田渊栋团队新作:模型优化算法和泛化性能的统一解释

新智元报道
新智元报道
来源:arxiv、知乎
编辑:大明
【新智元导读】对神经网络而言,使用同一架构的网络,从不同初始值开始优化,最终的泛化效果可以完全不同。在传统的机器学习中,对优化算法和泛化性能的研究是分开的,但对深度学习这样的非凸问题而言,两者是密不可分的。本文试图对这个问题做出统一的解释。
神经网络有很多异于传统机器学习系统(比如决策树和SVM)的奇特性质。比如说过参化(over-parameterization)时并不会产生过拟合,而只会让测试集上效果变好(泛化能力变好),如果用正好的参数去拟合数据,泛化能力反而变差。比如说有隐式正则化(implicit regularization)的能力,即同样大小的模型,可以完全拟合正常数据,也可以完全拟合随机数据,并且在完全拟合正常数据时自动具有泛化能力。
近日,Facebook人工智能研究院研究员,卡内基梅隆大学机器人系博士田渊栋团队发表新作,试图对这类传统机器学习难以解释的问题做出统一的理论解释。
在本文预印本发布后,田渊栋博士本人在知乎上题为《求道之人,不问寒暑(三)》的专栏文章中,对这篇论文的思想脉络和实现过程做出了精彩的解读,并和读者进行了深入讨论。
经作者授权,新智元全文转载如下:
神经网络有很多异于传统机器学习系统(比如决策树和SVM)的奇特性质。比如说过参化(over-parameterization)时并不会产生过拟合,而只会让测试集上效果变好(泛化能力变好),如果用正好的参数去拟合数据,泛化能力反而变差;比如说它有隐式正则化(implicit regularization)的能力,即同样大小的模型,可以完全拟合正常数据,也可以完全拟合随机数据,并且在完全拟合正常数据时自动具有泛化能力。
这些现象在传统机器学习理论中不太能够得到解释,按照传统理论,用大小恰好的模型去拟合数据集是最优的,更小的模型,其复杂度不够从而无法拟合数据,更大的模型则会过拟合数据,降低其泛化能力,要使大模型有优秀的泛化能力,需要使用正则化方法。按照传统理论,如果一个模型大到能够拟合复杂度更高的随机数据,那它为什么不在正常数据上过拟合?如果一个模型能在正常数据上具有泛化能力,那它不应该能完全拟合随机数据——在神经网络上同时看到这两个现象,是非常奇怪的。
最近ICLR19的最优论文“The Lottery Ticket Hypothesis”(网络权重的彩票现象)又增加了传统理论难以解释的部分——对神经网络而言,使用同一架构的网络,从不同初始值开始优化,最终的泛化效果可以完全不同。 而权重初始值在传统的泛化理论中没有什么地位。因为传统上“优化算法”和“泛化性能”这两件事情是完全分开的。做泛化性能的文章往往假设背后的优化算法能拿到最优解,而不考虑优化的细节;而做优化算法的文章只关心在训练集上的权重到局部极小值的收敛速度,并不关心这个局部极小值在测试集上会有什么效果。如果模型空间有限或者模型的最优参数可以由凸优化得到,那这样做理所当然;但对深度学习这样的非凸问题而言,两者是密不可分的。
