5 月 24 日,在机器之心举办的「决策智能产业应用」在线圆桌论坛上,阿里巴巴达摩院决策智能实验室的杨超发表了主题演讲《Safe RL 介绍及在电网调度中的应用》。
机器之心对杨超的演讲内容进行了不改变原意的整理。感兴趣的小伙伴可以
点击阅读原文
查看回顾视频。
![]()
大家好,我是来自阿里巴巴达摩院决策智能实验室的杨超,今天主要分享一下 Safe RL,也就是安全强化学习的内容,及其在电网调度中的应用。
我今天的分享主要分为三部分:第一部分简单科普一下深度强化学习和电网调度;第二部分介绍一些安全强化学习的方法,及其在电网调度上的应用或和改进;第三部分简单介绍一下深度强化聚焦和强化学习。
![]()
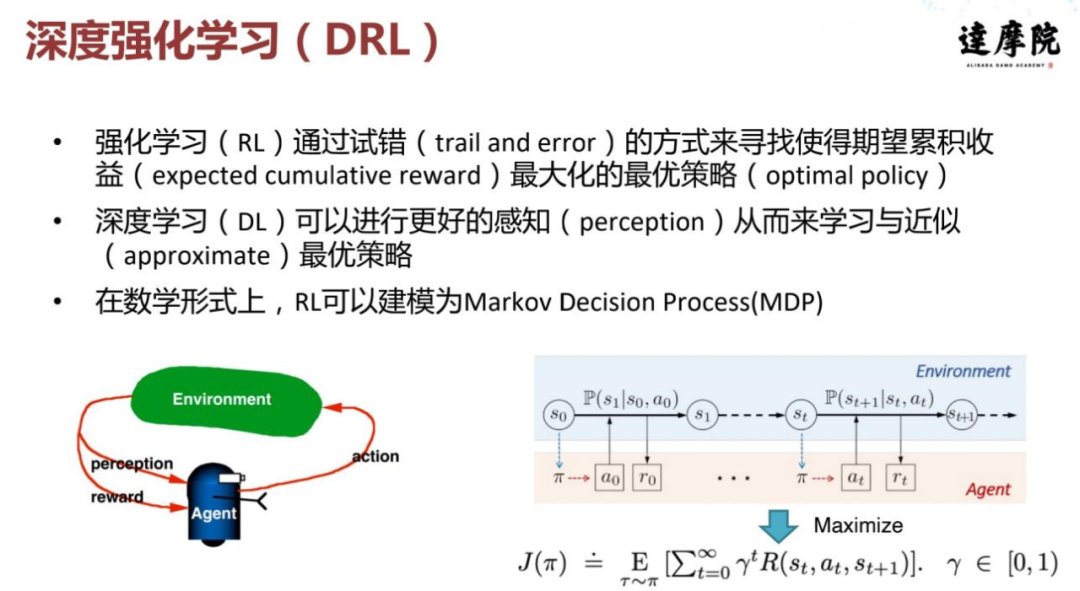
强化学习本质上是模仿人类去学习和改进的学习方式,需要跟环境不断交互,然后通过一种试错的方式来寻找最优策略。最优策略旨在最大化长期或累计收益。我们知道深度学习在感知领域做得非常好,因此深度学习也被拿来加持强化学习,帮助强化学习学到一个更好的最优策略。
![]()
在数学形式上,强化学习可以建模为马尔可夫决策过程。正如上图右下角所展示的,强化学习在每次到了一个 state 之后,产生一些 action 或接受环境所给的 word,并不断重复这个过程。强化学习起初是在游戏领域和围棋领域大放异彩,然后在 2016 年的时候 AlphaGo 将监督学习和强化学习联合起来,并结合蒙特卡罗树搜索,击败了人类顶尖围棋选手。
![]()
