论文浅尝 | 用异源监督进行关系抽取:一种表示学习方法

Citation: Liu, L., Ren, X., Zhu, Q., Zhi, S., Gui, H., Ji, H., & Han, J.(2017). Heterogeneous Supervision for Relation Extraction: A RepresentationLearning Approach. Retrieved from http://arxiv.org/abs/1707.00166
动机
现有的关系抽取方法严重依赖于人工标注的数据,为了克服这个问题,本文提出基于异种信息源的标注开展关系抽取模型学习的方法,例如知识库、领域知识。这种标注称作异源监督(heterogeneous supervision),其存在的问题是标注冲突问题,即对于同一个关系描述,不同来源的信息标注的结果不同。这种方法带来的挑战是如何从有噪声的标注中推理出正确的标签,以及利用标注推理结果训练模型。
例如下面的句子,知识库中如果存在<Gofraid,born_in, Dal Riata>这个三元组,则将下面的句子标注为born_in关系;而如果使用人工模板“* killed in*”进行匹配,则会将该句子标注为kill_in关系。
Gofraid(e1) died in989, said to be killed in Dal Riata(e2).
为了解决这个问题,本文提出使用表示学习的方法实现为关系抽取提供异源监督。
创新点
本文首次提出使用表示学习的方法为关系抽取提供异源监督,这种使用表示学习得到的高质量的上下文表示是真实标签发现和关系抽取的基础。
方法
文章方法框架如下:
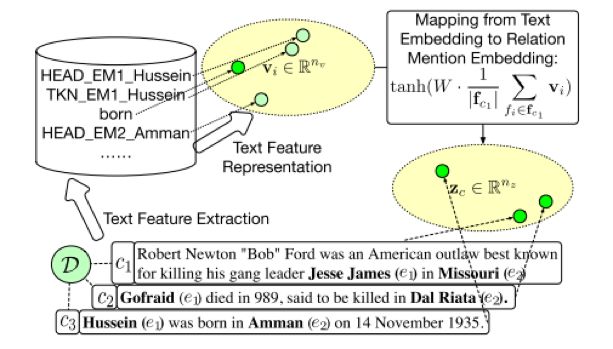
(1)文本特征的向量表示。从文本上下文中抽取出文本特征(基于pattern得到),简单的one-hot方法会得到维度非常大的向量表示,且存在稀疏的问题。为了得到更好的泛化能力,本文采用表示学习的方法,将这些特征表示成低维的连续实值向量;
(2)关系描述的向量表示。在得到文本特征的表示之后,关系描述文本依据这些向量的表示生成关系描述的向量表示。这里采用对文本特征向量进行矩阵变换、非线性变换的方式实现;
(3)真实标签发现。由于关系描述文本存在多个可能冲突的标注,因此发现真实标签是一大挑战。此处将每个标注来源视为一个标注函数,这些标注函数均有其“擅长”的部分,即一个标注正确率高的语料子集。本方法将得到每种标注函数擅长的语料子集的表示,并以此计算标注函数相对于每个关系描述的可信度,最后综合各标注函数的标注结果和可信度,得到最终的标注结果;
(4)关系抽取模型训练。在推断了关系描述的真实标签后,将使用标注的语料训练关系抽取器。
值得指出的是,在本方法中,每个环节不是各自独立的,真实标签发现与关系抽取模型训练会相互影响,得到关系上下文整体最优的表示方法。
实验结果
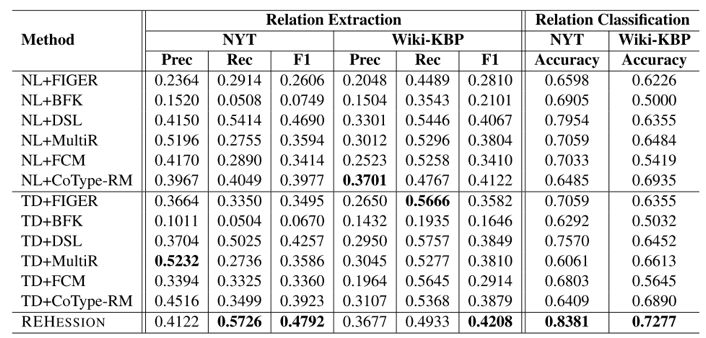
本文使用 NYT 和 Wiki-KBP 两个数据集进行了实验,标注来源一方面是知识库,另一方面是人工构造的模板。每组数据集进行了包含 None 类型的关系抽取,和不包含 None 类型的关系分类。结果如下表所示,可见本文的方法相比于其他方法,在两个数据集的四组实验中均有较明显的性能提升。
论文笔记整理:刘兵,东南大学博士,研究方向为自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




