入门 | 蒙特卡洛树搜索是什么?如何将其用于规划星际飞行?
选自kdnuggets
作者:Mateusz Wyszyński
机器之心编译
参与:Panda
本文解读了蒙特卡洛树搜索算法背后的概念,并用一个案例说明了欧洲航天局使用该算法来规划星际飞行的方法。
前段时间,我们见证了游戏人工智能领域历史上最重大的事件——AlphaGo 成为了第一个在围棋上战胜世界冠军的计算机程序,其相关论文参阅:https://www.nature.com/articles/nature24270。
DeepMind 的开发者将来自机器学习和树搜索的不同技术结合到一起而实现了这一结果。其中之一就是蒙特卡洛树搜索(MCTS/Monte Carlo Tree Search)算法。这个算法很容易理解,而且也在游戏人工智能领域外有很多应用。下面我将解释 MCTS 算法背后的概念,并且还将简要介绍欧洲航天局是如何使用该算法来规划星际飞行的。
完美信息博弈
蒙特卡洛树搜索是在执行所谓的完美信息博弈(perfect information game)时所使用的算法。简单来说,完美信息博弈是指每个玩家在任意时间点都具有关于之前发生过的所有事件行动的完美信息的博弈。这样的博弈案例有国际象棋、围棋和井子棋。但并不是说每一步行动都已知就意味着可以计算和推断出每一个可能的结果。比如,围棋中合法的可能局面的数量就超过了 10^170。
每种完美信息博弈都可以通过以下方式表示成树形式的数据结构。首先,你有一个代表博弈的起始状态的根(root)。对于国际象棋而言,即是摆在棋盘上合适位置的 16 个白方棋子和 16 个黑方棋子。对于井子棋而言则是简单的 3x3 空方格。第一个玩家有一定数量 n1 的可能选择。在井子棋中即是在 9 个可能的位置画一个圈。每一种走法都会改变博弈的状态。这些所得到的状态是根节点的子节点。然后,对于 n1 个子节点中的每一个,第二个玩家有 n2 种可能的走法可以考虑,其中每一种走法又会产生另一个博弈状态——得到一个子节点。注意 n1 个节点中每一个节点所对应的子节点数量 n2 可能各不相同。比如在国际象棋中你可能会采取一种走法迫使对方移动他的国王;但你也可能选择另一种走法,让你的对手有很多选择余地。
一局博弈的结果就是从根节点到其中一个叶节点的路径。每一个叶节点都包含了一个确定的信息,说明了谁胜谁负。
根据树进行决策
在完美信息博弈中进行决策时,我们面临着两个主要问题。首先也是最主要的一个是树的规模。
对于井子棋这种可能性非常有限的博弈来说,这不是什么问题。我们在开始时最多只有 9 个子节点,而且随着游戏进行这个数字还会越来越小。但对于国际象棋或围棋而言,情况却完全不同。它们所对应的树非常庞大以至于我们没法搜索整个树。解决这一问题的一个方法是在树上进行随机游走一段时间以及获取原来决策树的一个子树。
但是,这又会带来另一个问题。如果我们每次选择时都沿着树随机游走,我们就忽视了我们的选择的效果,也没法从之前的游戏中学习。下过国际象棋的人都知道在棋盘上随机乱下是坚持不了太长时间的。也许新手可以通过这种方法来了解各个棋子的走法。但一局又一局的游戏之后,新手也能越来越好地区分好的下法和糟糕的下法。
所以我们有什么方法可以利用之前构建的决策树中所包含的事实来推理下一步走法呢?方法当然是有的。
多臂赌博机(MAB)问题
想象一下,如果你在一家赌场里,想玩一下老虎机。你可以随机选择一台然后开始玩。那天晚上晚些时候,另一位坐在你旁边的赌博者在 10 分钟内赢得钱比你在过去几个小时内赢的还多。当然,你不应该和别人比,这都是运气问题。但是,你当然也想知道下次你能不能赚多一点。那么你应该选择哪一台老虎机才能赚最多呢?也许你一次应该玩多台老虎机?
