为什么说GAN很快就要替代现有摄影技术了?

来源:新智元
作者:Jamshed Khan
【导读】自GAN诞生以来,在计算机视觉领域中表现可谓是惊艳连连:文本-图像转换、域迁移、图像修复/拓展、人脸合成甚至是细微表情的改变,无所不能。本文对此进行了盘点,并且作者表示:GAN很快就可能替代现有的摄影技术了!
AI生成的图像可能会取代现有的摄影技术。
许多人当听到“人工智能”、“机器学习”或者“bot”的时候,首先浮现在脑海当中的应当是科幻片中经常出现、未来感十足的既会走路又会说话的机器人。

但事实并非如此!人工智能已经“潜伏”在我们身边很多年了。现在就有可能在你的智能手机里(Siri/谷歌语音助手)、汽车GPS系统里。
然而,在过去几年中,没有哪个域比计算机视觉更受其影响。
随着科技的发展,具有超高分辨率视觉吸引力的图像变得越来越普遍。人们不再需要学习如何使用Photoshop和CorelDRAW等工具来增强和修改图像,因为AI可以在这些方面产生最佳效果的图像。然而,最新提出的想法实际上是综合使用AI来生成图像。
以往我们所看到的所有图像,其生成过程肯定都或多或少有“人”的参与。但是试想一下,一个计算机程序可以从零开始绘制你想要它绘制的任何内容,在不久的将来,你只需要给它一些指令,例如“我想要一张站在埃菲尔铁塔旁边的照片”,然后图像就生成了(当然,你的输入要准确)!

生成对抗网络(GAN)
“在机器学习过去的10年里,GAN是最有趣的一个想法。”
——Yann LeCun
生成这种合成图像的基础就是生成对抗网络(GAN)。
自从Ian Goodfellow和他的同事在2014年发现并推出他们的研究论文以来,GAN一直是深度学习中最迷人且被最广泛使用的技术之一。这项技术无穷无尽的应用,也就是所谓对抗性训练的核心,不仅包括计算机视觉,还包括数据分析、机器人技术和预测模型。
那么,GAN有什么了不起的呢?
生成性对抗网络属于一组生成模型。 这意味着他们的工作是在完全自动化的过程中创建或“生成”新数据的。

lan Goodfellow论文中生成的图像。
地址:https://arxiv.org/abs/1406.2661
顾名思义,GAN实际上由两个相互竞争的独立神经网络组成(以对抗的方式)。其中一个神经网络称为生成器,从随机噪声中生成新的数据实例;另一个神经网络称为鉴别器,它会对这些实例进行真实性评估。换言之,鉴别器决定它检查的每个数据实例是否属于实际的训练数据集。
一个简单的例子
假设你的任务就是高仿一幅著名画作。但不幸的是,你并不知道这位艺术家是谁,也没有见过他的画作。但你的任务就是高仿它,并作为原作之一在拍卖会上展出。
你只有一些颜料和画布。但是拍卖商不希望随意出售作品,所以他们雇了一名侦探来对画作辨别真伪。侦探手中有这幅名作的真迹,所以若是你随意拿出一个作品,侦探立刻就能知道你的画作是赝品(甚至完全不同)。
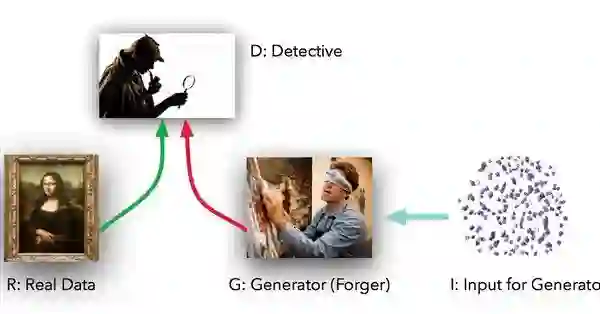
当侦探拒绝了一次之后,你会再去创作一个作品。但是通过这次经验,你会通过侦探得到一些提示(这些提示有关真迹画作应该是什么样子)。
当你再次尝试的时候,画作会比第一次好一些。此时,侦探还是不相信这是真迹,于是你在又得到一些提示的情况下,再次尝试,以此类推。直到你画了1000次,侦探拿着你的高仿作品,已然不知道哪幅画是真迹了。
GAN的工作流程是什么?
将上述的思维过程应用于神经网络组合,GAN的训练过程包括以下步骤:
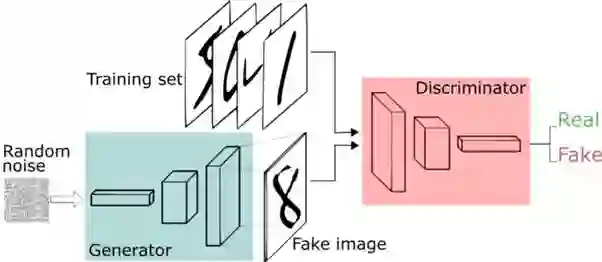
GAN的基本框架。
地址:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394
最开始,发生器接收一些随机噪声并将其传递给鉴别器;
因为鉴别器已经访问了真实图像的数据集,所以它将这些真实数据集与从生成器接收到的图像进行比较,并评估其真实性;
由于初始图像只是随机噪声,它将被评估为“假”;
生成器通过不断改变参数,开始生成更好的图像;
随着训练的进行,生成假图像的生成器和检测它们的鉴别器会变得越发的智能;
最后,生成器设法创建一个与真实图像数据集中的图像难以区分的图像。此时,鉴别器便无法分辨给定的图像是真还是假;
此时,训练结束,生成的图像就是我们想要的最终结果。

