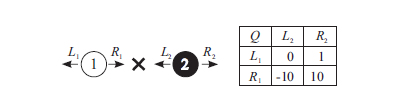
根据minimax原则,Agent 1应该选择往左移动。因为往左的最小期望收益是0,往右的最小期望收益是-10。对于Agent 2,其最优策略是往左移动保护目标位置。但如果Agent 2 不是采取最优策略而是往右走,并且Agent 1 通过建模能预测到,那么Agent 1 就可以往右移动,达成目标。
2.3 混合任务
在混合任务中,大部分算法是针对静态任务的,而且主要是关注适应性。其中最简单的是直接应用单Agent算法。即每个Agent的Q函数都只跟自己相关,使用公式5进行更新,对对手无感知。[9]指出在特定的博弈中,单Agent算法是可以收敛至协调均衡的。但是在其他情况下,会存在不稳定的循环震荡。
Win-or-Learn-Fast Policy Hill-Climbing(WoLF-PHC)[10]是一类启发式算法,根据4式来更新Q函数,并根据下面的式子来更新策略函数。

在WoLF-PHC算法中,定义了两种策略,即当前策略 和平均策略
。当前策略是一种概率分布函数,初始值为
。这个概率分布函数当Agent选择动作
时进行更新,更新方法是:对于Q函数来说,最好的动作即
,则增加概率,其他动作则降低概率。WoLF-PHC会不断更新平均策略,并和当前策略进行比较:如果当前策略平均奖励值大于平均策略的奖励值,即
,则认为Agent是“wining”的,此时平均策略将采用
速率来慢慢更新策略,否则,认为当前Agent是“losing”的,用比较大的
来更快的自适应学习[11]。此外还有更具体的算法,能力有限,看不是很懂,就不翻译了,有兴趣的可以查原文。
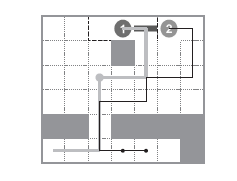
3. 多Agent物体搬运
最后举一个多Agent合作搬运物体的例子,有两个Agent1和2,需要先通过下方的障碍口,然后一个Agent抓物体的一边,避过上方的障碍物,将物体搬到home base位置。这里先用两个坐标值,来标志Agent的空间位置。 ,用一个变量来记录Agent抓物体的状态
。完整的状态空间是
。动作空间
。回报函数是如果抓住物体得一分,物体搬到指定位置得10分,其他情况不得分。
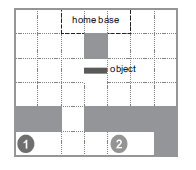
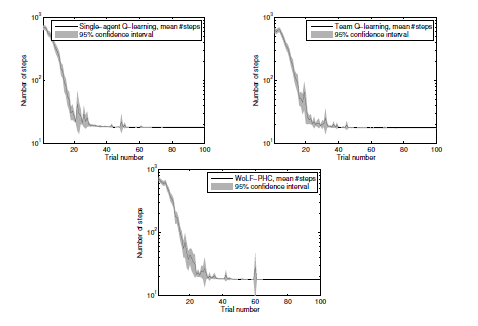
这里选用三个算法来解决这个问题:单Agent算法,team Q-learning以及WoLF-PHC[10]。设定折扣因子 , 学习率
, 贪婪率
,并随实验轮数递减。下图是实验结果,横轴是实验轮数,纵轴是搬到指定位置花费的步数。可以看到三个算法都收敛得很快,基本20-30轮就稳定收敛。而且单Agent的效果要稍好于其他两个算法,虽然它对另外一个Agent是无感知的。三种算法都没有用通信机制,却实现了一种隐性的协调:偶然学习到一条足够好的路线,然后逐渐忽略其他的路线。
下图是team Q-learning算法得到最优路线(另外两个算法得到的路线类似),Agent 1先通过下方的障碍口,抓住物体左侧,然后原地等待。Agent 2 通过障碍口,抓住物体右侧,然后一起越过上方障碍物,到达目的地。
4. 总结
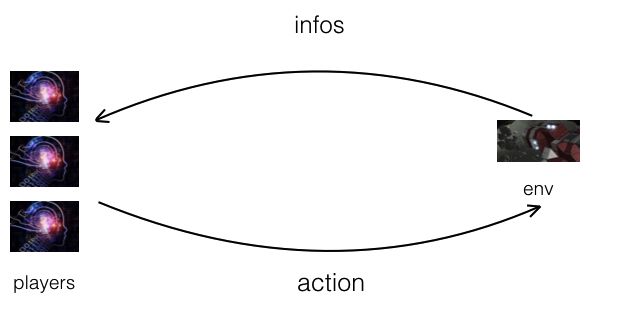
多智能体系统由一群有自主性的,可互相交互的实体组成,它们共享一个相同的环境,通过感知器感知环境并通过执行器采取行动。多智能体在现实生活中已有应用,如机器人战队,分布式控制和资源管理。虽然可以预先设定多智能体的行为表现,但因为环境太过复杂,有时甚至会随时间而变化。所以很难提前设计一个良好的行为,或者随时间推移,先前良好的行为也会慢慢变差。通常需要在线学习新的行为,才能提高智能体或整个系统的性能。目前我们正在利用非完美信息博弈工具集 RoomAI 开发不同棋牌游戏的 AI 算法,希望多 Agent 强化学习能够带来一些思考和方法。RoomAI 是非完美信息博弈工具集。在 RoomAI 中,选手获得游戏环境给出的信息,当前选手选择合适的动作,游戏环境根据该动作推进游戏逻辑;重复上述过程,直到分出胜负;整个过程如下所示。
欢迎大家 star RoomAI (https://github.com/roomai/RoomAI)。
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



