CVPR2019 | 旷视研究院提出用于全景分割的端到端闭环网络OANet
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:旷视研究院
全球计算机视觉三大顶级会议之一 CVPR 2019 将于当地时间 6 月 16-20 日在美国洛杉矶举办。届时,旷视研究院将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会介绍一篇被 CVPR 2019 接收的论文,本文是第 10 篇,旷视研究院提出一个用于全景分割的端到端闭环网络——OANet,作为一个单一网络,它可有效而高效地同时进行前景与背景分割。
全球计算机视觉三大顶级会议之一 CVPR 2019 将于当地时间 6 月 16-20 日在美国洛杉矶举办。届时,旷视研究院将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会介绍一篇被 CVPR 2019 接收的论文,本文是第 10 篇,旷视研究院提出一个用于全景分割的端到端闭环网络——OANet,作为一个单一网络,它可有效而高效地同时进行前景与背景分割。


导语
简介
模型
端到端架构
空间排序模块
实验
结论
参考文献
往期解读
导读
全景分割,不仅要为图像的每一个像素打上分类标签,同时还要分割出每一个目标实例,给予像素点实例 ID 信息,这无疑充满挑战性。一般来讲,现有的全景分割方法通常使用两个独立的模型,导致 pipeline 复杂、低效且难执行。此外,在两个独立模型预测融合的过程中,启发式方法的引入也成效不大,因为没有充足的语义信息,较难确定目标实例之间的重叠关系。
为此,旷视研究院提出一个用于全景分割的端到端闭环网络——OANet,作为一个单一网络,它可快速、有效地同时进行前景分割(Instance Segmentation)与背景分割(Stuff Segmentation)。此外,一个全新的空间排序模块被引入,以处理已预测实例之间的遮挡问题。大量实验证明了 OANet 的性能,并在 COCO 全景分割基准上取得了有竞争力的结果。
简介
全景分割是场景理解之中一个充满挑战的课题。先前的全景分割方法通常包含三个独立的组件:1)前景分割模块; 2)背景分割模块以及 3)融合(merging)模块。如图 1(a)所示。
通常在上述算法中,前景和背景分割模块是相互独立的,并不共享特征。这显著增加了整体计算量。接着,由于相互独立,这些算法不得不借助后处理融合相应的独立的预测。
但是,由于没有前景和背景之间的语境信息,融合的过程有可能造成两者的重叠。如上所述,仅通过这三个独立的部分,很难把这一算法做工业应用。
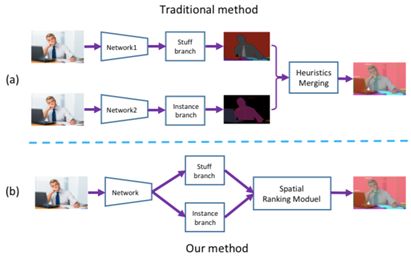
图 1:传统方法与本文方法对比图示
旷视研究院提出一种全新的端到端算法,如图 1(b)所示。据知,这是首个以端到端方式解决上述问题的算法。具体而言,研究员把前景分割和背景分割整合进一个网络,该网络共享 Backbone 特征,但是前景和背景分割任务会应用不同的 Head。
在训练阶段,Backbone 特征将通过背景和前景监督的累加的损失被优化,而 Head 只根据具体任务微调。
为解决重合问题,研究员引入一个新算法,称之为空间排序模块(Spatial Ranking Module)。该模块学习排序分值,并为子任务的融合算法提供排序依据。
模型
本文算法如图 2 所示。它包含 3 个主要的组件:1)背景分支,预测整个输入的背景分割;2)前景分支,提供前景分割的预测;3)空间排序模块,为每个实例生成一个排序分值。
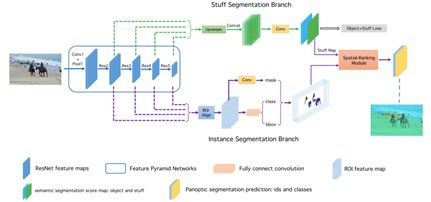
图 2:本文方法整体框架图示
端到端网络架构
本文把 FPN 用作这一端到端网络的 Backbone。对于实例分割,研究员采用原始的 Mask R-CNN 作为网络框架,采用自上而下的路径和横向连接以获得特征图。接着,添加一个 3 × 3 卷积层以获得 RPN 特征图。在此之后,研究员应用 ROIAlign 层以提取 Proposal 特征,并获得 3 个预测。
在背景分割方面,2 个 3 × 3 卷积层接入在 RPN 特征图上。图 3 给出了背景分支的细节。训练期间,由于物体的辅助性信息可以为背景分割预测提供语境,研究员可同时监督背景分割与前景分割。推断时,研究员只提取背景分割的预测,并将其归一化为概率。
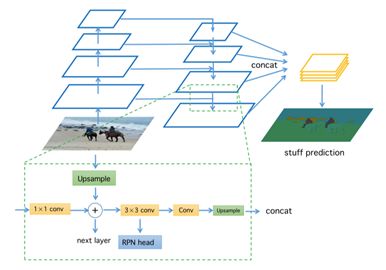
图 3:背景分割模块图示
为打破训练期间的信息流屏障,使整个 Pipeline 更加高效,研究员会共享来自两个分支的 Backbone 的特征。实践中,研究员发现,共享的特征越多,性能越好。因此,研究员共享 Skip-Connection 层之前的特征图,即 RPN Head 之前的 3 × 3 卷积层,如图 3 所示。
空间排序模块
在全景分割任务中,由于一张图像中每个像素的语义信息是确定的,因此预测过程中产生的重叠问题,或者说一个像素的多重分配问题,是一个较为重要且需要被解决的问题。
一般而言,可以按照检测分值降序排列实例,但是这一启发式算法在实际中很容易失败。比如,一个打领带的人,如图 7 所示。在 COCO 数据集中,由于人的类别比领带的出现频率更高,因此根据上述简单的原则,领带会被人遮住,导致性能下降。