在工业落地方面,我选了两个国外的例子,一个是 Google 数据中心的冷却系统使用一种 Model-based RL 系统来控制温度,最终会比产品 PID 控制器的效率更高一些。目前谷歌宣称其冷却系统已经完全由 AI 自主控制。第二个例子是 MSRA 航运路径规划,它采用的是一种称为竞争合作的多智能体学习方法,并声称每年为其航运节省近千万美元的运营成本。
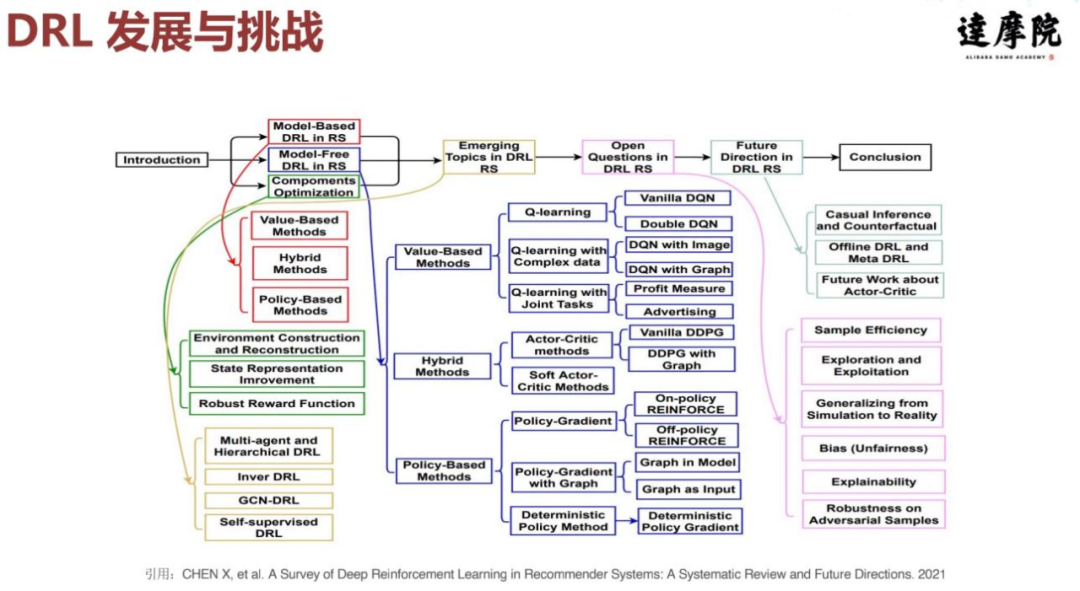
下面我再来说一下 DRL 系统的发展和挑战,下图是一个其他作者总结的图。我们可以发现强化学习主要是基于 AC 架构的算法,而强化学习的很多问题还是开放性问题,或者说还存在一些挑战,包括学习成本高、学习效率差。另一方面,强化学习要不断去探索设计新算法,并且很多强化学习算法是在仿真环境中改进的,算法成本确实非常高。
![]()
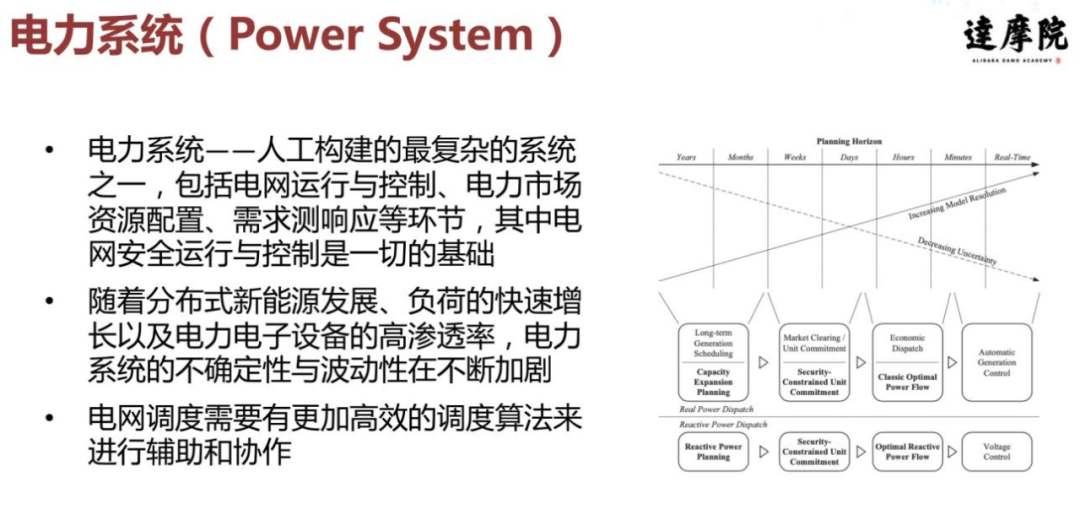
这就存在诸多挑战,其中一个挑战是安全性,一旦强化学习要落地到一些工业场景,安全性就是一个非常重要的问题。在具体讲安全强化学习之前,我先简单介绍一下电力系统,电力系统可以说是目前人工构建的最复杂系统之一,它主要的功能包括电网的运行与控制,电力市场的资源配置以及需求侧的响应等等,其中电网的安全运行与控制是一切的基础。近几年随着国家战略和新能源的发展,以及负荷的快速增长,一些电力电子设备加入到电网中,电力系统的不确定性和波动性在不断加剧,对于整个电力系统和电网调度来说,需要有一些更加高效的算法做出辅助决策。右边这个图展示的就是一个电网在不同时间尺度的不同控制方式。
![]()
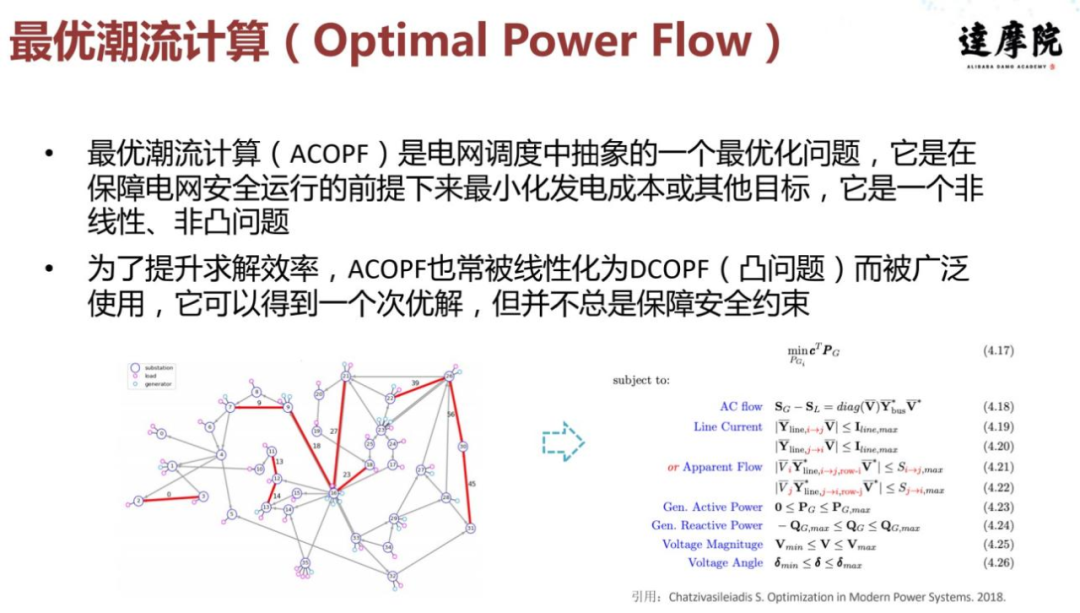
