少样本关系抽取技术
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要16分钟
跟随小博主,每天进步一丢丢


每日英文
What makes life dreary is the want of motive.
没有了目的,生活便郁闷无光。
Recommender:云不见
作者:李学凯、吴桐桐、漆桂林
原文链接:https://zhuanlan.zhihu.com/p/159438322
编辑:王萌 澳门城市大学(深度学习自然语言处理公众号)

在之前的文章中,我们已经介绍过了知识图谱是什么,知识图谱的表示,以及知识图谱的应用等相关主题。我们也提到过,知识图谱技术栈比较长,也给出了一些适合初学者进行学习的相关资料。
在知识图谱构建技术栈中,关系抽取(Relation Extraction)技术是其中的重要环节。如图1所示,关系抽取的一般形式是给定文本及文本中涉及的两个实体,判定实体之间是否存在关系以及存在何种关系。关系抽取不但是知识图谱构建中的重要环节,在自动问答、自动摘要、情感分析等技术中也被广泛使用。

图1. 关系抽取示例
传统的监督学习方法在关系抽取任务上取得了不错的效果,但在实际应用中,监督学习方法需要大量高质量的标注语料,而对语料进行标注的工作需要耗费大量的人力物力,且难以迁移到其他领域中去,因此其应用价值大打折扣。之前的一个访谈中,就提到了知识图谱的未来发展是需要处理少量标注甚至无标注的问题:
为了解决监督学习中的数据需求问题,一种解决思路是远程监督的方法,这种方法通过对齐的大量的文本语料和已有知识库来自动地生成大量带有标签的训练数据,从而减轻人工标注的成本;另一种思路是研究如何充分利用少量标注样本进行训练,使得模型具有更好的泛化能力。
利用极少量的样本来训练一个神经网络是近年来的一个研究热点,这种利用少量样本进行训练的范式逐渐发展成了一个专门的机器学习分支——少样本学习(Few-shot Learning)。少样本学习首先在图像领域获得了成功,众多自然语言处理领域的研究者先后跟进,并结合少样本学习做出了众多state-of-the-art的工作。
少样本关系抽取任务的目标是通过利用极少量的标注数据训练(或Fine-Tuning)模型,使得模型可以快速学习到一个关系类别的特征,从而对这样只有极少数样本的类别进行准确分类。图2所示是少样本关系抽取任务的一个范式,初始网络参数f_θ使用少量关系Ri的实例进行训练或微调后得到参数f_(θi ),这组参数可以很好地用于提取对应的关系Ri。少样本学习中常见的实验设置一般被称为N-way-K-shot,N-way代表分类任务中可能的类别数量,K-shot表示每个类别有K个训练数据。
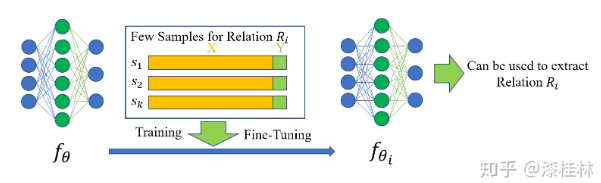
图2. 少样本关系抽取范式
这篇文章中我们先介绍一下少样本学习的两类主要方法,然后介绍几个结合少样本学习方法的关系抽取相关工作。
(1)度量学习
度量学习通过先验知识学习一个度量函数,利用度量函数将输入映射到一个子空间中,使得相似和不相似的数据对可以很容易的分辨,通常用于分类问题。度量学习是子空间学习的一种。
度量学习根据嵌入信息的类型,又分为task-invariant,task-specific和两者混合的方法。
a. 在task-specific方向,如[1]仅为训练数据学习了一个度量函数,只考虑目标任务的信息来进行子空间的度量学习。
b. 在task-invariant方向,主要通过外部的大数据集来学习一个度量函数,在子空间中如果一个模型可以很好的进行分类,那么这个模型就可以直接应用于训练数据中进行分类。经典的siamese网络通过额外数据集学习一个度量函数,并通过两个参数共享的分支在子空间输出两分支图片的相似度完成分类[2]。[3]在siamese网络的基础上在低维子空间令网络学习一个可以辨别模糊语句的分类器。在该方向,出现了利用元学习(Meta Learning)来不断优化嵌入函数的方法,即所谓的Meta Metric Learning:匹配网络[4]是第一个使用元学习的嵌入学习方法,通过一个set-to-set框架学习映射模型进行近邻分类。
c. 在混合度量模型中,同时考虑了目标任务的特定信息和外部数据集的信息,[5]提出了Learnet网络,首先利用外部数据集训练一个元学习器,再对目标任务生成一个pupil net的参数。
(2)元学习
元学习在少样本学习方向上主要是优化在假设空间寻找最优参数的策略,主要包括两种方式:
a.寻找一个合适的初始参数。此类方法即meta-representation,经典方法就是模型无关的元学习方法(MAML)[6]。
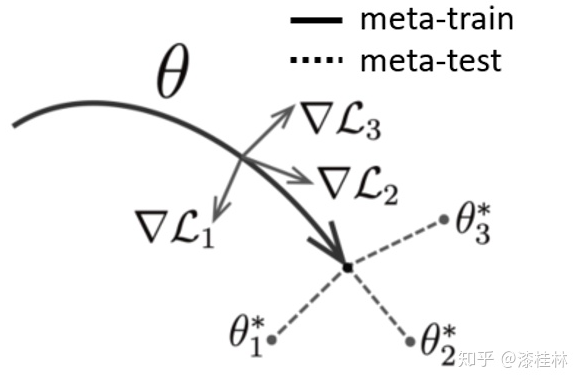
图3. MAML参数训练示意
其核心思想在于寻找一个模型的初始值,使得该模型能在新任务的少量训练数据上进行快速学习:
a. 获得一个较好的效果,具体是通过二层循环结构训练一个元学习器,改变梯度下降的方向,从而找到对于任务分布来说敏感的参数,这些参数轻微地改变可以引起loss函数较大地改变,从而可以使用少量样本达到loss快速下降的效果。
其核心思想在于寻找一个模型的初始值,使得该模型能在新任务的少量训练数据上进行快速学习,获得一个较好的效果,具体是通过二层循环结构训练一个元学习器,改变梯度下降的方向,从而找到对于任务分布来说敏感的参数,这些参数轻微地改变可以引起loss函数较大地改变,从而可以使用少量样本达到loss快速下降的效果。
图3是MAML参数训练的一个简单示意图。在图上点1处,有模型参数θ和三个不同分布的任务T1,T2,T3。三个任务在模型上的优化梯度的方向分别是∇L1,∇L2,∇L3,模型按梯度的方向的平均进行更新。到达点2处,模型参数θ*,是一个对任务分布来说敏感的参数,利用少量样本可以快速使模型adapt到对应任务的优化参数,即图中θ1*,θ2*,θ3*。
b. 学习一个优化器。此种策略聚焦于学习一个优化器来直接输出参数更新,[7]基于LSTM训练了一个元学习器用于学习一个在给定迭代更新次数的情况下在每个任务下快速收敛分类器的模型。
清华大学NLP团队2018年提出了首个大型少样本关系抽取数据集FewRel,并且在2019年更新了FewRel 2.0版本。绝大多数少样本关系抽取的工作都会在FewRel上进行评测。
FewRel 1.0数据集有100个关系类别,每个关系类别有700条训练数据,其中有80条关系的数据被公开,另外20条关系的数据则不公开。FewRel数据集是一个非常规整的数据集,标注准确,且不存在长尾问题。TinyRel-CM数据集则是从Chinese Literature NER RE中导出的少样本关系抽取数据集,一共只有12个关系类别,共计1100条实例。
度量学习方法在实例级别抽取以及远程监督抽取上都有一定的应用。
Snell等人提出了原型网络[8](见图4)。可以应用在少样本关系抽取任务上,作为一个Baseline。原型网络通过学习实例和关系的表示。利用最近邻思想,对新的实例进行分类。
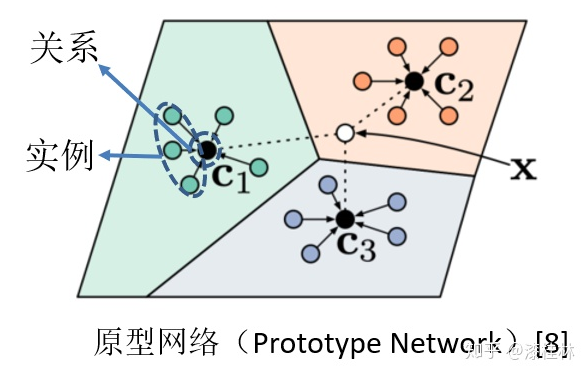
图4. 原型网络(Prototype Network)[8]
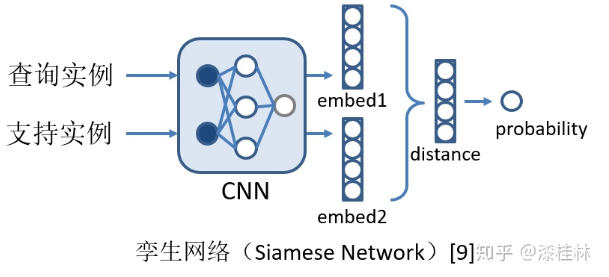
Koch提出的孪生网络的思想则是利用CNN网络学习每一个实例的表示,并通过计算查询实例和每一个支持实例的距离来判断所属的类别。同样被应用于关系抽取任务中,如图5所示。
还有一些利用度量学习思想的改进工作,可以看看这几篇工作:
Large Margin Prototypical Network for Few-shot Relation Classification with Fine-grained Features
链接:https://dl.acm.org/doi/10.1145/3357384.3358100
Hybrid attention-based prototypical networks for noisy few-shot relation classification
链接:https://www.aaai.org/ojs/index.php/AAAI/article/view/4604
Zero-shot relation extraction via reading comprehension
链接:https://www.aclweb.org/anthology/K17-1034/
MLMAN[10]是目前在FewRel 1.0榜单上效果比较好的工作。采用原型网络的思想,分别计算查询实例的嵌入向量和各支持集的原型向量,取得了比较好的效果,图6是该模型的实验结果。
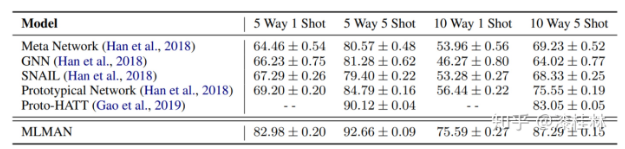
图6. MLMAN在FewRel数据集上的效果
纯元学习方法在关系抽取上的应用相对少一些,这是因为元学习不仅是一种模型,更像是一种训练的框架,基于MAML或Reptile的元学习方法大多只是改动了内部的学习器。元学习方法的优势在于,元训练阶段可以学习到通用的分类经验而元测试微调阶段时,可以在特定的任务上快速收敛,达到一个较好的效果。但在NLP任务中,仅使用少量样本来计算高维参数空间中的梯度可能会使泛化变得困难,这也限制了元学习模型的复杂性和层深度。也有一些工作将目光聚焦在增量关系抽取上,利用元学习解决增量关系抽取的问题取得了不错的效果,如下面几篇工作中的第三篇:
Model-Agnostic Meta-Learning for Relation Classification with Limited Supervision
链接:https://www.aclweb.org/anthology/P19-1589/
MICK: A Meta-Learning Framework for Few-shot Relation Classification with Little Training Data