我们自己的GAN生成汽车标志图像的过程。
现在,让我们来看一下代码吧!
下面是用Pytorch实现的一个基本生成网络:
1import argparse
2import os
3import numpy as np
4import math
5
6import torchvision.transforms as transforms
7from torchvision.utils import save_image
8
9from torch.utils.data import DataLoader
10from torchvision import datasets
11from torch.autograd import Variable
12
13import torch.nn as nn
14import torch.nn.functional as F
15import torch
16
17os.makedirs('images', exist_ok=True)
18
19parser = argparse.ArgumentParser()
20parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
21parser.add_argument('--batch_size', type=int, default=64, help='size of the batches')
22parser.add_argument('--lr', type=float, default=0.0002, help='adam: learning rate')
23parser.add_argument('--b1', type=float, default=0.5, help='adam: decay of first order momentum of gradient')
24parser.add_argument('--b2', type=float, default=0.999, help='adam: decay of first order momentum of gradient')
25parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
26parser.add_argument('--latent_dim', type=int, default=100, help='dimensionality of the latent space')
27parser.add_argument('--img_size', type=int, default=28, help='size of each image dimension')
28parser.add_argument('--channels', type=int, default=1, help='number of image channels')
29parser.add_argument('--sample_interval', type=int, default=400, help='interval betwen image samples')
30opt = parser.parse_args()
31print(opt)
32
33img_shape = (opt.channels, opt.img_size, opt.img_size)
34
35cuda = True if torch.cuda.is_available() else False
36
37class Generator(nn.Module):
38 def __init__(self):
39 super(Generator, self).__init__()
40
41 def block(in_feat, out_feat, normalize=True):
42 layers = [nn.Linear(in_feat, out_feat)]
43 if normalize:
44 layers.append(nn.BatchNorm1d(out_feat, 0.8))
45 layers.append(nn.LeakyReLU(0.2, inplace=True))
46 return layers
47
48 self.model = nn.Sequential(
49 *block(opt.latent_dim, 128, normalize=False),
50 *block(128, 256),
51 *block(256, 512),
52 *block(512, 1024),
53 nn.Linear(1024, int(np.prod(img_shape))),
54 nn.Tanh()
55 )
56
57 def forward(self, z):
58 img = self.model(z)
59 img = img.view(img.size(0), *img_shape)
60 return img
61
62class Discriminator(nn.Module):
63 def __init__(self):
64 super(Discriminator, self).__init__()
65
66 self.model = nn.Sequential(
67 nn.Linear(int(np.prod(img_shape)), 512),
68 nn.LeakyReLU(0.2, inplace=True),
69 nn.Linear(512, 256),
70 nn.LeakyReLU(0.2, inplace=True),
71 nn.Linear(256, 1),
72 nn.Sigmoid()
73 )
74
75 def forward(self, img):
76 img_flat = img.view(img.size(0), -1)
77 validity = self.model(img_flat)
78
79 return validity
80
81# Loss function
82adversarial_loss = torch.nn.BCELoss()
83
84# Initialize generator and discriminator
85generator = Generator()
86discriminator = Discriminator()
87
88if cuda:
89 generator.cuda()
90 discriminator.cuda()
91 adversarial_loss.cuda()
92
