过去数年,以强化学习为代表的决策智能技术战胜人类玩家的新闻屡屡进入人们的视野,直观地展示了这种技术赋予 AI 的强大智能。同时,业界也开始思考,该技术能否像之前的机器学习、深度学习一样,应用到更加广泛的行业领域?
在 2022 北京智源大会「强化学习与决策智能专题论坛」上,第四范式联合创始人、首席研究科学家陈雨强发表了主题为「智能决策技术在企业智能化转型中的实践应用」的演讲。
他从决策的本质出发,介绍了强化学习通过环境学习发挥产业应用的价值,并介绍这两项技术在产业界的应用实践。
机器之心对陈雨强的演讲内容进行了不改变原意的整理。
第一阶段,在 2010 年前后,随着数据量增长、算力增强以及算法提升,人工智能开始帮助互联网实现很大的飞跃。其中,受益最显著的领域要属搜索、广告和推荐(搜广推)。
第二阶段,2015 年以后,随着 AlphaGo 的出现,人工智能被认为是一个改变生产力的新技术,开始试水除互联网之外的其他一些行业,比如智慧金融、智慧零售、智慧安防和智慧医疗。
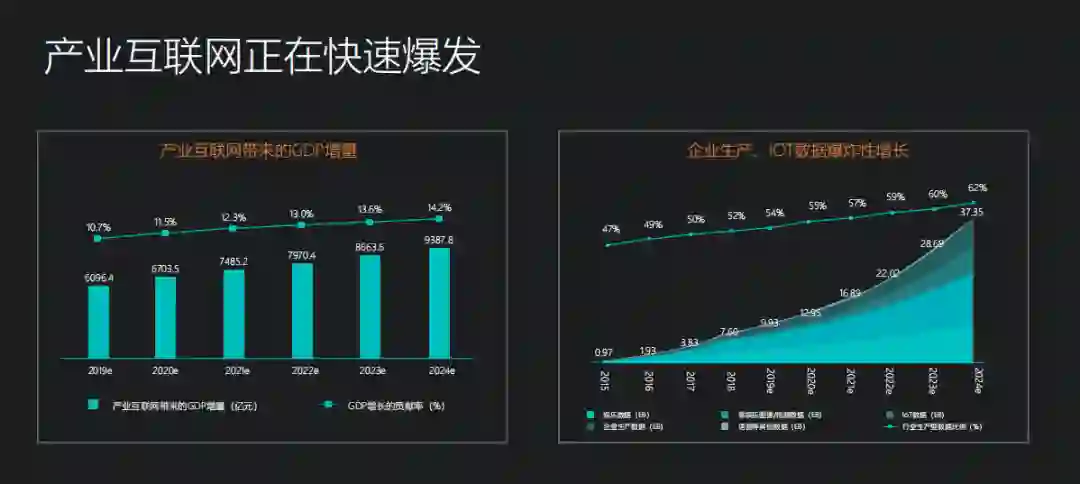
如今到了第三阶段,AI 已经不仅局限在个别行业领域,而是走向了赋能千行百业的道路上,产业互联网迎来了爆发期。产业互联网带来的 GDP 增量连年上升,并且企业生产和 IOT 数据呈现爆炸式增长,远未见顶。
![]()
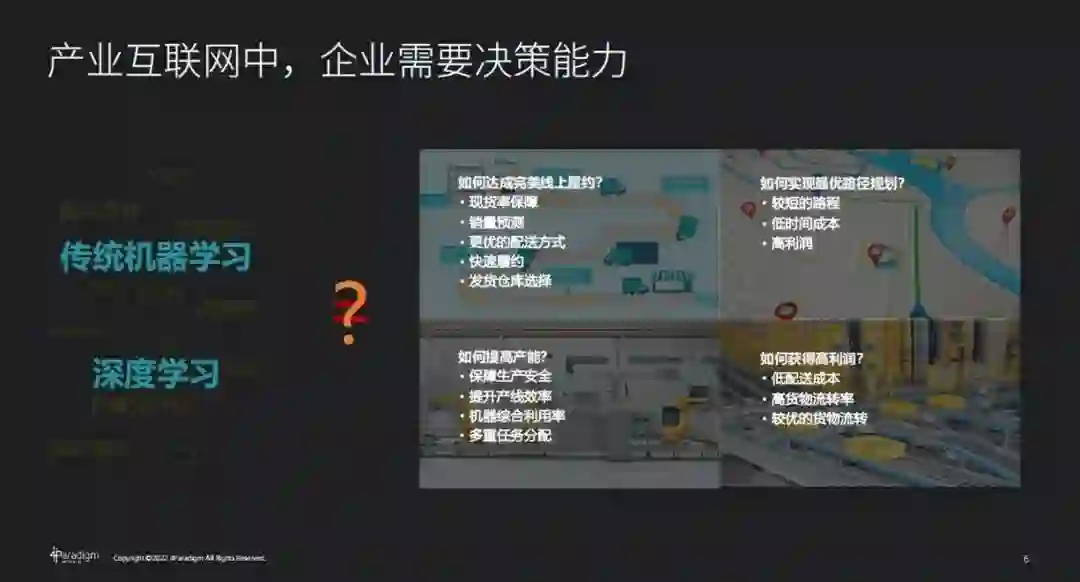
产业互联网服务于工业、制造业及其他各行各业。以工业生产为例,在过去传统的工业化生产的过程中,不管是外部环境、供求关系、生产计划等,都相对标准化,
