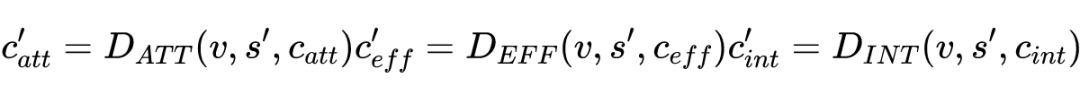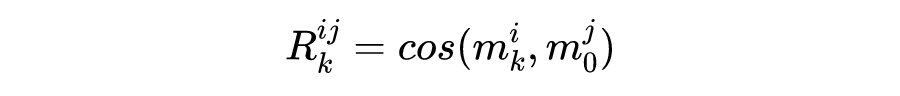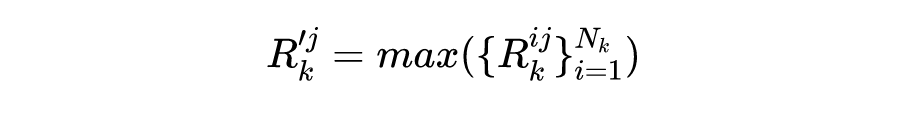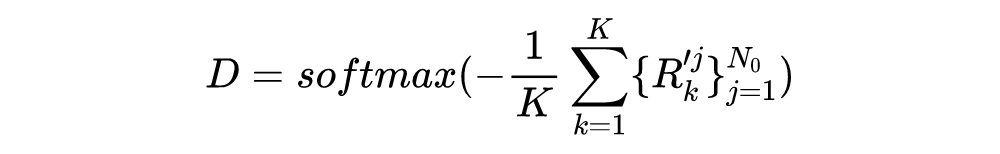![]()
©PaperWeekly 原创 · 作者 | 上杉翔二
单位 | 悠闲会
研究方向 | 信息检索
目前跨模态图像或视频摘要/字幕生成(Image/Video Caption)任务已经得到了很长足的发展,并逐渐内卷化,比如今天出了一篇 Vision Transformer 变体,明天升级到需要百卡训练的大框架。因此,最近的一些文章尝试向外扩展,即不再满足于只在常规的 caption 任务上刷分,而是转于探索各种稀奇古怪,但又有一定实践价值的新任务,比如程序化 caption、多样化 caption、独特化 caption、多视角 caption、常识性 caption、问题控制型 caption。于是本篇文章将整理一下围绕图像/视频字幕化任务的新任务们。
![]()
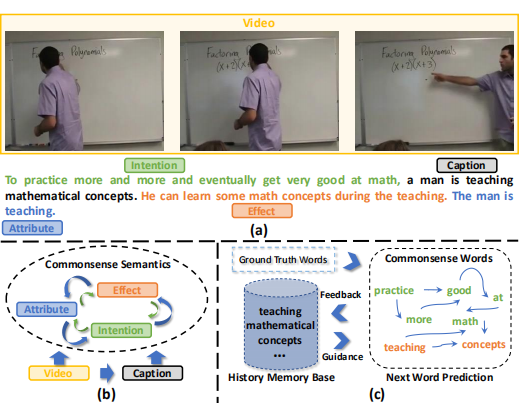
Hybrid Reasoning Network for Video-based Commonsense Captioning 常识性字幕化任务。 从普通的语义理解到高级语义推理上的升级,常识字幕任务旨在在给定一个输入的视频,同时生成字幕和完成常识推理(如上图 a 中的三种颜色,去推理出意图 intention、效果 effect、属性 attribute)。同时很显然这三种常识推理都是有作用的,如图 b 是指人类不仅可以受益于视频和事件的标题,而且还可以准确地预测属性和效果,这证明这种语义层面的推理与不同的常识线索是相互作用的。
因此作者提出一种 Hybrid Reasoning Network,即混合语义层面的推理和词级别的推理(预测下一个词)来提升表现。这样的好处是:
然后具体的模型结构如下图:
![]()
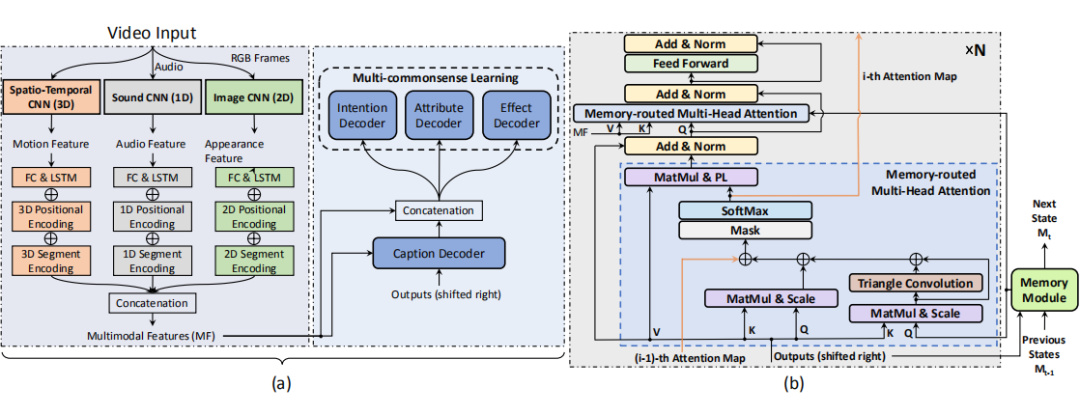