长期来看,电力系统有一些长期的规划,比如电力的出清和调度策略的制定。到了日中的话,然后他会去做一些经济调度的内容一些操作。在整个电网调度中,一个比较基础也比较关键的问题是「最优潮流」,它是电网调度中抽象出的最优化问题,旨在保障电网安全运行的前提下最强化发电行业的目标。最优化问题本身是一个非线性、非凸问题。
![]()
电网本身可以看成是一个网络的结构,其中包含点和边的概念,一些点代表变电站、电厂或发电机组,另外一些点代表用电户,电网中的边有安全的含义。因此我们一般把这个问题抽象成 ACOPF 问题,大概如右下角所展示的数学模型,这里面有一个所谓的「潮流」的概念,本身是一个非线性的方程组,最优潮流一般来说求解效率可能会相对稍慢。在电力领域,为了提升求解效率,通常我们会把这个问题做一些近似或者简化。
第一种简化方式是把它线性化,线性化后的问题在电力领域里也是被广泛使用的,他可以求得一个解,但是由于做过近似,因此安全性并不是完全能够保障安全,这就又回到安全强化学习的问题。我们希望通过强化学习的方式去应对,或者以更加高效的方式去做电网调度。
安全强化学习的概念,是指我们不仅要在强化学习的基础上,去找到一个使得累计收益最大的最优策略,同时还要满足一些系统性的性能指标或满足安全约束,一般可以建模为 constraint 的 Mark decision process 过程,如下图右所示。
其中,我们一般会把安全约束或通用性约束写成期望收益或累计期望收益的形式。相当于这里面我们会定义每一次的状态转移、每一次进行 action、每一个 step,最后我们会有一个 cost 函数来刻画安全因素是否得到满足。通常来讲的话一般也会把它建模成一个累计期望的形式。
