树形结构为什么不需要归一化?


树形结构为什么不需要归一化?
解析:
因为数值缩放不影响分裂点位置,对树模型的结构不造成影响。
按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。
而且,树模型是不能进行梯度下降的,因为构建树模型(回归树)寻找最优点时是通过寻找最优分裂点完成的,因此树模型是阶跃的,阶跃点是不可导的,并且求导没意义,也就不需要归一化。
既然树形结构(如决策树、RF)不需要归一化,那为何非树形结构比如Adaboost、SVM、LR、Knn、KMeans之类则需要归一化呢?
对于线性模型,特征值差别很大时,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,运用梯度下降的时候,损失等高线是椭圆形,需要进行多次迭代才能到达最优点。
但是如果进行了归一化,那么等高线就是圆形的,促使SGD往原点迭代,从而导致需要的迭代次数较少。
除了归一化,我们还会经常提到标准化,那到底什么是标准化和归一化呢?
标准化:特征均值为0,方差为1
公式:
归一化:把每个特征向量(特别是奇异样本数据)的值都缩放到相同数值范围,如[0,1]或[-1,1]。
最常用的归一化形式就是将特征向量调整为L1范数(就是绝对值相加),使特征向量的数值之和为1。
而L2范数就是欧几里得之和。
data_normalized = preprocessing.normalize( data , norm="L1" )
公式:
这个方法经常用于确保数据点没有因为特征的基本性质而产生较大差异,即确保数据处于同一数量级(同一量纲),提高不同特征数据的可比性。
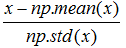
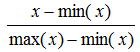
END

今日学习推荐
【机器学习集训营第八期】
火热报名中
2019年5月6日开课
前160人特惠价:15399
报名加送18VIP
[包2018全年在线课程和全年GPU]
且两人及两人以上组团还能各减500元
有意的亲们抓紧时间喽
咨询/报名/组团可添加微信客服
julyedukefu_02
扫描下方二维码
免费试听↓

试听为PC端页面,手机使用舒适度会略逊
可点阅读原文进入手机端页面


后台回复:100 免费领取【机器学习面试100题】
后台回复:干货 免费领取【全体系人工智能学习资料】
后台回复: 领资料 【NLP工程师必备干货资料】