图 a 是整体结果,具体的做法是以视频为输入,然后采用多模态融合将运动特征(红色的时空 CNN 来提取)、音频特征(灰色的 sound CNN 来提取)和外观特征(Image CNN 来提取)合并为多模态特征(MF)。然后将 MF 输入到解码器阶段进行字幕处理,其中包括字幕解码器和三个常识解码器:Intention Decoder,Attribute Decoder,Effect Decoder,做法都类似,
loss 也是直接用交叉熵来算。然后右边的图 b 是记忆路由多头注意力与记忆模块协同进行词级推理,即这个模块将从以前的单词信息中学习,并计算以前的信息和生成过程之间的交互。
![]()
Multi-Perspective Video Captioning 多视角字幕任务。 不同的人可能会用不同的描述对同一视频有不同的看法,这不仅仅是因为视频的不同内容(区域或片段)或者灵活语言,而是观众在解释视频时持有的不同视角。即人类字幕的输出应该同时受到三个因素的影响:视觉方面、语言风格和感知模式。
因此作者首先收集了一个 VidOR-MPVC 数据集,3136 个视频,在一个明确的多角度指导方针下,手动注释了超过 41k 的描述。然后提出 Perspective-Aware Captioner 模型来解决这个新任务,模型上的挑战主要是
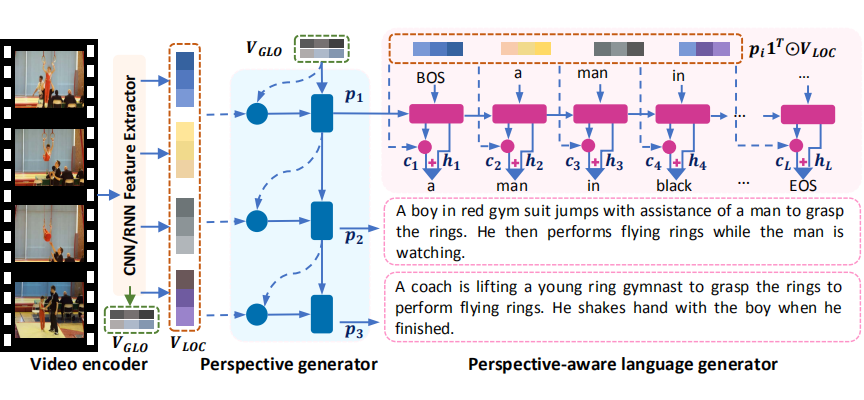
因此使用了 LSTM 来学习可变数量的视角,并灵活地挖掘视频中所有潜在的视角。模型图如下:
![]()
包括三个模块 video encoder, perspective generator 和 perspective-aware language generator。
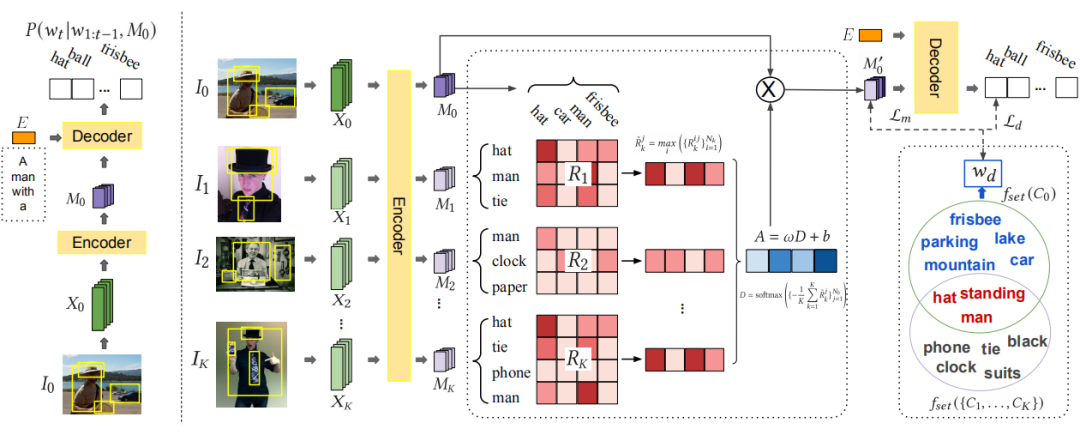
Group-based Distinctive Image Captioning with Memory Attention 独特图像字幕任务。 虽然现有图像字幕生成器可以准确地描述图像,但它们缺乏人类描述图像的独特细节,无法与图像进行区别,即没有独特性。比如上图,简单地提及交通灯而不解释具体的意义(如交通灯的颜色),并不能帮助视障人士决定是否过马路。因此作者提出生成独特性 caption 更有可能突出真正有用的信息。具体来说这种独特性可称为,能够描述图像的独特对象或上下文的能力,以区别于其他语义上相似的图像。