这里我列举了 Safe RL 的一些方法,大概有 5 类方法:
![]()
第一种方法罚函数法通常也可以被称为 Reward shaping 或 Regularization,也是所谓的正则化方法。通常来说这种方法会将约束的违反程度加入到优化目标中,从而构建无约束的优化问题,
如下图所示。
由于惩罚系数是提前固定的,因此该方法最终效果对系数的选择很敏感。
![]()
如上图右下角的另一个实验所示,我们可以看到当我们采用一些不同的技术,例如采用的惩罚系数比较大,约束不再违法,但是获得的长期的收益就比较低,如图中橙色曲线所示,而绿色曲线则不太可能会满足安全约束,蓝色的线是折中方案,如果我们可以将一些经验知识进行抽象,并把它们直接作用到我们类似的学习中,则可以取得一些不错的效果。
我们当时在国网比赛中对一个经典的 DDPG 进行了改造,可以看到下图右红色曲线的明显改进,无论是收敛速度还是获得收益,它的效果都会更好一些。当然需要你对策略做一些精巧的设计。
![]()
第二类方法原始 - 对偶法本质上是通过拉格朗日松弛(
lagrangian relaxation)技术,原问题(primal problem)
被转换为对偶问题(dual problem),而对偶问题是原问题的上界,因此最小化对偶问题的解可以逼近原问题的最优解。
![]()
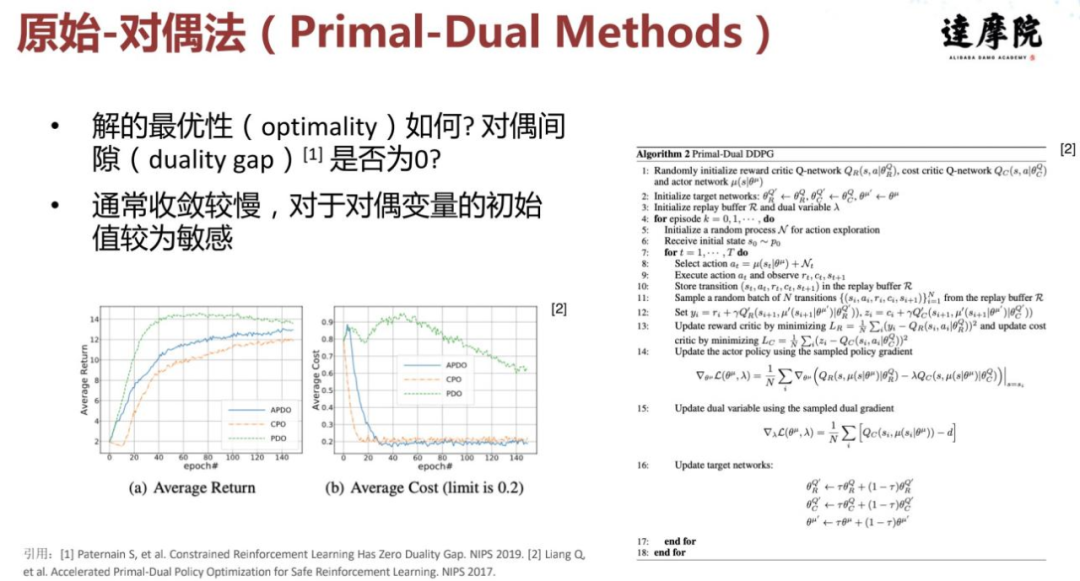
