DSGAN:使用生成式对抗网络进行远距离监督关系抽取


关系抽取任务的是依据现有文本信息,预测两个实体间的关系。例如句子:比尔盖茨创建了微软。“比尔盖茨”和“微软”是已知实体,我们通过所提供的句子可以得到这两个实体之间含有“创始人”这一关系。
传统的有监督的关系抽取算法需要大量的已标注数据,这将需要耗费人力资源进行标注。为了减少人工成本,研究者们尝试使用现有的数据(如:Freebase和NYT)对于关系抽取模型进行远距离监督,该方法的基本假设是将含有实体对的句子标注成该实体对在知识图谱中对应的关系,然后使用这一标注后的数据进行关系抽取模型的训练,该方法也被称为远距离监督关系抽取算法。远距离监督关系抽取算法虽然可以减少人工标注成本,但是会引入大量的噪声,例如对于下列句子:
1)比尔盖茨创建了微软
2)微软公司的创始人是比尔盖茨
3)比尔盖茨从微软退休
只有前两个句子能体现实体对“比尔盖茨”和“微软”含有“创始人”关系,而最后一个句子会给分类模型带来噪声。目前最好的降噪方法是使用含有相同实体对的句子集合来判断实体对间的关系,该类方法主要是通过降低句子集合中的噪声数据的权重来减少噪声数据的影响。但是该降噪方法无法处理句子集合中所有的句子是噪声数据的情况。
本次paper reading介绍ACL2018上的一篇文章——DSGAN: Generative Adversarial Training for Distant SupervisionRelation Extraction[1],该论文使用了生成式对抗网络对关系抽取任务进行降噪,通过对抗网络获取基于句子层面的生成模型,与传统的对抗网络中用于生成新数据的生成模型不同,这里的生成模型的作用是识别数据集中的噪声数据,对训练集进行降噪来提升关系抽取模型的表现效果。论文的思想可以通过图1解释。已知训练数据中含有错误的数据(红叉)、真实正确的数据(蓝圈)、假阳性数据即噪声数据(黄三角),其中真实正确的数据和假阳性数据在训练开始都被认为是“正确”数据(“positive” data),模型的假设前提是真实正确的数据在正确数据中占据的比例较大。在对抗网络训练过程中,使用判别模型来识别错误数据和“正确”数据;而生成模型将从所有数据中识别真实正确的数据并将这些数据标注为负例,并识别所有的错误数据(包括已知的错误数据和假阳性数据)并标注为正例,将这些标注好的数据加入到判别模型的训练集中用于干扰判别模型。如果生成模型能够很好地分类真实正确的数据和错误数据,那么判别模型的判别效果将会极快地下降,我们将通过判别模型效果的下降情况来确定何时停止对抗网络的训练。对抗网络训练完毕之后,论文使用其中的生成模型作为降噪工具,对现有的数据集进行降噪处理,并将处理好的数据集用于关系分类。
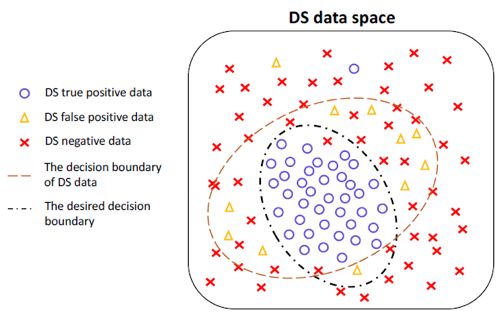
图1
DSGAN是对抗网络在关系抽取降噪任务中的第一次实现,这一降噪模型可以作为插件直接应用于现有的各关系分类的模型中,提升关系分类的效果。
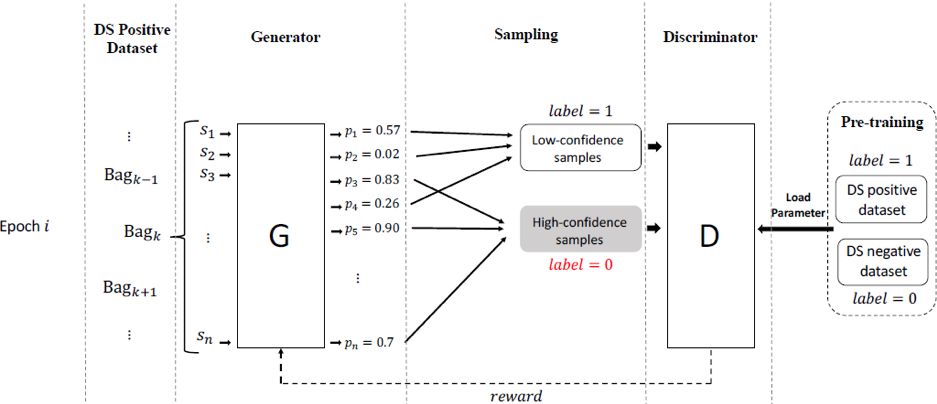
图2