这次我们做的这篇文章(arxiv.org/abs/1905.1340)试图提出一个统一的理论来解释这些现象,包括神经网络参数多时效果更好,有动态适应不同数据集的能力,还能解释从不同初始值出发,泛化能力完全不同的网络彩票现象。我们提出的这个理论对这些问题都有比较好的直观解释,并且还有一个统一的数学框架来支撑。
其根本的方案,是将训练时的优化过程和泛化能力结合起来,从而去分析传统方法分析不了的情况。
首先我们采用了教师-学生网络(student-teacher)的框架,假设数据集的标注由一个隐藏的(多层)教师网络(teacher network)生成,然后依据教师网络的输入输出,用梯度下降法去优化学生网络(student network)。学生和教师网络的层数相同,但因为over-parameterization,学生的每一层可以有比教师更多的输出结点(神经元)。在这个框架下,我们证明了在一些情况下的权重复原定理,即学生网络的权重可以收敛于教师网络的对应权重,以及如何靠拢,并且分析了在over-parameterization的情况下学生网络可能的行为。由这些定理,可以给出一些神经网络奇特性质的解释。
对于结构化的数据,其对应生成数据的教师网络较小,过参化得到的学生网络中的结点会优先朝着教师网络的结点收敛过去,并且初始时和教师网络结点重合较大的学生结点(也即是“幸运神经元”,lucky weights/nodes)会收敛得更快,这样就会产生“胜者全拿”的效应,最后每个教师结点可能只有几个幸运学生结点对应。对于随机数据,其对应的教师网络比较大,学生结点会各自分散向不同的教师结点收敛。这就是为什么同样大小的模型可以同时拟合两者。并且因为胜者全拿的效应,学生倾向于用最少的结点去解释教师,从而对结构数据仍然具有泛化能力。
从这些解释出发,大家可能猜到了,“The Lottery Ticket Hypothesis”就是因为lucky nodes/weights的缘故:保留lucky nodes而去除其它不必要的结点,不会让泛化效果变差;但若是只保留lucky nodes,并且重新初始化它们的权重,那相当于中彩者重买彩票,再中彩的概率就很小了。而过参化的目的就是让更多的人去买彩票,这样总会有几个人中彩,最终神经网络的效果,就由它们来保证了——那自然过参化程度越好,最后泛化效果越好。
另外,对过参化的初步分析表明,一方面lucky student weights可以收敛到对应的teacher weights,而大部分无关的student weights/nodes可能会收敛到任意的区域去——但这并不要紧,因为这些结点的上层权重会收敛到零,以减少它们对网络输出的影响。这就附带解释了为何神经网络训练后的解往往具有平坦极小值(Flat Minima)性质:对无关的学生结点而言,任意改变它们的权重,对网络输出都没有太大影响。