图 7:空间排序模块的可视化结果
为解决这一问题,旷视研究员从语义分割方法汲取灵感,提出一个简单,但是非常高效的算法解决遮挡问题——称之为空间排序模块,如图 4 所示。
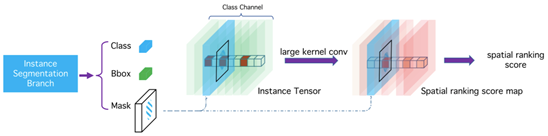
图 4:空间排序分值图预测的图示
在最后,研究员将使用逐像素的交叉熵损失优化排序分值图,如等式 2 所示。
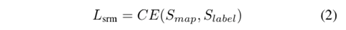
获得排序分值图之后,接着是计算每个实例目标的排序分值,如等式 3 所示。
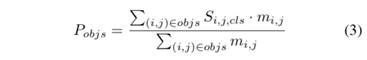
实验
为提高网络全景预测效果,旷视研究员对各环节进行了分析与实验。首先,研究员对背景分割分支的监督信号进行了剥离实验,如表 1 所示。实验表明,同时进行 Object 类别与 Stuff 类别的监督训练,可为背景分割提供更多的上下文信息,改进预测结果。
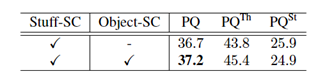
表 1:stuff segmentation 监督信号探究实验
为了探究 Object 前景分割子分支与背景分割子分支的共享特征方式,研究员设计了不同的共享结构并进行实验,如表 2 所示。实验表明,共享基础模型特征与 FPN 结构的连接处特征,能够提高全景分割指标 PQ 。
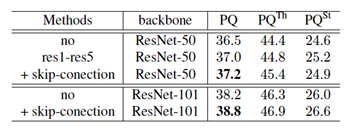
表2:共享基础模型特征探究实验
为验证空间排序模块算法的有效性,研究员在不同的基础模型下进行了实验,如表 3 所示。其中,w/ spatial ranking module 表示使用论文提出的空间排序模块得到的结果,从实验结果中可以看到,空间排序模块能够在不同的基础模型下大幅提高全景分割的评测结果。

表 3:空间排序模块有效性验证实验
为了探究卷积感受野参数对空间排序模块算法的影响,研究员使用不同参数的卷积实现,如表 4 所示。结果表明,提高卷积的感受野可以帮助网络学习更多的上下文特征,从而更好地预测遮挡关系,提高算法性能。
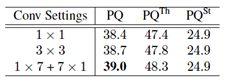
表 4:空间排序模块感受野大小探究实验
如表 5 所示,研究员对论文提出的算法与现有公开指标进行了比较,由结果可知,论文提出的算法能够取得最优的结果。
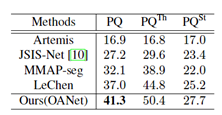
表 5:不同论文方法结果对比
结论
旷视研究院提出一种全新的端到端闭环算法,把语义分割和实例分割整合进一个模型。为了更好地发挥监督的作用,减少计算资源的消耗,在探究了不同形式的特征共享结构后,旷视研究员提出了一种简单有效的共享特征结构,减少参数,同时提升模型性能。
此外,旷视研究员还发现全景分割特有的排序问题,并设计简单而高效的空间排序模块针对性解决该问题。实验结果表明,相较于其他同类模型,该方法取得了当前最佳结果。
参考文献
A. Kirillov, K. He, R. B. Girshick, C. Rother, and P. Dolla ́r. Panoptic segmentation. CoRR, abs/1801.00868, 2018.
K. He, G. Gkioxari, P. Dolla ́r, and R. Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Con- ference on, pages 2980–2988. IEEE, 2017.
T.-Y. Lin, P. Dolla ́r, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie. Feature pyramid networks for object detec- tion. In CVPR, volume 1, page 4, 2017.
J. Dai, K. He, and J. Sun. Instance-aware semantic segmen- tation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 3150–3158, 2016.
Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In 2017 IEEE Con- ference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 4438– 4446, 2017.
CVer-图像分割群
扫码添加CVer助手,可申请加入CVer-图像分割群。一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡)

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!