图2为论文中对抗网络的基本框架,包括了生成模型G和判别模型D,这两个模型对应的参数分别为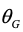
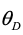
判别网络的目的是判断输入的句子是否为“正确”的数据(包括真实正确的数据和假阳性数据),它的输入是句子的特征,输出为该句子为“正确”的数据的得分。生成网络的目的是识别真实正确的数据,它的输入是句子的特征,输出为该句子为真实正确数据的得分;对于得分大于阈值的数据,将作为错误数据(label=0)输入到判别网络中,而得分低于阈值的数据将作为“正确”的数据(label=1)输入到判别网络,通过这种方式来影响判别网络的分类效果。论文使用判别网络分类效果的下降速度来判断生成模型的质量,如果生成模型识别真实正确的数据的效果越好,那么判别网络的分类效果越差。
生成模型训练完成后,将用于对原始训练集进行降噪。训练集中得分低于阈值的数据将作为噪声数据剔除;而如果所有包含同一实体对的句子的模型得分都低于阈值,那么该实体对及其句子集合将作为其对应关系类别的负例。降噪后的训练集可以应用于任一已有的关系分类模型,使得该模型的表现能够进一步提升。
训练对抗网络前,首先要对生成模型和判别模型进行预训练,生成模型的训练数据包括了正例数据集P和负例数据集NG,判别模型的训练数据包括了正例数据集P和负例数据集ND,这里数据集NG和ND不重合。预训练后判别模型能够很好地区分正例和负例数据;此外,生成模型要对正例数据集P过拟合,这样可以在正式训练时尽可能地干扰判别模型。
正式训练时,将正例数据集P切割成若干个集合(bag),分割后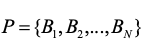
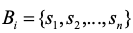
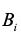
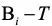
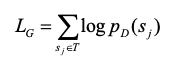
(1)
判别模型的损失函数如公式(2)所示:
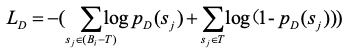
(2)
这里,每输入一个集合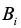
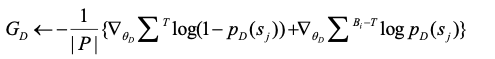
(3)
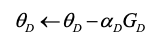
(4)
生成模型的目标和单步强化学习的目标类似,因此,这里使用基于策略的梯度函数来更新生成模型的参数。与强化学习相对应的,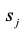
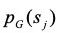
第一,作为对抗网络,我们希望生成模型生成的数据在判别网络中能够得到更高的分数,因此有如公式(5)所示的奖赏函数