对偶问题一般存在一个二层的优化,所以他会去去更新两种变量,一种变量是原问题的变量,另一个变量就是对偶变量。我们一般会以更高的频率去更新原始的问题变量,然后以较低的频率去更新对偶变量。这种方法中有一些问题有待回答和进一步验证,已有一些论文提到由于这个方法是近似得到一个原问题的最优解,因此存在对偶间隙,这个问题仍需进一步探索。另一方面,这类方法在实践的过程中收敛比较慢,每一次做优化时都要先固定一个对偶变量,然后再做内部原问题的寻优。当原问题收敛得差不多了,我们再更新一下结果变量,其中相当于套用了一个二层循环。
如下图左下角所示,绿色的线是 primal-dual 方法的一个展示,可以发现在整个训练的过程中安全约束是下降的但收敛较慢,它对于对偶变量的初始值较为敏感。
![]()
第三类方法是直接策略优化,这类方法是从策略搜索的角度出发直接去设计相关算法,我们可以在做策略优化迭代的过程中,每次去最大化策略的收益增量。
![]()
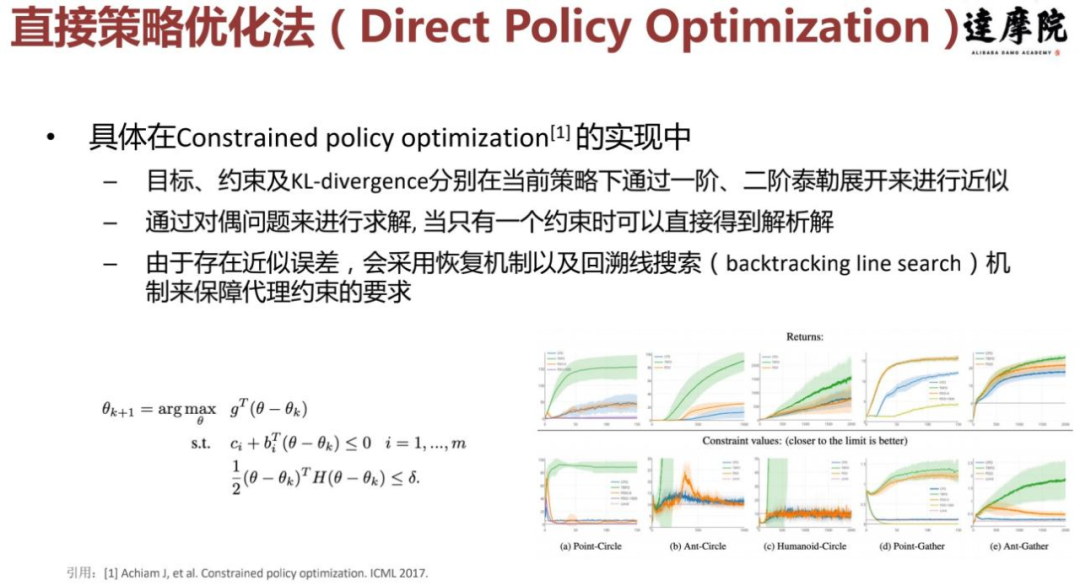
通常这一类方法是将原始优化问题的目标或约束替换为一个更易处理的代理函数。比如在 constrained policy optimization(CPO 算法)中原始问题的目标及约束被分别替换为下界及上界代理函数。当采用信赖域(Trust Region)进行策略搜索时, 可以使 worst-case 下的约束违反程度被 bound 住,而增量收益是非递减的。
![]()
因此可以通过对偶问题来求解,尤其是假设每次只违反一个约束,对偶问题可以直接得到解析解。由于存在近似误差,会采用恢复机制以及回溯线搜索(backtracking line search)机
制来保障代理约束的要求。
如上图右下角所示,以 (b) 为例,我们可以看到 CPO 的蓝色曲线在最差情况下也是可以 bound 住的,但是在训练过程中不一定严格满足原来的约束。