转型更多做的是信息化转型
,尤其是流程的信息化和生产资料的信息化,从而优化管理,提升效率。
但是,面对当下高度不确定性的乌卡时代,外部环境与消费者需求高度变化,产品也高度多样化。
面向大量的不断变化问题,固定流程已经没法保证效率与产能,因此单纯的信息化已经无法形成有效的决策与安排
。
![]()
另外,我们发现若使用人工智能解决这类问题,过去广泛应用在互联网核心场景的技术并不是解法的全部。
例如在供应链场景中,最核心的是要保证现货率与库存周转,但背后包含了销量预测、从哪发货、货发多少、如何配送等一系列问题。又例如在制造领域的生产环节中,工厂的核心目标是在需要保障生产安全合规的前提下,针对动态增加的订单合理的排产来提高产线效率、产能,提高机器综合利用率。在产品研发的环节中,需要决定生产什么类型的产品更受消费者欢迎。
这些已经不仅是对未来的预测,而是当下该如何行动才能达成未来的预测结果。
同时,不断变化也给技术本身带来了巨大的挑战。这些
决策场景往往面对的是大规模连续实时精准问题,更加关注长期回报,而非单次结果;场景的环境在时刻变化,每一次输出的结果可能会改变场景环境本身
,比如交通场景中,单车的遵守或违背规则的决策会直接影响交通环境,改变整体环境的状态;在复杂多变的环境和众多的影响因素下,
部分场景还需要实时输出决策结果
。
决策智能的关键:在动态环境中持续、快速找到最优决策
决策智能技术是解决这类复杂问题的关键,其核心是通过技术手段利用机器模拟人的决策思维方式。美国知名专家 John Boyd 曾提出了