(5)
第二,我们将通过判别模型的性能来判断生成模型当前的性能,当生成模型性能越好时它生成的数据将难以被判别模型识别为反例,则判别模型的性能会逐步下降,因此有如公式(6)所示的奖赏函数:
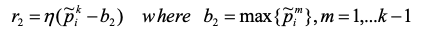
(6)
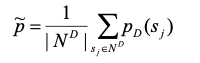
(7)
其中k为当前迭代次数,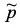
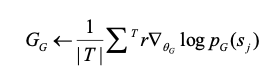
(8)
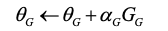
(9)
当所有的集合都输入完毕后计为一轮的迭代,每一轮迭代后,都要计算判别模型在数据集ND上的准确率ACCD,当ACCD不再下降时则停止迭代。
在每一轮迭代之前,判别模型都会重新加载其预训练好的参数,这样做有以下两个原因:第一,训练对抗网络的目的是获得一个鲁棒性强的生成模型而不是获得一个鲁棒性强的判别模型,第二,生成模型的目的是识别出噪声数据而不是生成新数据。这样一来,判别模型很容易崩塌(即判别模型将会无法区别正负例)。对此文中增加了一个衡量对抗网络训练效果的策略:生成模型的鲁棒性越强,在一轮迭代过程中会让初始参数相同的判别模型的表现下降得越快。
实验数据集为Reidel dataset。该数据集是远距离监督关系抽取任务的通用数据集。为了验证DSGAN模型的降噪效果,选取了基于CNN的关系抽取模型[2]和基于PCNN的关系抽取模型[3]作为基准模型,实验对比结果分别如图3和图4所示。
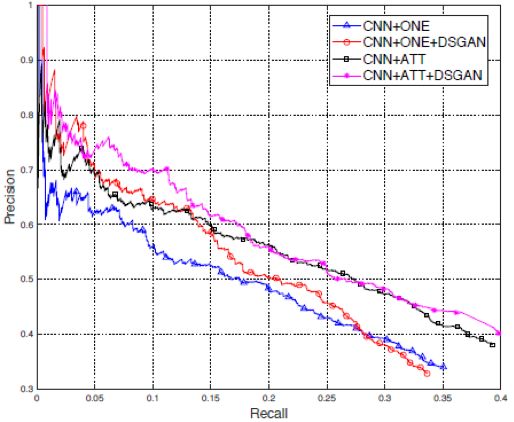
图3
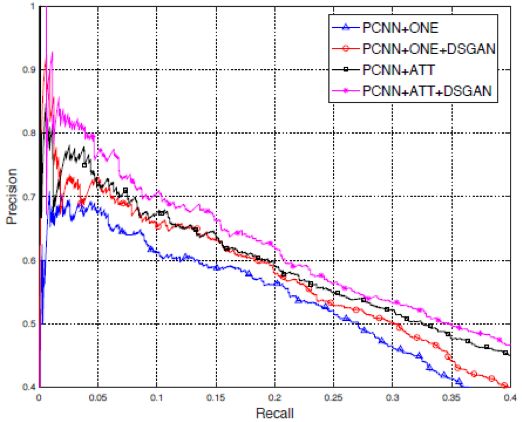
图4
从图中可以看出,经过DSGAN降噪之后,基于CNN和基于PCNN的模型在关系抽取任务上的表现都有着显著的提升。
DSGAN的核心思想是通过对抗网络训练的方法,获取能够识别出噪声数据的生成模型,使用该生成模型对现有的关系抽取数据进行降噪,从而提升模型在关系抽取任务上的表现。该方法只对输入的数据进行处理,因此可以很方便的接入到现有的关系抽取模型中并提升模型的效果。
参考文献
[1] DSGAN: Generative Adversarial Training for DistantSupervision Relation Extraction,
https://arxiv.org/abs/1805.09929
[2] Neural relation extraction with selective attentionover instances,
http://www.aclweb.org/anthology/P16-1200
[3] Distant Supervision for Relation Extraction viaPiecewise Convolutional Neural Networks,
http://www.emnlp2015.org/proceedings/EMNLP/pdf/EMNLP203.pdf

 微信ID:WeChatAI
微信ID:WeChatAI

登录查看更多
相关内容

专知会员服务
64+阅读 · 2020年1月11日
Arxiv
15+阅读 · 2018年5月24日


相关VIP内容
专知会员服务
64+阅读 · 2020年1月11日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年5月24日