你面临的问题是多臂赌博机问题(Multi-Armed Bandit Problem)。这个问题在第二次世界大战期间就已经为人所知了,但我们今天最常了解的版本是由 Herbert Robbins 在 1952 年制定的。设有 N 台老虎机,每一台都有不同的预期回报值(你从给定机器所得到的预期净收入)。但你不知道任何机器的预期回报值。你可以在玩的过程中随时更换机器,也可以在任何机器上玩任意次数。那么最优的策略是什么?
在这样的场景中,「最优」意味着什么?显然你的最佳选择是只在回报值最高的机器上玩。最优策略是指能让你得到的结果尽可能接近在回报值最高的机器上玩所得到的结果的策略。
研究(https://doi.org/10.1016/0196-8858(85)90002-8)证明你的平均表现不可能超过
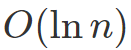
所以这就是你可以希望得到的最佳。幸运的是,事实也证明你可以达到这一边界(重申一次,是平均的)。实现这一目标的一种方法如下。
对于每一台机器 i,我们都跟踪记录两个数据:我们尝试过这台机器的次数(ni)以及平均回报值(xi)。我们也要跟踪我们玩过的总次数(n)。然后对于每个 i,我们都计算 xi 周围的置信区间:
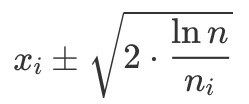
我们总是选择在具有最高 xi 上界的机器上玩(即在上式中选择 + 号)。
这是多臂赌博机问题的解决方案之一。现在注意,我们也可以将其用于我们的完美信息博弈。只需要将每一种可能的下一步骤(子节点)看作是一台老虎机就行了。每次我们选择下一步骤后,我们最后都会或胜或负或平局。这是我们得到的结果。简单起见,我假设我们的目标是获胜,那么设我们获胜时结果为 1,其它情况的结果为 0。
真实应用案例
MAB 算法在真实世界中有很多实际的应用实现,比如价格引擎优化或寻找最优的网络广告。我们这里就看看第一种案例,看看我们可以如何使用 R 语言实现它。假设你在网上销售你的产品并且想引入一种新品,但你却不知道价格该定多少才合适。你根据专业知识和经验想出了 4 种可选的价格方案:99 美元、100 美元、115 美元和 120 美元。现在你想测试一下这些价格的表现,然后选出其中对你最有利的。在第一天的实验中,当你定价为 99 美元时,有 4000 人访问了你网店,其中有 368 人购买了该产品。其它价位的测试结果如下:
定价 100 美元:4060 次访问,355 次购买
定价 115 美元:4011 次访问,373 次购买
定价 120 美元:4007 次访问,230 次购买
现在让我们看看如何用 R 来计算哪个价位在第一天实验中的表现最好。
library(bandit)
set.seed(123)
visits_day1 <- c(4000, 4060, 4011, 4007)
purchase_day1 <- c(368, 355, 373, 230)
prices <- c(99, 100, 115, 120)
post_distribution = sim_post(purchase_day1, visits_day1, ndraws = 10000)
probability_winning <- prob_winner(post_distribution)
names(probability_winning) <- prices
probability_winning
## 99 100 115 120
## 0.3960 0.0936 0.5104 0.0000
我们计算了贝叶斯概率(Bayesian probability)来了解哪个价位的表现最好,可以看到 115 美元的价格有最高的概率(0.5)。而 120 美元对顾客来说价格似乎太高了。
我们还要继续实验几天。
第二天的结果:
visits_day2 <- c(8030, 8060, 8027, 8037)
purchase_day2 <- c(769, 735, 786, 420)
post_distribution = sim_post(purchase_day2, visits_day2, ndraws = 1000000)
probability_winning <- prob_winner(post_distribution)
names(probability_winning) <- prices
probability_winning
## 99 100 115 120
## 0.308623 0.034632 0.656745 0.000000
第二天依然是 115 美元价位的表现最好,99 美元和 100 美元价位的表现接近。
我们还可以使用 bandit 软件包执行显著性分析,使用 prop.test 进行整体比例比较是非常方便的。
significance_analysis(purchase_day2, visits_day2)
## successes totals estimated_proportion lower upper
## 1 769 8030 0.09576588 -0.004545319 0.01369494
## 2 735 8060 0.09119107 0.030860453 0.04700507
## 3 786 8027 0.09791952 -0.007119595 0.01142688
## 4 420 8037 0.05225831 NA NA
## significance rank best p_best
## 1 3.322143e-01 2 1 3.086709e-01
## 2 1.437347e-21 3 1 2.340515e-06
## 3 6.637812e-01 1 1 6.564434e-01
## 4 NA 4 0 1.548068e-39
可以看到 120 美元的表现仍然是最差的,所以我们丢弃这个配置,继续下一天的实验。因为其 p_best 值非常小(可忽略),所以这种做法是最好的。
第三天的结果:
visits_day3 <- c(15684, 15690, 15672, 8037)
purchase_day3 <- c(1433, 1440, 1495, 420)
post_distribution = sim_post(purchase_day3, visits_day3, ndraws = 1000000)
probability_winning <- prob_winner(post_distribution)
names(probability_winning) <- prices
probability_winning
## 99 100 115 120
## 0.087200 0.115522 0.797278 0.000000
value_remaining = value_remaining(purchase_day3, visits_day3)
potential_value = quantile(value_remaining, 0.95)
potential_value
## 95%
## 0.02670002
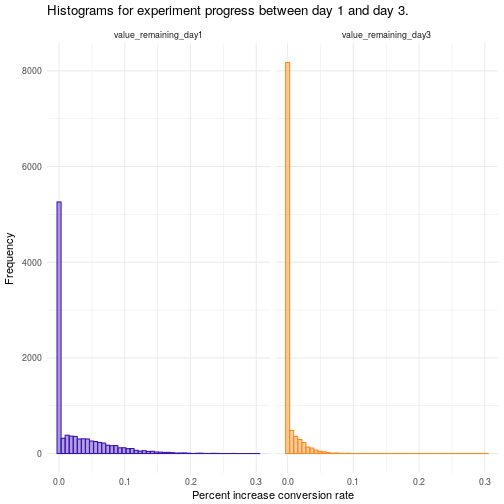
第三天的结果能让我们总结得出:115 美元的价位设置具有最高的转化率和收入。我们仍然不确定最佳价格 115 美元的转化概率,但不管是多少,其它某个价格还有 2.67% 的概率超过它(剩余价值的 95% 分数位)。
下面的直方图给出了剩余价值分布上的情况。提升量的分布说明随着实验的继续,另一个价格有可能会超过当前的最优价格。样本越多,转化率的可信度就越高。随着时间的推移,其它价格击败 115 美元的机会会越来越低。
