面试时让你手推公式不在害怕 | 线性回归
本文阅读时间约10分钟
一、例子
本故事纯属虚构如有雷同那肯定是巧合。
A去银行办信用卡,柜台的漂亮妹子询问:"请问您的年龄和月收入是多少?"A:"20岁,月收入2万元"。妹子:“您可办理的额度为1万元”。此时,B同样办信用卡,妹子同样询问:“请问您的年龄和月收入是多少?”B:“19岁,月收入1.9万元”。妹子:“您可办理的额度为1.1万元”。A此时就郁闷了,我月收入比他高,为什么额度比他低呢。别问为什么!机器算的!那么机器怎么算的呢?这个时候我们就可以拿出机器学习中最基本也是最重要的算法之一线性回归
岁数 月收入/万元 信用卡额度/万元 A 20 2 1 B 19 1.9 1.1 (左右滑动试试)
年龄、工资、信用卡额度)找出来最好的拟合线(面)来进行预测,这样你的数据来了之后直接带入进去就可以得出来该给你多少额度。
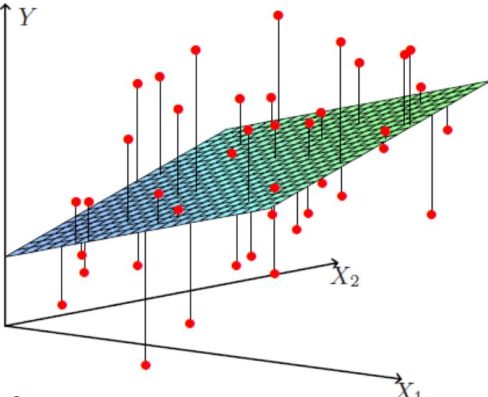
ps:有同学可能说不是线性模型么,咋图是个面呢?
线性不等于直线,特征是一维的,线性模型在二维空间构成一条直线;特征是二维的,线性模型在三维空间中构成一个平面;若特征是三维的,则最终模型在四维空间中构成一个体;以此类推……好呗,后面的需要大家自己想象啦。
二、模型推导
那么,线性回归的原理是什么呢?我们接下来从机器学习的三板斧(模型,代价函数,优化算法)开始分析。
1、模型
假设
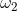
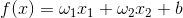
当然实际情况中,银行的漂亮妹妹会让你填大量的信息,也就是模型不止两个特征和参数,可以把模型改写为通用形式:
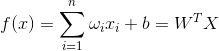
其中,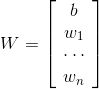
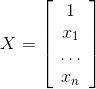
至此我们得到线性回归的模型。
2、代价函数
1.误差项分析:
真实值和预测值之间肯定是存在差异的(用ε来表示误差)也就是说A去银行办信用卡,本应该给1万元,但实际可能给9千或者1万,这样就不可避免的产生误差。对于每个样本:
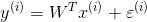
既然说到误差了,咱们就来好好唠一下,首先银行的目标得让误差越小越好,这样才能够使得我们的结果是越准确的。那么这个误差有什么规律可循吗?
误差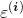
独立:A和B的信用卡额度不会相互影响,不会因为给A额度高了,就给B低。
同分布:都是一家银行,一家预测系统
高斯分布:银行可能会多给,也可能会少给,但是绝大多数情况下这个浮动不会太大,极小情况下浮动会比较大,符合正常情况,所以我们认为该误差是可以服从高斯分布的。
误差项ε是独立且具有相同的分布,服从均值为0方差为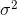
2.推导
(1)预测值和误差:
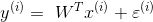
(2)由于误差服从高斯分布:
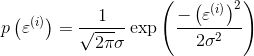
(3)将(1)带入(2):
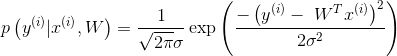
上式的意思就是我去办信用卡,得到的额度恰好是等于真实情况下就该给我这么多的概率。(预测值和真实值对应的可能性大小)那么银行当然希望这个概率越大越好呀,越大代表越准确呀。
(4)又因为设定样本是独立同分布的,对其求似然函数:
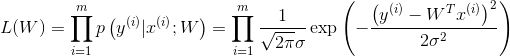
似然函数最大化是为了逼近我们的数据。
(5)上式,是一个累乘,多难求对不对,我们可以转换成加法啊,于是引入对数即,对数似然函数:
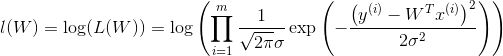
(6)上式展开后得到:
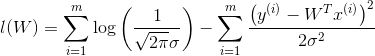
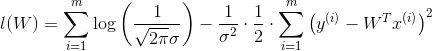
因为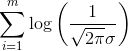
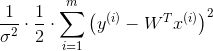
所以,我们定义代价函数:(7)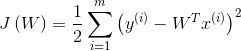

总结:到这里我们终于推导出来了,银行只需要做一件事就可以了,那就是最小化这个函数,其实说白了就是要让我们的预测值和真实值之间的差异越小越好,这就是最小二乘法!
3、优化算法
对损失函数进行优化也就是求出参数w,b,使的损失函数最小化。有两种求解方法:
(1)求导法
对各参数求偏导,并使其偏导为0,进而求出最优的参数。但此方法不适用于不可导函数,且计算量过大。
矩阵求导运算常用公式(有么有很贴心,如果大家记不得可以参考):
首先我们把
展开方便求导:
求上面式子的最小值该怎么办呢?求导啊,另导数等于0
以上就是按矩阵方法优化损失函数,但上面方法有一定的局限性,就是要可逆;下面我们来说一说另外一个优化方法梯度下降法。
(2)梯度下降法
梯度下降法基于的思想为:要找到某函数的极小值,则沿着该函数的梯度方向寻找。若函数为凸函数且约束为凸集,则找到的极小值点则为最小值点。 梯度下降基本算法为: 首先用随机值填充
(这被称为随机初始化),然后逐渐改进,每次步进一步(步长α),每一步都试图降低代价函数,直到算法收敛到最小。这两种方法的优缺点对比:
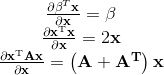
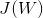
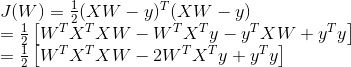
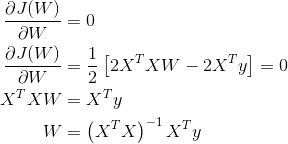
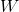
| 梯度下降 | 方程求解 |
|---|---|
| 需要选择学习率,可能由于学习率选择的不合适,导致模型效果差 | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 特征维数较大时,同样适用 | 因为矩阵求逆计算度比较复杂,一般N<10000时可以采用。 |
| 适用于各种模型 | 有局限性,比较逻辑回归就不适用 |
(左右滑动试试)