第四类方法就是需要有一种机制,以保证在每一个时刻下或每一个状态下,都不会违反约束。例如 2018 年有一篇论文就提出一个 safety layer 方法,采用了额外的保护措施。在该方法中,如果 action 违反了一些约束,就把它做一次调整或者做一次投影,以找到一个满足约束的解。这种方法实际上是把约束做了一些线性的近似,将约束表达成一个关于 action 灵敏度的线性函数。
![]()
灵敏度函数可以通过 NN 提前进行离线学习,没有一个明确的规则或约束形式,因此这种方法也是一种近似。
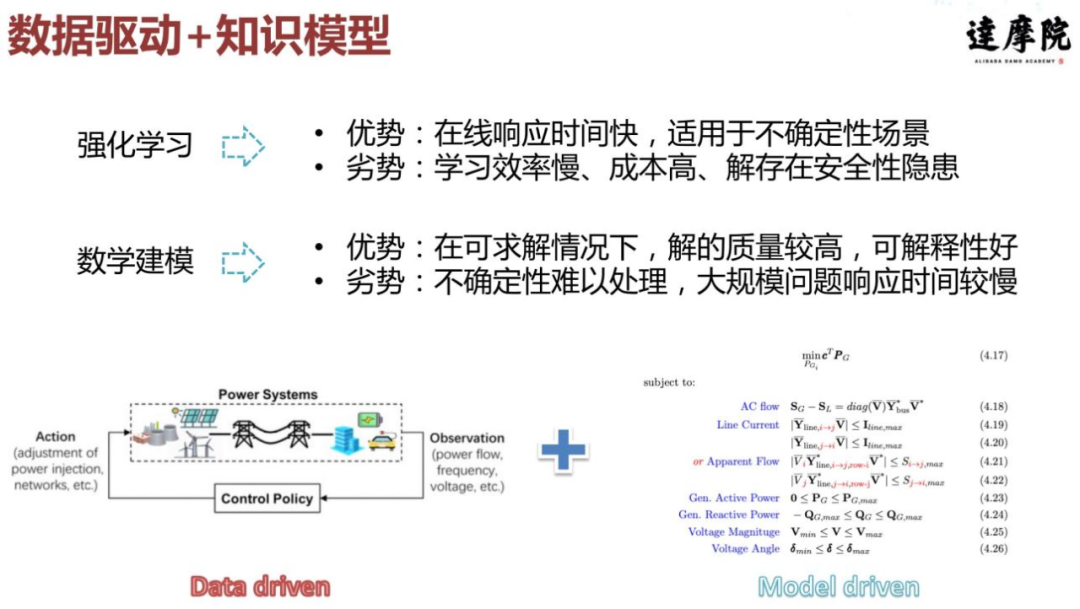
强化学习和知识模型本质上存在一些互补的优势。强化学习的优势是在线响应时间比较快,适用于不确定性场景;劣势是学习效率慢、成本高,解存在安全性隐患。而数学建模在电力领域已进行了多年研究,相对成熟。因此在可求解的情况下,解的质量会比较高,可解释性也比较好。数学建模的劣势就是对于大规模问题或不确定性问题,它的处理效果不是很好。
![]()
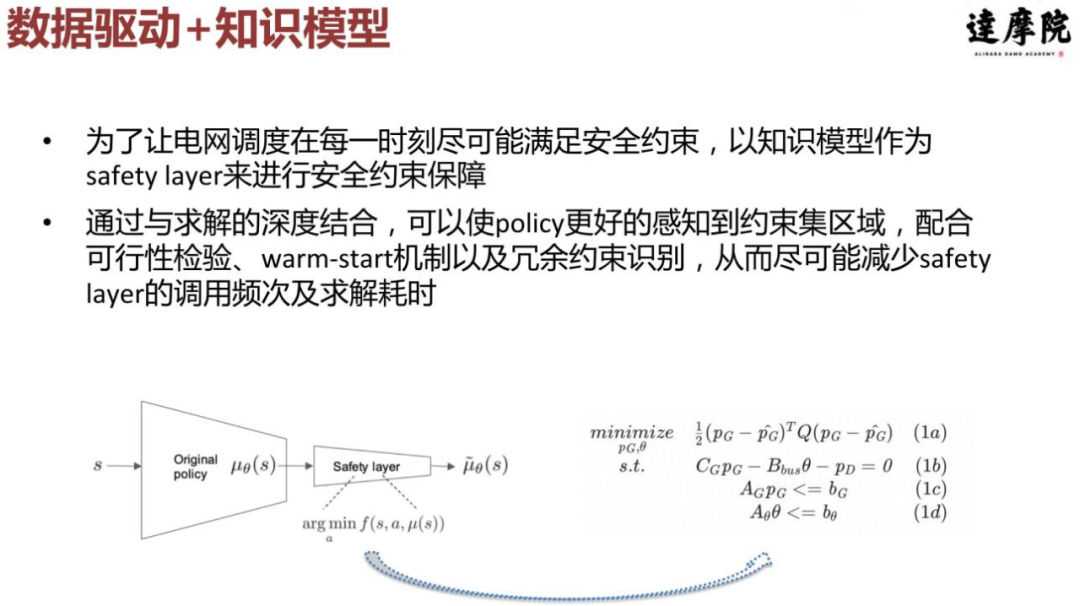
我们可以把强化学习和数学建模两种方法进行结合,以让每一时刻都不违反约束,我们以知识模型作为 safety layer 来进行安全约束保障。通过与求解的深度结合,可以使 policy 更好地感知到约束集区域,配合可行性检验、warm-start 机制以及冗余约束识别,从而尽可能减少 safety layer 的调用频次及求解耗时。
![]()