OODA Loop 决策周期理论,被广泛用于概括企业的决策闭环,分别是 Observe(观察)、Orient(判断)、Decide(决策)和 Act(行动)
。四个环节构成相互关联、相互重叠的循环周期。
![]()
首先对企业进行全面 “观察”,为决策提供充足信息依据;然后在观察的基础上,精准“判断” 所处现状及未来发展,为决策提供参考结论;接着根据当前现状和对未来的预判,制定较优 “决策” 方案,走好整个决策流程的关键一步;最后基于前三步的成果采取相应“行动”。这一循环反复迭代,持续迭代决策结果。
其中,
在整个决策周期中,能否理想地完成观察、判断和决策环节,决定了业务决策的整体质量和效果。
在没有人工智能的时代,企业主要以人为中心进行决策。不过人的计算能力是有限的,没有办法做到事无巨细的观察,获得的信息也不是最全面准确的,只能通过抓大放小的方式做出有限理性的判断和决策。同时,这种决策趋向于整体的决策,无法做到非常细节。庞大的企业组织还会带来决策效率等问题。
此前,也有诸如数字孪生、模拟仿真和运筹学等技术来辅助人做决策。
数字孪生利用传感器、业务系统收集的数据,打造一个反映物理世界全生命周期的数字化系统。该技术的核心价值是帮助企业
更及时、细致的观察业务发展,即实现了 OODA 的第一步——观察。
传统的仿真技术的核心是专家通过
手工模拟器仿真模拟人的判断,即 OODA 第二步—判断。
运筹学则是
通过数学模型模拟人的决策过程,即 OODA 的第三步——决策
。由于该技术通常可以给出理论最优解,被应用于各类决策场景中。
可以看出,这些技术实现了 OODA Loop 的部分环节,取得了一定的效果。然而在业务场景复杂化以及经营环境快速变化的当下,这些将