具体细节是怎么做的呢?如果大家有兴趣的话,可以继续看下去。
虽然学生网络接收到的信号只来自于教师的最终输出层,对教师中间层如何输出毫无知觉,但因为教师的前向传递和学生的反向传递算法,教师中间层和对应的学生中间层,这两者其实是有隐含联系的。这篇文章首先找到了一个学生网络-教师网络的一个很有趣的对应关系,即学生中间层收集到的梯度和对应教师层输出的关系,然后借着这个对应关系,就可以找到学生网络的权重和教师网络的权重的对应关系。在此之上,再加一些基本假设,就可以有相应的权重复原定理。
这篇文章的基本假设很简单,即教师同层两个神经元同时被激活的概率远远小于各自单独被激活的概率。这个假设相对来说是比较实际的:如果每个神经元只负责输入信号的某个特性,那这些特性同时出现的概率相比单独出现的概率要小很多。那么如何检查这个假设呢?很简单,按照这个假设,如果输入是零均值分布,假设激活函数是ReLU,那神经元的bias就应当是负的,这样它只对输入的一小部分数据有正响应。事实似乎确实如此,我们在文章中检查了VGG11/16这两个在ImageNet上的预训练网络(都采用Conv-BN-ReLU架构)的BatchNorm层的bias,发现绝大部分都是负的,也就是说在训练后网络里的那些神经元确实每个负责不一样的特性。
与之前平均场(Mean Field)的一系列文章相比,这篇文章不需要假设权重满足独立同分布这个非常严格且只在初始化时才成立的条件,可以用于分析网络优化的整个过程,事实上,我一直觉得多层神经网络的优化过程和平均场或者热力学的箭头是相反的:热力学里系统从非平衡点到达平衡点的过程是抹消结构的过程,而神经网络的优化是从随机初始的权重中创造并且强化结构的过程。这篇文章曾经打算投去年的ICML,原本的题目叫作“潘多拉的盒子”,也就是说,从随机涨落的权重中,依着不同的数据集,可以收敛出任意的结构出来,但因为OpenGo的项目一直拖,一直到一年半以后才有比较初步的结果。
另一个附带的结果是,从这篇文章的分析里可以比较清楚地看到“上层调制”这种机制的作用。很多人对多层神经网络的疑问是:既然多层神经网络号称是对输入特征进行不断组合以获得效果更好的高层特征,那为什么不可以采用自底向上的机制,每次单独训练一层,等训练完再建上一层?依据这篇文章,回答是如果没有上层的监督信号,那底层的特征组合数量会指数级增长,并且生成的特征大多是对上层任务无用的。唯有优化时不停听取来自上层的信号,有针对性地进行组合,才可以以极高的效率获得特定任务的重要特征。而对权重的随机初始化,是赋予它们在优化时滑向任意组合的能力。
原文链接:
https://zhuanlan.zhihu.com/p/67782029