93# Configure data loader
94os.makedirs('../../data/mnist', exist_ok=True)
95dataloader = torch.utils.data.DataLoader(
96 datasets.MNIST('../../data/mnist', train=True, download=True,
97 transform=transforms.Compose([
98 transforms.ToTensor(),
99 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
100 ])),
101 batch_size=opt.batch_size, shuffle=True)
102
103# Optimizers
104optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
105optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
106
107Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
108
109# ----------
110# Training
111# ----------
112
113for epoch in range(opt.n_epochs):
114 for i, (imgs, _) in enumerate(dataloader):
115
116 # Adversarial ground truths
117 valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
118 fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
119
120 # Configure input
121 real_imgs = Variable(imgs.type(Tensor))
122
123 # -----------------
124 # Train Generator
125 # -----------------
126
127 optimizer_G.zero_grad()
128
129 # Sample noise as generator input
130 z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
131
132 # Generate a batch of images
133 gen_imgs = generator(z)
134
135 # Loss measures generator's ability to fool the discriminator
136 g_loss = adversarial_loss(discriminator(gen_imgs), valid)
137
138 g_loss.backward()
139 optimizer_G.step()
140
141 # ---------------------
142 # Train Discriminator
143 # ---------------------
144
145 optimizer_D.zero_grad()
146
147 # Measure discriminator's ability to classify real from generated samples
148 real_loss = adversarial_loss(discriminator(real_imgs), valid)
149 fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
150 d_loss = (real_loss + fake_loss) / 2
151
152 d_loss.backward()
153 optimizer_D.step()
154
155 print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, opt.n_epochs, i, len(dataloader),
156 d_loss.item(), g_loss.item()))
157
158 batches_done = epoch * len(dataloader) + i
159 if batches_done % opt.sample_interval == 0:
160 save_image(gen_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)
优点和缺点
与其它技术一样,GAN也有自身的优缺点。
下面是GAN的一些潜在优势:
GAN并不总是需要带标签的样本来训练;
它们更容易训练依赖于蒙特卡罗(Monte Carlo)近似的对数分割函数梯度的生成模型。 由于蒙特卡罗方法在高维空间中不能很好地工作,这样的生成模型不能很好地执行像使用ImageNet进行训练的现实任务。
他们没有引入任何确定性偏差。 像变分自动编码器这样的某些生成方法会引入确定性偏差,因为它们优化了对数似然的下界,而不是似然本身。
同样,GAN也有它的缺点:
GAN特别难训练。这些网络试图优化的函数是一个本质上没有封闭形式的损失函数。因此,优化这一损失函数是非常困难的,需要在网络结构和训练协议方面进行大量的反复试验;
(特别是)对于图像生成,没有适当的措施来评估准确性。 由于合成图像可以通过计算机本身来实现,因此实际结果是一个非常主观的主题,并且取决于人类观察者。 相反,我们有起始分数和Frechet初始距离等功能来衡量他们的表现。
GAN的应用
最有趣的部分来了!
我们可以用GAN做的所有惊人的东西。 在它所有潜在用途中,GAN已经在计算机视觉领域中实现了大量应用。
文本-图像转换
这个概念有许多实验的方法,例如TAC-GAN(文本条件辅助分类器生成对抗网络)。
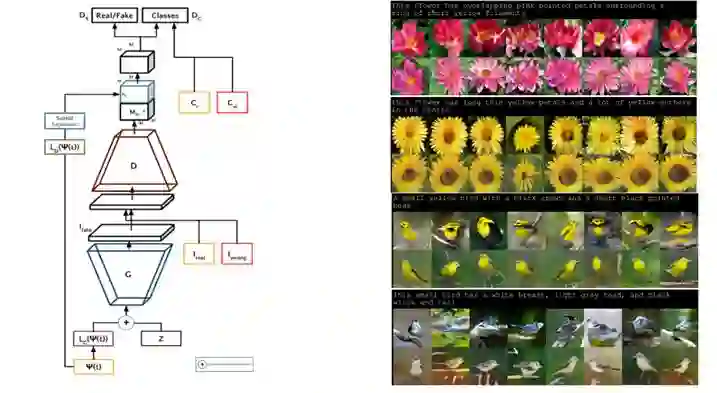
左:TAC-GAN的结构示意图。右:将一行文本输入网络所产生的结果。
域迁移(Domain Transfer)
GAN在风格转换等概念中很受欢迎。请看下面的视频:
它包括使用称为CGAN(条件生成对抗网络)的特殊类型的GAN进行图像到图像的转换。
绘画和概念设计从未如此简单。
然而,虽然GAN可以从它的草图中完成像钱包这样简单的绘图,但绘制更复杂的东西,如完美的人脸,目前还不是GAN的强项。