链接:https://arxiv.org/abs/2004.14164
Meta-Learning Improves Lifelong Relation Extraction
链接:https://www.aclweb.org/anthology/W1
虽然少样本关系抽取已经取得了一些成果,但仍有一些问题值得我们去思考。例如在少样本典型的N-way K-shot场景在真实的关系抽取场景中可能并不完全适用。实际应用场景中,每个关系类别的标注实例很可能是极度不均匀的,有着严重的长尾分布问题。如何更好地利用多出来的标注数据提升只有极少数实例类别的性能,是一个值得我们思考的问题。少量样本或许不足以覆盖一个关系的完整语义,那如何利用好已有的知识和语料来更好地应对关系抽取的冷启动问题也值得思考。另外,最近有一些工作开始考虑从图像中抽取实体关系(如文献[11]),这是多模态知识图谱构建的核心技术之一。
此外,在实际的知识图谱构建应用场景中,图谱的构建都是一个持续地不断迭代更新的过程,这就要求关系抽取模型也能应对持续增量的场景。如何克服增量关系抽取过程中的灾难性遗忘问题,也需要我们继续去探索!
参考文献
[1]Triantafillou, E., Zemel, R., & Urtasun, R. (2017). Few-shot learning through an information retrieval lens. In Advances in Neural Information Processing Systems (pp. 2255-2265).
[2]Bromley, J., Guyon, I., LeCun, Y., Säckinger, E., & Shah, R. (1994). Signature verification using a" siamese" time delay neural network. In Advances in neural information processing systems (pp. 737-744).
[3]Yan, L., Zheng, Y., & Cao, J. (2018). Few-shot learning for short text classification. Multimedia Tools and Applications, 77(22), 29799-29810.
[4]Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. In Advances in neural information processing systems (pp. 3630-3638).
[5]Bertinetto, L., Henriques, J. F., Valmadre, J., Torr, P., & Vedaldi, A. (2016). Learning feed-forward one-shot learners. In Advances in neural information processing systems (pp. 523-531).
[6]Finn, C., Abbeel, P., & Levine, S. (2017, January). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In ICML.
[7]Ravi, S., & Larochelle, H. (2016). Optimization as a model for few-shot learning.
[8] Snell, J., Swersky, K., & Zemel, R. (2017). Prototypical networks for few-shot learning. In Proceedings of NIPS, 4077–4087.
[9] Koch, G. (2015). Siamese Neural Networks for One-shot Image Recognition. Master’s thesis, University of Toronto.
[10] Ye, Z. X., & Ling, Z. H. (2019, July). Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 2872-2881).
[11] Wang, W., Meng, W., Wang, S., Long, G., Yao, L, Qi, G., Chen, Y. (2020).
One-Shot Learning for Long-Tail Visual Relation Detection.AAAI2020:12225-12232
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记

整理不易,还望给个在看!