以下是新智元对论文内容的简编:
本文分析了深度ReLU网络的训练动态过程及其对泛化能力的影响。使用教师和学生的设置,我们发现隐藏学生节点接收的梯度,和深度ReLU网络的教师节点激活之间存在新的关系。通过这种关系,我们证明了两点:(1)权重初始化为接近教师节点的学生节点,会以更快的速度向教师节点收敛,(2)在过参数化的环境中,当一小部分幸运节点收敛到教师节点时,其他节点的fan-out权重收敛为零。
在本文中,我们提出了多层ReLU网络的理论框架。该框架提供了对深度学习中的多种令人费解的现象的观察,如过度参数化,隐式正则化,彩票问题等。
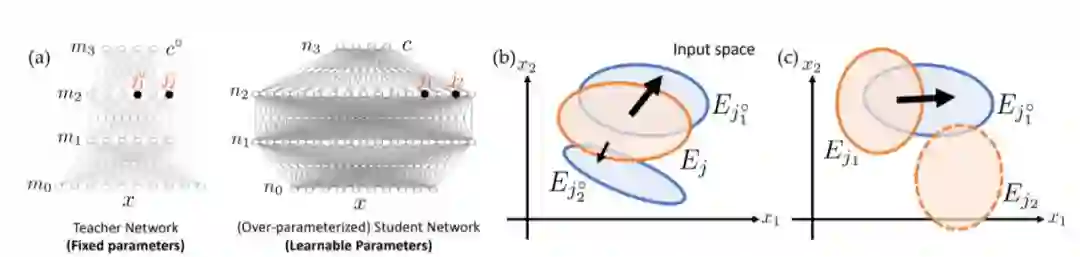
图1

图2
基于这个框架,我们试图用统一的观点来解释这些令人费解的经验现象。本文使用师生设置,其中给过度参数化的深度学生ReLU网络的标签,是具有相同深度和未知权重的固定教师ReLU网络的输出(图1(a))。在这个角度来看,隐藏的学生节点将随机初始化为不同的激活区域。(图2(a))。
依托这个框架,本研究主要解决以下几个问题:
拟合
结构化和随机数据。在梯度下降动态下,一些学生节点恰好与教师节点重叠,将进入教师节点并覆盖教师节点。不管对于中间节点数量较少的小型教师网络的结构化数据,或者对具有中间节点数量较多的大型教师网络的随机数据,情况都是如此。这也解释了为什么同一个网络可以同时适应结构化和随机数据(图2(a-b))。
过参数化
在过度参数化中,许多学生节点在每一层进行随机初始化。任何教师节点都更可能与某些学生节点有很大部分的重叠,这会导致快速收敛(图2(a)和(c),)。这也解释了为什么网络容量恰好适合数据的训练模型的性能表现会更差。
平滑极小值问题
深层网络经常会收敛到“平滑极小值”。此外,虽然存在争议,平滑极小值似乎意味着良好的泛化能力,而尖锐的极小值往往导致不良的泛化能力。
而在我们的理论中,在与结构化数据进行拟合时,只有少数幸运的学生节点收敛至教师节点,而对于其他节点,他们的fan-out权重缩小为零,使得它们与最终结果无关,产生平滑极小值,学生节点沿大多数维度上(“不幸节点”)的运动导致输出变化最小。另一方面,尖锐的极小值与噪声数据有关(图2(d)),更多的学生节点能够与教师节点相匹配。
隐式正则化
另一方面,捕捉行为强制执行赢者通吃规则:在优化之后,教师节点会被少数学生节点完全覆盖(即解释),而不是由于过度参数化而在学生节点之间分裂。这解释了为什么同一网络一旦经过结构化数据训练,就可以推广到测试集。
彩票现象
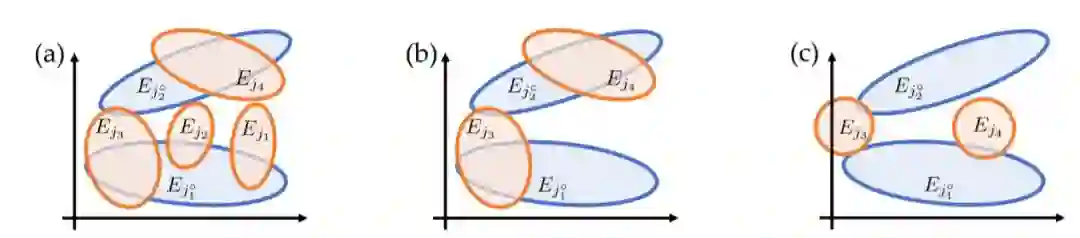
图3
如果我们将“显著权重”(大幅度训练的权重)重置为优化前的值,但在初始化之后,对其他权重进行压缩(比例通常大于总权重的90%)并重新训练模型,结果性能相当或更好。如果我们重新初始化显著权重,测试性能会更差。在我们的理论中,显著权重是一些幸运区域(图3中的Ej3和Ej4),它们在初始化后恰好与一些教师节点重叠并在优化中收敛教师节点。