CGAN pix2pix的实验结果
Image Inpaintinng(图像修复)/Image Outpainting(图像拓展)
生成网络的两个非常激动人心的应用是:图像修复(Inpainting)和图像拓展(Outpainting)。
第一种包括在图像中填充或噪声,这可以看作是图像的修复。例如,给定一个残缺的图像,GAN能够以“passable”的方式对其进行纠正它。
另一方面,图像拓展涉及到使用网络自身的学习来想象一个图像在当前边界之外可能会是什么样子。

左:图像修复结果;右:图像拓展结果。
人脸合成
由于生成网络的存在,使得人脸合成成为了可能,这涉及到从不同角度生成单个人脸图像。
这就是为什么面部识别不需要数百个人脸样本,只需要用一个样本就能识别出来的原因。
不仅如此,生成“人造人脸”也变得可能。 NVIDIA最近使用他们的GAN 2.0在Celeba Hq数据集上生成了高清分辨率的人造人脸,这是高分辨率合成图像生成的第一个例子。

用Progressive GAN生成想象中的名人面孔。
GANimation
GAN使得诸如改变面部运动这样的事情也成为可能。GANimation是一项使用PyTorch的研究成果,它将自己定义为“从一张图像中提取具有解剖学意义的面部动画”。

GANimation官方实现。
地址:https://www.albertpumarola.com/research/GANimation/index.html
绘画-照片转换
利用GAN使图像变得更逼真的另一个例子是简单地将绘画变成照片。
这是使用称为CycleGAN的特殊类型的GAN完成的,它使用两个发生器和两个鉴别器。
我们把一个发生器称为G,它把图像从X域转换成Y域。另一个生成器称为F,它将图像从Y转换为X。每个生成器都有一个对应的鉴别器,该鉴别器试图将其合成的图像与真实图像区分开来。

CycleGAN的结果。
地址:https://github.com/junyanz/CycleGAN
GAN是一把双刃剑
机器学习和GAN肯定会在不久的将来对成像和摄影产生巨大影响。
目前,该技术能够从文本输入生成简单图像。 然而,在可预见的未来,它不仅能够创建高分辨率的精确图像,还能够创建完整的视频。
想象一下,只需要简单地将脚本输入到GAN中,便可以生成一部电影。 不仅如此,每个人都可以使用简单的交互式应用程序来创建自己的电影(甚至可以自己主演!)。
当然,技术是一把双刃剑。
若是这么好的技术被坏人利用,后果是不堪设想的。完美的假图像还需要一种方法来识别和检测它们,我们需要对这类图像的产生进行管制。
目前,GAN已经被用于制作虚假视频或“Deepfakes”,这些视频正以消极的方式被使用着,例如生成名人假的不良视频或让人们在不知情的情况下“被发表言论”。
音频、视频合成技术使用不良手段造成传播后的结果将是非常可怕的。
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得