如果你对这个案例有兴趣,请参阅我们另一篇有关动态定价的文章:https://appsilondatascience.com/blog/business/2017/11/14/dynamic-pricing.html
蒙特卡洛树搜索
现在我们可以学习蒙特卡洛树搜索的工作方式了。
只要我们有足够多的信息可以将子节点看作是老虎机,我们就可以像解决多臂赌博机问题一样选择下一个节点(步骤)。当我们有一些关于每个子节点的结果的信息时就能做到这一点。
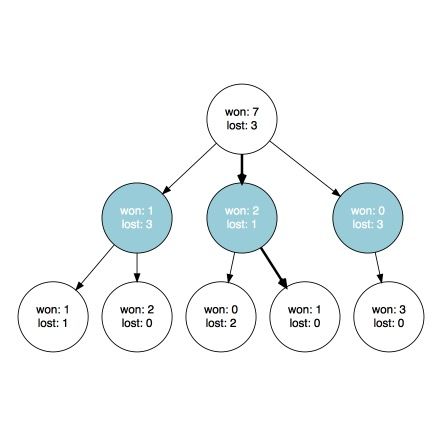
我们会在某个时候到达某个我们无法再继续以这种方式继续的节点,因为此时至少有一个节点没有可用的统计数据。是时候探索这个树来获取新信息了。这可以完全随机地完成,也可以在选择子节点时应用一些启发式方法(实际上对于具有大量分支的博弈(比如围棋)来说,如果我们想得到好结果,这可能是必不可少的)。
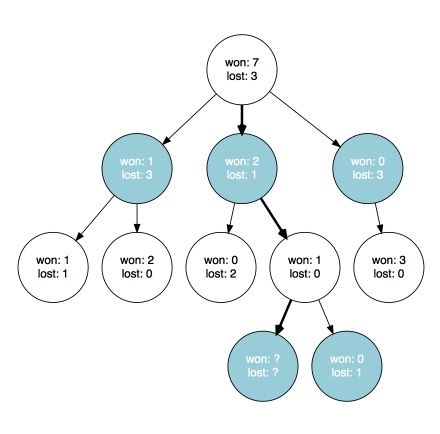
最终,我们会到达一个叶节点,然后检查我们是否获胜。
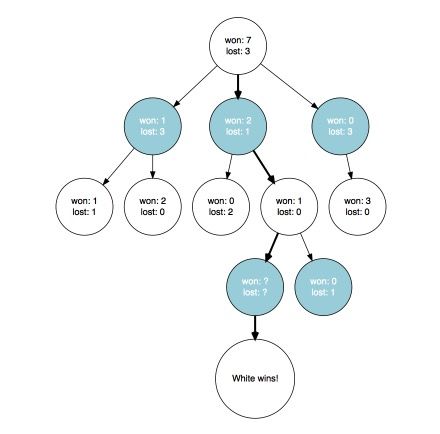
现在我们可以更新我们到达叶节点过程中所访问过的节点。如果玩家在对应节点的行动带来了胜利,那么我们就增加一个获胜数。否则我们就保持原样。不管我们是否获胜,我们总是增加经历该节点的次数(在对应的图中,我们可以根据胜负的次数自动推断它)。
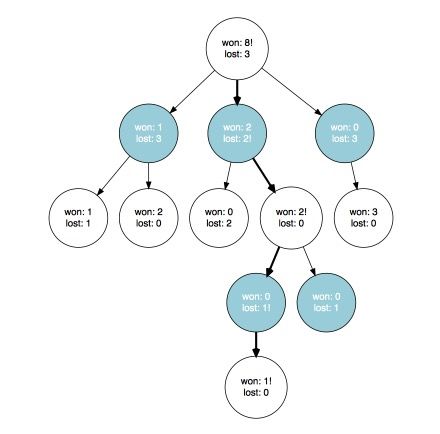
就是这样!我们重复这个过程直到满足某个条件:超时或我们之前提到过的置信区间稳定(收敛)。然后我们根据在搜索过程中收集到的信息做出最后的决策。我们可以选择有最高结果上界的节点(正如我们在多臂赌博机问题的每次迭代中做的那样)。或者你也可以选择有最高平均结果的节点。
做出决策之后,就选择了行动。现在轮到我们的对手行动了。当他们结束之后,我们就到达了一个新节点,在这个树中更深的某个位置;然后我们继续上面的操作。
不只是游戏
你可能也注意到了,蒙特卡洛树搜索可以被看作是在完美信息博弈场景中进行决策的一种通用技术。所以它的应用领域并不只限于游戏领域。我听说过的最惊人的用例是用来规划星际飞行。我这里会简单介绍一下,你也可以在这里查看:http://www.esa.int/gsp/ACT/ai/projects/mcts_traj.html
你可以将星际飞行看作是访问多个行星的旅程,比如从地球经由火星飞往木星。
实现这一目标的一种方法是利用这些行星的引力场(就像电影《火星救援》中那样),这样做可以节省燃料。问题在于到达和离开每个行星表面或轨道的最佳时机是怎样的(对于起点和终点的两个行星,仅有到达和离开)。
你可以将这个问题看作是一个决策树。如果你将时间分成区间,在每个行星处你都要进行一次决策:我应该在哪个时间段到达,又该在哪个时间段离开。每个选择都会影响后面的选择。首先,你不能在到达之前离开。其次,你之前的选择决定了你当前剩余的燃料以及你在宇宙中所处的位置。
这些连续选择集合起来就决定了你最终所到达的位置。如果你访问了所有的检查点,那你就赢了。否则你就输了。这就像是一个完美信息博弈问题。但你没有对手,你的行动是确定离开/到达的时间段。这可以使用上述蒙特卡洛树搜索方法解决。实际上和其它方法相比,蒙特卡洛树搜索方法的表现其实相当好,参阅:https://fenix.tecnico.ulisboa.pt/downloadFile/563345090414562/Thesis.pdf。而且它还不需要任何特定领域的知识就能实现。

原文链接:https://www.kdnuggets.com/2017/12/introduction-monte-carlo-tree-search.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