“将复杂问题简化求解”、“决策结果相对滞后” 的技术思路已无法有效地在动态环境下实时做出最优决策。
强化学习是解决复杂化、精细化决策非常合适的方法。核心是通过智能体与决策环境不断地交互,形成反馈,在动态环境中不断试错找到最优决策的方法。过去,强化学习技术已经在围棋和电竞游戏领域得到了验证,如典型的 AlphaGo 和 AlphaStar。
相比于人和传统决策技术,强化学习更适合解决复杂实际决策问题
。首先,得益于深度学习技术的发展,深度强化学习借助深度学习,使得决策策略可以融合复杂场景中的大量因素;其次,结合功劳分配(Credit Assignment)考虑连续决策的长期影响;同时依靠计算机强大的计算能力,提供大量精细化决策,并依靠分层强化学习技术,实现不同决策层级的自主决策。
但是问题在于,
强化学习所需要的数据量往往是比深度学习大两到三个量级
,如果真正把强化学习直接应用到现实中,企业往往无法承受获得数据的成本,以及试错的代价。
比如直接在真实的路况中使用强化学习来实现无人驾驶可能造成大量人员伤亡;或者在生产环节中直接应用有可能造成产品报废、产线异常甚至生产安全事故,这种结果是不可逆的。由于当前强化学习技术极低的样本利用效率,企业难以支撑强化学习大规模的试错成本与代价,这也是过去强化学习在游戏或固定边界中运用较好但在现实中
无法广泛应用的原因所在。
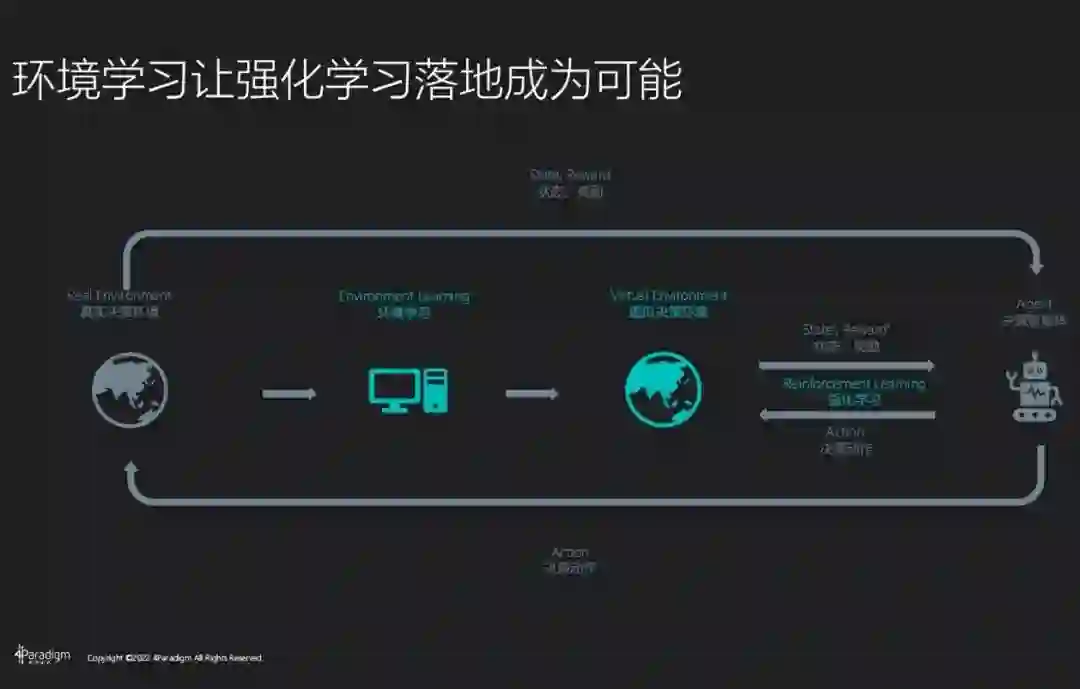
环境学习技术的出现正好解决了强化学习技术落地成本高、不可逆等业界难题。
![]()
具体来讲,
环境学习综合了专家知识、机理模型和数据驱动的机器学习能力
