为什么要做特征缩放,怎么做特征缩放,什么时候做特征缩放?特征缩放三连了解一下!
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源
作者:Sud
编译:
在使用某些算法时,特征缩放可能会使结果发生很大变化,而在其他算法中影响很小或没有影响。为了理解这一点,让我们看看为什么需要缩放特征、各种缩放方法以及什么时候应该对特征进行尺度缩放。
为什么要做特征缩放
大多数情况下,你的数据集将包含在大小、单位和范围上差别很大的特征。但是,由于大多数机器学习算法在计算中使用两个数据点之间的欧氏距离,这会是一个问题。
如果不加考虑,这些算法只考虑特征的大小而忽略了单位。在5kg和5000gms不同的单元之间,结果会有很大的差异。在距离计算中,大尺度的特征比小尺度的特征要重要得多。

为了抑制这种效果,我们需要将所有特征都处理成相同的级别。这可以通过缩放来实现。
如何对特征进行缩放
有4中常用的方法可以来做特征的缩放。
1. 标准化:
标准化将值替换为z-score。
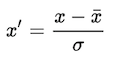
这个重新分布的特征意味着μ= 0和标准偏差σ= 1,sklearn.preprocessing.scale可以帮助我们在python中实现标准化。
2. 均值归一化:
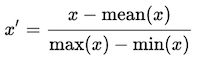
这个分布的值域为[-1,1],μ=0。
标准化和均值归一化可用于假设中心数据为零的算法,如主成分分析(PCA).
3. 最小-最大值缩放:
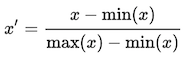
这种缩放使值介于0和1之间。
4. 单位向量化:
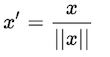
这个缩放考虑到将整个特征向量归一化到单位长度。
最小-最大缩放和单位向量化技术产生的值范围为[0,1]。当处理带有硬边界的特征时,这非常有用。例如,在处理图像数据时,颜色的范围只能从0到255。
什么时候进行特征缩放
我在这里遵循的经验法则是任何计算距离或假设正常的算法,缩放你的特征!!
一些算法的例子,其中的特征缩放是很重要的:
k-最近邻具有欧氏距离度量,对大小敏感,因此应该对所有特征进行缩放,使其尺度相同。
主成分分析(PCA),缩放是关键。主成分分析试图得到方差最大的特征,对于高幅值特征,方差较大。这使得PCA倾向于高幅值特征。
梯度下降可以通过缩放进行加速。这是因为θ在小尺度上会下降的很快,在大尺度上会很慢,所以,变量尺度不均匀的时候,在最优化的路径上会有震荡,效率下降。
基于树的模型不是基于距离的模型,可以处理不同范围的特性。因此,建模树时不需要缩放。
线性判别分析(LDA)、朴素贝叶斯等算法设计的时候就准备好了处理这一问题,并相应地赋予特征权重。在这些算法中执行特征缩放可能没有多大效果。
好了,希望你能理解为什么,如何和何时进行特征缩放。

英文原文:https://medium.com/greyatom/why-how-and-when-to-scale-your-features-4b30ab09db5e
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