因此作者提出 Group-based Distinctive Captioning Model(GdisCap),通过对一组图像间的独特性加权的对象区域构建记忆向量,然后为组内的图像生成独特的字幕。模块架构图下图:
![]()
模型左边是用 Fast RCNN 得到目标。右边是模型的整体架构,重点主要就是基于组的记忆注意(GMA)模块,如果图像相似性越小则被认为是更独特,所以先算相似度:
![]()
![]()
![]()
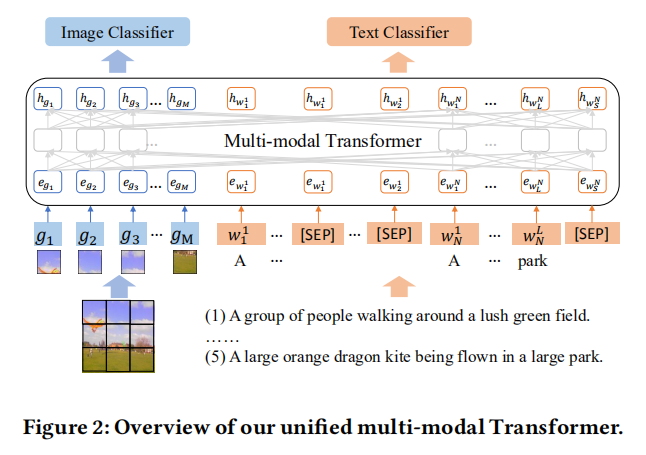
A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation 多样化字幕任务。 目前都是单个图像-文本对的映射,此处存在两个问题。
因此提出双向图像和文本生成任务,以对齐丰富的图像及其相应的多个不同的标题。如上图,该任务旨在统一实现一张图得到多个句子,多个句子生成更适合的图。模型的架构如下图:
![]()
主体是 multi-modal Transformer,然后比较特殊的地方是多句子生成引入不似然训练目标来考虑多个输入标题之间的关系,而图像生成从多个标题构造一个令牌序列作为变压器模型的输入。不过有点遗憾的是,这篇文章是短文所以具体的细节没有披露出来,希望未来能看到作者的完整工作吧。
![]()
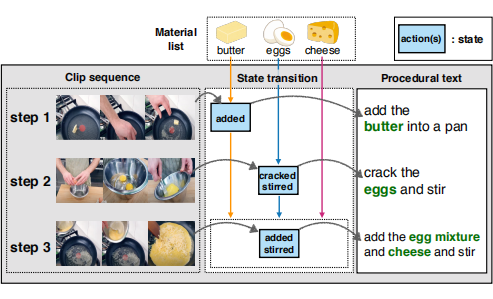
State-aware Video Procedural Captioning 程序字幕任务。 不过这个任务也不算特别新的任务,做的人也算比较多的,不过这篇文章也有对数据集进行新的扩展。首先看看这个任务的目的是从教学视频中生成程序性文本,如先打鸡蛋再搅拌这种一步一步步骤化的输出。而这篇文章主打的 motivation 是材料的状态会依次改变,从而产生状态感知的视觉表现(例如,鸡蛋被转化为破裂的,搅拌的,然后是油炸的形式)。因此如果能跟踪操作后的材料状态,可以更好地关联跨模态关系。
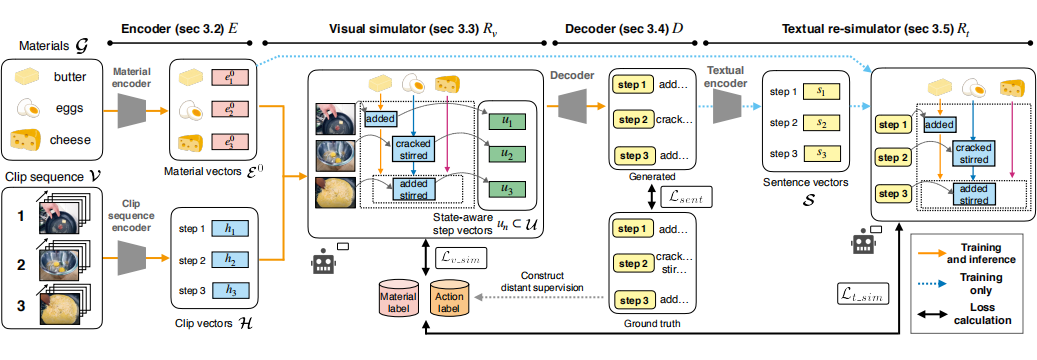
因此给定一个食材列表,并提出一个 simulator 以便于解释过程中材料的状态转换,模型结构如下图所示:
![]()