因此,如果我们重置显著权重并修剪其他权重,它们仍然可以收敛到同一组教师节点上,并且由于与其他不相关节点的干扰较少,可能实现更好的性能。但是,如果我们重新初始化,最终这些节点可能会落入那些不能覆盖教师节点的不利区域,从而导致性能不佳(图3(c)),就像参数化不足时的表现一样。
我们对全连接(FC)网络和卷积网络都进行了评估。对于全连接网络,使用大小为50-75-100-125的ReLU教师网络。对于卷积网络,使用大小为64-64-64-64的教师网络。学生网络的深度与教师网络相同,但每层的节点/通道是前者的10倍,因此它们是过度参数化的。添加BatchNorm时,会在ReLU之后添加。
本文采用两种量度来衡量对一些幸运的学生节点收敛至教师节点情况的预测:
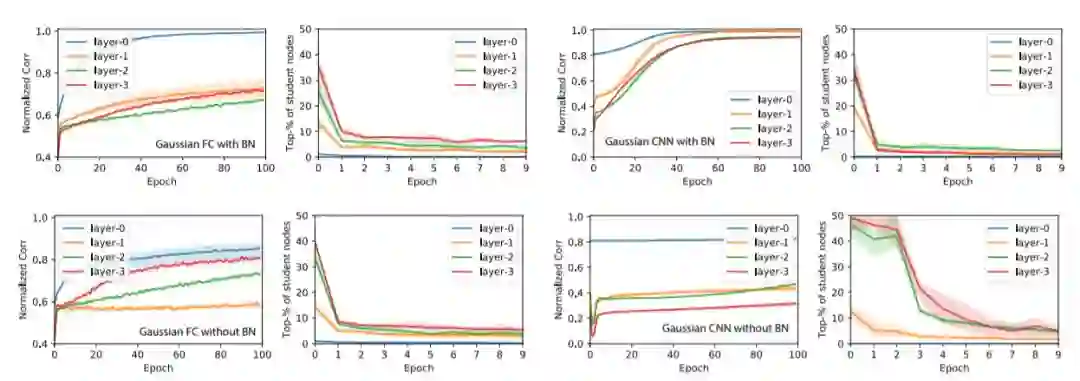
图4:归一化相关度ρ¯和平均排名r¯在GAUS训练集上随epoch的变化
归一化相关度ρ¯
我们计算出在验证集上评估的教师和学生激活之间的归一化相关度(或余弦相似度)ρ。在每一层中,我们对教师节点上的最佳相关度进行平均得到ρ¯,ρ¯≈1表示大多数教师节点至少由一名学生覆盖。
平均排名r¯
训练后,每个教师节点j◦都具备了相关度最高的学生节点j。这时对j的相关度等级进行检测,并归一化为[0,1](0 表示排名第一),回到初始化和不同的epoch阶段,并在教师节点上进行平均化,产生平均排名r¯。r¯值较小意味着最初与教师节点保持高相关度的学生节点一直将这一领先保持至训练结束。
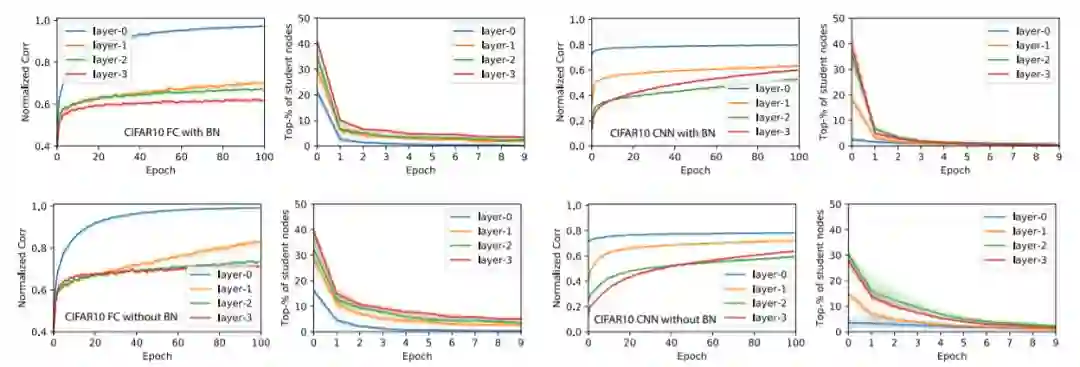
图5:将图4的实验在CIFAR-10数据集上进行的结果
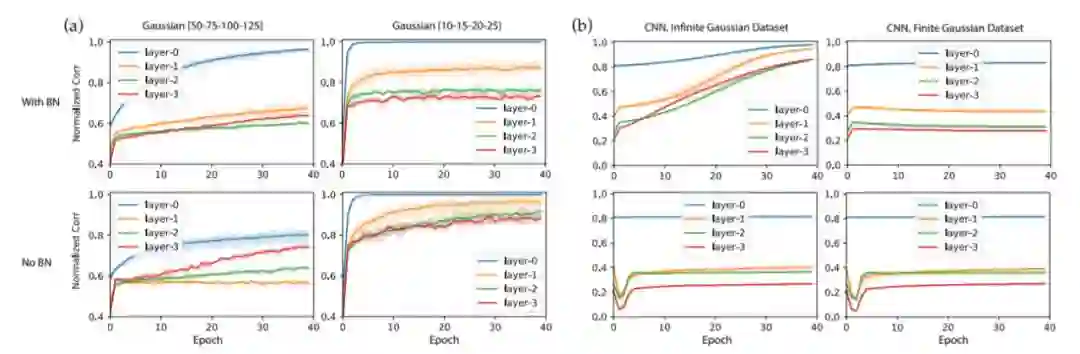
图6:在GAUS数据集上的Ablation学习结果
关于教师网络的大小:对于小型教师网络(10-15-20-25,全连接网络),收敛速度要快得多,不使用BatchNorm的训练比使用BatchNorm训练要快。 对于大型教师网络,BatchNorm肯定会提高收敛速度和ρ¯的增长。
关于有限与无限数据集:我们还在卷积神经网络的案例中使用预生成的GAUS有限数据集重复实验,并发现节点相似性的收敛在几次迭代后终止。这是因为一些节点在其激活区域中接收的数据点非常少,这对于无限数据集来说不是问题。我们怀疑这可能是CIFAR-10作为有限数据集没有表现出GAUS类似行为的原因。
论文链接:
https://arxiv.org/pdf/1905.13405.pdf
知乎专栏:
https://zhuanlan.zhihu.com/p/67782029


