独家 | 一文带你读懂特征工程!

作者:Bhalchandra Madhekar
翻译:陈之炎
校对:张玲
本文约1800字,建议阅读7分钟。
本文描述了一个典型的基于跨行业标准流程的标准机器学习管道,作为数据挖掘行业的标准过程模型。
无论它的规模和大小如何,数据已经成为现代企业、公司和组织的一流资产。任何一个智能系统都需要数据驱动,无论它多复杂。每个智能系统的核心,均有一个或多个基于某种数据学习方法的算法,例如机器学习、深度学习或统计方法,它们利用这些数据来生成知识,并在一段时间内提供智能洞察。
算法本身是非常通用的,但无法在普通原始数据上有效发挥作用。因此,需要从原始数据中提取有意义的特征,我们才能够理解和使用这些数据。
任何一个智能数据洞察系统基本上都由端到端的管道组成:
先是获取原始数据;
然后利用数据处理技术,从这些数据中获取、处理和提取有意义的特征和属性;
最后,通常利用统计模型或机器学习模型等技术对这些特征进行建模。
如果有必要的话,还需要根据手头要解决的问题部署该模型以供将来使用。
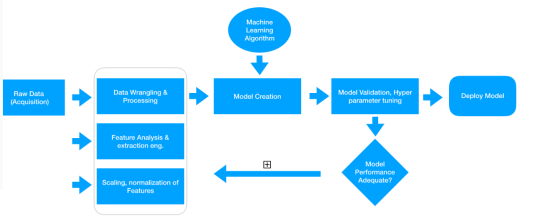
获取原始数据后,直接在数据之上构建模型是鲁莽的,因为我们无法从普通原始数据中获得想要的结果或性能,而且算法本身也不会自动从中提取有意义的特征。在上图中指出的数据准备方面,在对原始数据进行必要的清洗、预处理分析之后,便可以采用多种方法从中提取有意义的属性或特征。特征工程是一门艺术,也是一门科学,这也是为什么数据科学家在建模之前通常会把70%的时间花在数据准备上。
“特征工程是将原始数据转化为特征的过程,这些特征可以更好地向预测模型描述潜在问题,从而提高模型对未见数据的准确性。”
-Jason Brownlee博士
这让我们深入了解了为什么特征工程是一个将数据转化成作为机器学习模型输入的特征的过程,换句话说,高质量的特征有助于提高模型整体的性能和准确性。特征在很大程度上与基本问题相关联。
因此,即使机器学习任务在不同的场景中可能是相同的,比如将物联网事件分类为正常和异常行为,或者将客户情绪分类,但每个场景中提取的特征都会有很大的不同。
什么是特征?
特征通常是建立在原始数据之上的特定表示,它是一个单独的可测量属性,通常用数据集中的列表示。对于一个通用的二维数据集,每个观测值由一行表示,每个特征由一列表示,对于每一个观测具有一个特定的值。
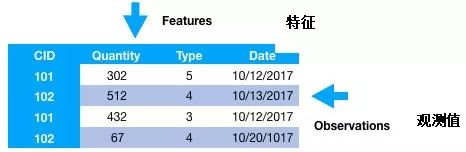
因此,就像上图中的例子一样,每行通常表示一个特征向量,所有观察到的全部特征集形成一个二维特征矩阵,也称为特征集。这类似于用来表示二维数据的数据框或电子表格。机器学习算法通常与这些数值矩阵或张量一起工作,因此绝大多数特征工程技术都是将原始数据转换为一些数值表达,以便算法理解。
基于数据集的特征可以分为两大类:
固有的原始特征是直接从数据集获得的,没有额外的数据操作。
派生特征通常是从特征工程中获得的,是从现有的数据属性中提取出来的特征。
举一个简单的例子:通过将当前日期减去订单日期,可以从包含“订单日期”的订单数据集中创建一个新的“订单履行日期”。另一方面,在特定的深度学习算法中,特征通常比较简单,因为算法本身会内部转化数据。这种方法需要的数据量会比较大,并以牺牲解释性为代价。然而,在图像处理或自然语言处理用例中,这样的折中方法往往是值得的。
对于公司面临的大多数其他用例,例如预测分析,特征工程是将数据转换成机器学习所需要的格式。特征的选择对模型的解释性和性能都至关重要。如果没有特征工程,今天的大公司就无法部署精确的机器学习系统。
特征工程
数值数据通常以标量值的形式描述观测、记录或测量数据。在这里,我们所说的数值数据是指连续数据,而不是通常用来表示分类数据的离散数据。数值数据也可以是向量值,其中向量中的每个值或实体都可以表示一个特定的特征。整数和浮点数是连续数值数据中最常见和最广泛使用的数值数据类型。
即使数值数据可以直接输入机器学习模型,在构建模型之前,仍然需要设计与场景、问题和领域相关的特征。因此,对特性工程的需求仍然存在。
原文标题:Feature Engineering
原文链接:https://dzone.com/articles/feature-engineering-1
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织