在实现的过程中,我们通过异步训练框架及算力资源来加速强化学习的收敛。从效果上讲,我们展示了两类结果,一类是单步优化,即如果一个问题能够通过数学建模表达出来,并且是个凸问题,求得的一定就是最优解,实验结果如下图左下角所示,在一个数据集上 96% 的概率下,解都是直接可行的,也满足安全因素,距离最优的 gap 不到 1%,在另外一个数据集上可行概率几乎达到 100%。如果每一个问题都用原始的 solver 去求解,提速可以达到 6 倍,甚至说提升了一个量级。
![]()
对于多步优化,我们也对比了三类方法:Our Method(A1)
、Penalty Method(A2)、以及 Safe Explore(A3)。
如上图右所示,蓝色的就是我们方法的结果,基本不会违反约束,并且获得的结果也是不错的。
最后我介绍一下我们实验室,负责人是印卧涛老师,全球 top 1% 高被引数学家,获得过 NSF CAREER 奖、斯隆研究奖、晨兴应用数学金奖、达摩奖、Egon Balas 奖等。我们实验室致力于机器学习、数学优化、时序分析与预测等多种决策技术的研究与创新,构建智能决策系统、 提升业务运营效率、降低运营成本 。目前我们已取得的成果包括优化求解器 MindOpt,多次获得国际权威榜单第一名;实验室拥有多篇顶会论文,并获多项国内外比赛冠军。2021 我们获得国家电网 AI 创新大赛电力调度赛道冠军、新能源预测赛道亚军;负荷预测落地山东德州达到 98% 的准确率。目前我们正在构建强化学习平台来支撑第 4 届南网 AI 大赛电力调度赛道。感兴趣的同学可以联系我们,加入我们的实验室,相互学习,一起成长。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com