,能够构建更为精准的虚拟环境,因此可以为决策提供更加精准的预判,定量推演在不同决策情况下的业务发展。同时,
构建的虚拟环境可以帮助强化学习做低成本试错和策略迭代,加速了强化学习的产业应用进程
。
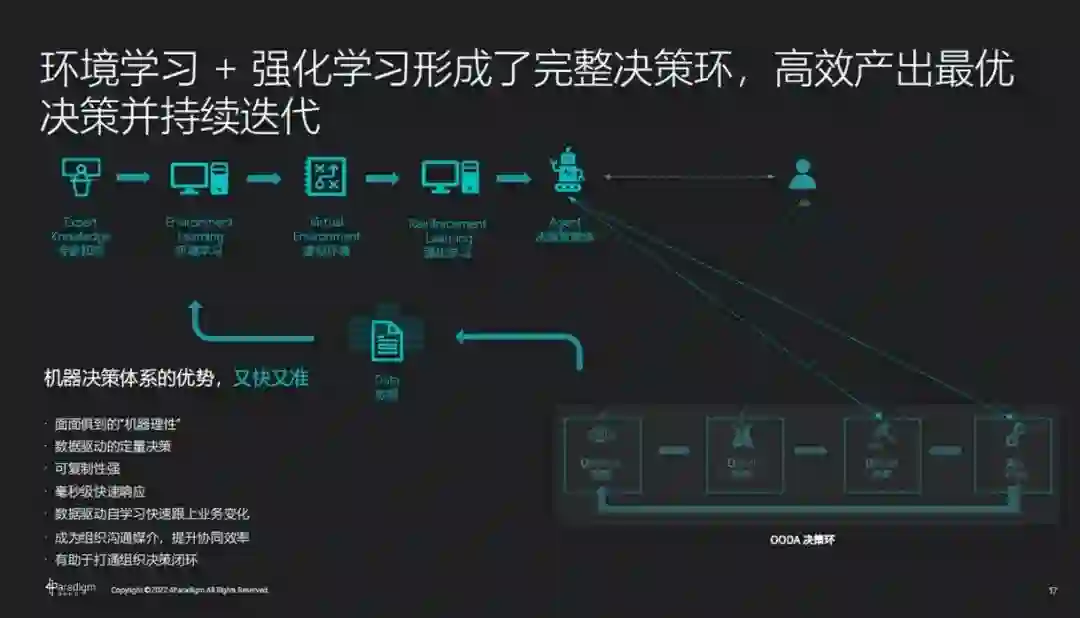
基于强化学习和环境学习的智能决策技术,能够充分发挥机器的优势,实现数据驱动的定量决策,在实时决策的同时,快速跟上业务及环境的变化,做到面面俱到的「机器理性」
。同时也弥补了数字孪生、仿真模拟的缺陷,打通 OODA 闭环,让 AI 技术能够在供应链、产品研发、派工排产、精准营销等复杂场景中做出更好的决策效果。
![]()
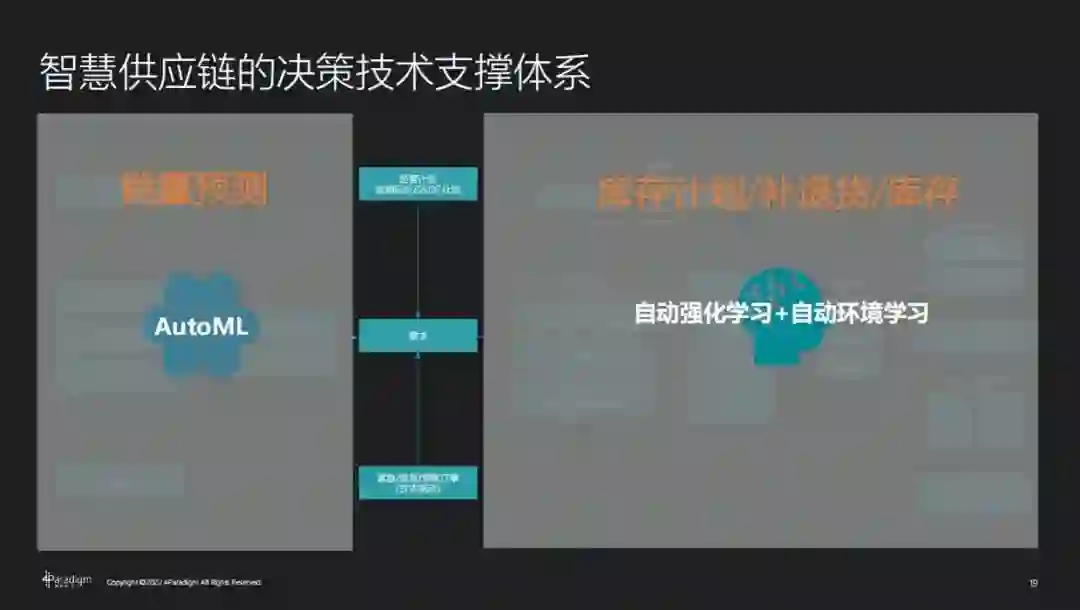
供应链是决策智能的典型应用场景之一。以供应链优化中的智能补货场景为例,业务的核心目标是通过销量预测进行供应链补货。传统方案会根据专家经验进行滑动销量预测,然后根据预测结果制定调拨计划。但当面临 618 等促销活动,或者某地区突发疫情导致的商品需求激增时,需要尽早预判并快速调拨货物。
第四范式采用了如下模式:
利用自动机器学习(AutoML)做销量预测,同时用自动强化学习 + 自动环境学习做策略优化(库存计划 / 补退货 / 库存)
。
![]()
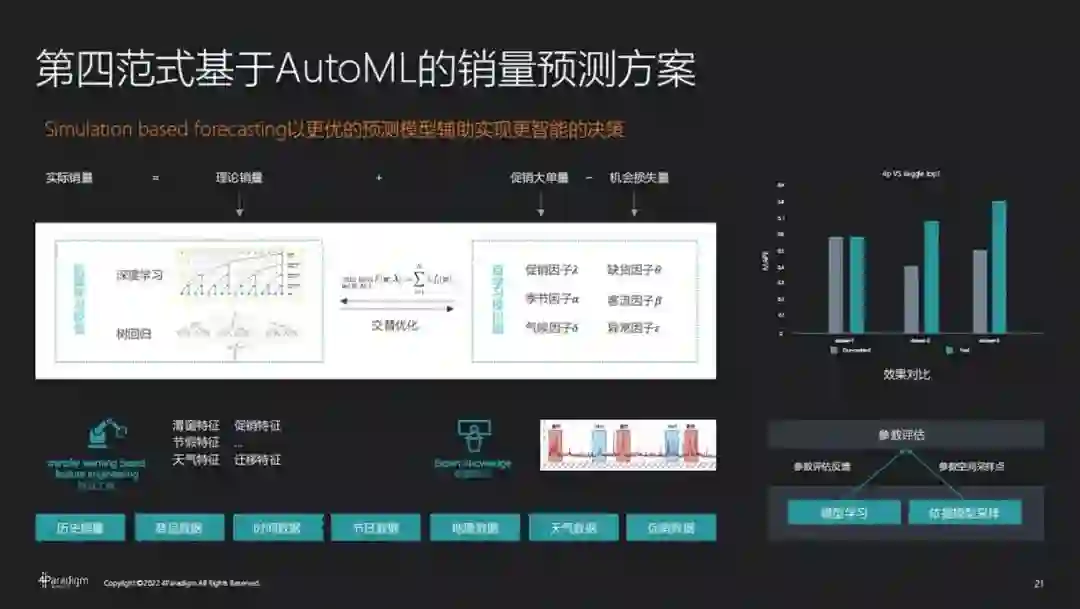
传统销量预测方案不能预测大单量和机会损失量,预测销量也与实际销量偏差较大。同时,模型效果依赖于大量的特征工程,缺少归因分析和领域知识。第四范式基于 AutoML 的销量预测方案结合了历史销量、商品数据、时间数据、节日数据、地理数据、天气数据和促销数据等诸多因素,以更优的预测模型辅助实现更智能的决策。