为了准确地生成程序文本,模型必须跟踪 clip 序列中的材料状态,所以主要看 visual simulator 这里,具体来说一个推理过程为:给定片段和材料列表,视觉模拟器预测执行动作和材料,然后更新材料状态。经过第 n 次推理后输出一个状态感知的步长向量。最后在进行预测时候把 clip 特征,action 特征和 material 特征都当作最后的特征用作生成。
![]()
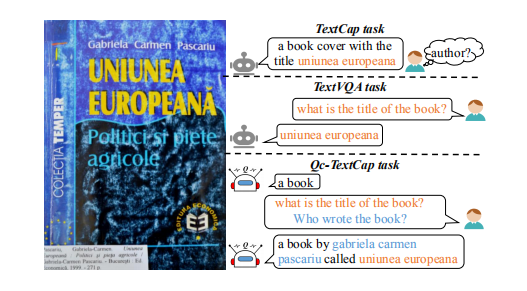
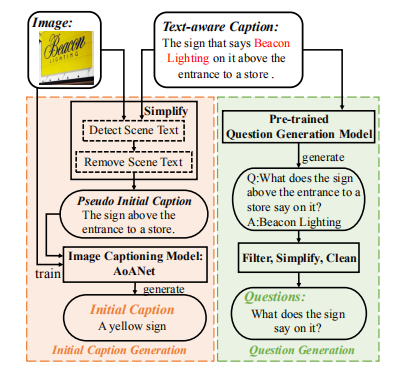
Question-controlled Text-aware Image Captioning 问题控制字幕新任务。 提出这个新任务的动机是:应该对不同需求的人给出不同的描述,特别是当图像中的文本比较多的时候,通常不需要描述图像中的所有文本。比如上图,如果系统先告诉视障用户一个图像的概述描述,即“一本书”,然后让用户与系统交互,获得关于他们感兴趣的场景文本的更具体细节,如“谁写了书”或“书的标题是什么”。通过这种方式,视障用户可以根据自己的兴趣获得更个性化的文本感知字幕。
![]()
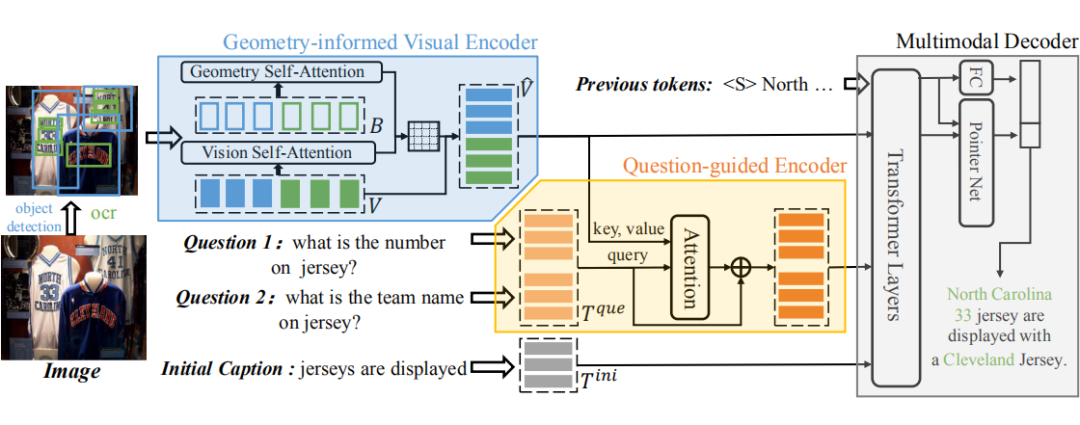
作者还对这个数据集进行了一系列的分析,大家可以自己看原文吧。先直接到 framework 部分,提出的模型 GQAM 由三个模块组成,Geometry-informed Visual Encoder,Question-guided Encoder,Multimodal Decoder。
![]()
简单看看各个模块:
本文整理了关于 image/video caption 的一些变体新任务们,包括程序化 caption、多样化 caption、独特化 caption、多视角 caption、常识性 caption、问题控制型 caption 等等。一个基本的模式都是从实际问题出发,制作一个全新的数据集并提出合理的解决方法,以更贴近真实场景中的需要。这些文章或许也可以给我们带来除了内卷刷分外的新思路,即结合现实去改装一些现有任务并进行扩展,从而实现学术和应用两开花。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()