![]()
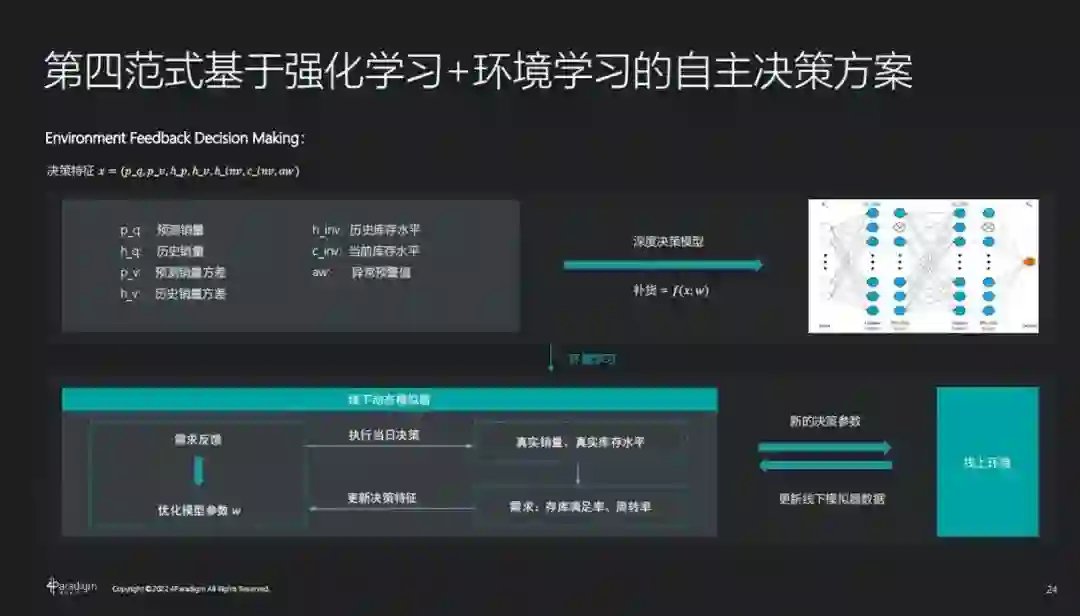
在此基础上,利用环境学习搭建模拟器去模拟现有库存率和现货率。该方案具备数据友好、模型保持高保真度、高灵活度、利于传统机理模型结合等优势。
![]()
相较于传统决策方案(即补货结果 = 预测销量 + 安全库存﹣当前库存),基于强化学习 + 环境学习的决策方案能够实现最优且动态的自主决策,且效果有较大提升。
![]()
来伊份基于自主决策方案构建了智能供应链体系,完成了从顶层的订单履约达成率和库存周转分解到销售预测、商品定价、库存管理、物流配送能力等完整的供应链业务数据化,实现了计划与调度方案可根据不
同的业务环境自
动输出决策结果,保证了供应链数据透明、可试算、可追溯,计划与执行结果可评估、可分析,同时实现业务的可视、可控、可优化。
最终,智能供应链实现了 38 万长尾商品系统智能补货,约 3000 个门店系统自动补货调拨;销售预测准确率提升 1 倍;销售现货率达到 95% 以上 ;全渠道的盘货管理预计可节约 20 万人时 / 每年人效
,节约库存资金数亿元。
随着技术的发展和演进,智能决策技术正在成为传统企业数字化转型中不可或缺的核心技术,也加快了产业互联网进程。我们也希望能有更多优秀的企业、人才关注决策智能领域,共同推动技术产业化落地与发展。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com